Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Azure HDInsight is a managed, full-spectrum, open-source analytics service in the cloud for enterprises. With HDInsight, you can use open-source frameworks such as, Apache Spark, Apache Hive, LLAP, Apache Kafka, Hadoop and more, in your Azure environment.
What is HDInsight and the Hadoop technology stack?
Azure HDInsight is a managed cluster platform that makes it easy to run big data frameworks like Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Hadoop, and others in your Azure environment. It's designed to handle large volumes of data with high speed and efficiency.
Why should I use Azure HDInsight?
| Capability | Description |
|---|---|
| Cloud native | Azure HDInsight enables you to create optimized clusters for Spark, Interactive query (LLAP), Kafka, HBase and Hadoop on Azure. HDInsight also provides an end-to-end SLA on all your production workloads. |
| Low-cost and scalable | HDInsight enables you to scale workloads up or down. You can reduce costs by creating clusters on demand and paying only for what you use. You can also build data pipelines to operationalize your jobs. Decoupled compute and storage provide better performance and flexibility. |
| Secure and compliant | HDInsight enables you to protect your enterprise data assets with Azure Virtual Network, encryption, and integration with Microsoft Entra ID. HDInsight also meets the most popular industry and government compliance standards. |
| Monitoring | Azure HDInsight integrates with Azure Monitor logs to provide a single interface with which you can monitor all your clusters. |
| Global availability | HDInsight is available in more regions than any other big data analytics offering. Azure HDInsight is also available in Azure Government, China, and Germany, which allows you to meet your enterprise needs in key sovereign areas. |
| Productivity | Azure HDInsight enables you to use rich productive tools for Hadoop and Spark with your preferred development environments. These development environments include Visual Studio, VS Code, Eclipse, and IntelliJ for Scala, Python, Java, and .NET support. |
| Extensibility | You can extend the HDInsight clusters with installed components (Hue, Presto, and so on) by using script actions, by adding edge nodes, or by integrating with other big data certified applications. HDInsight enables seamless integration with the most popular big data solutions with a one-click deployment. |
What is big data?
Big data is collected in escalating volumes, at higher velocities, and in a greater variety of formats than ever before. It can be historical (meaning stored) or real time (meaning streamed from the source). See Scenarios for using HDInsight to learn about the most common use cases for big data.
Cluster types in HDInsight
HDInsight includes specific cluster types and cluster customization capabilities, such as the capability to add components, utilities, and languages. HDInsight offers the following cluster types:
| Cluster Type | Description | Get Started |
|---|---|---|
| Apache Hadoop | A framework that uses HDFS, YARN resource management, and a simple MapReduce programming model to process and analyze batch data in parallel. | Create an Apache Hadoop cluster |
| Apache Spark | An open-source, parallel-processing framework that supports in-memory processing to boost the performance of big-data analysis applications. See What is Apache Spark in HDInsight?. | Create an Apache Spark cluster |
| Apache HBase | A NoSQL database built on Hadoop that provides random access and strong consistency for large amounts of unstructured and semi-structured data--potentially billions of rows times millions of columns. See What is HBase on HDInsight? | Create an Apache HBase cluster |
| Apache Interactive Query | In-memory caching for interactive and faster Hive queries. See Use Interactive Query in HDInsight. | Create an Interactive Query cluster |
| Apache Kafka | An open-source platform is used for building streaming data pipelines and applications. Kafka also provides message-queue functionality that allows you to publish and subscribe to data streams. See Introduction to Apache Kafka on HDInsight. | Create an Apache Kafka cluster |
Scenarios for using HDInsight
Azure HDInsight can be used for various scenarios in big data processing. It can be historical data (data that is already collected and stored) or real-time data (data that is directly streamed from the source). The scenarios for processing such data can be summarized in the following categories:
Batch processing (ETL)
Extract, transform, and load (ETL) is a process where unstructured or structured data is extracted from heterogeneous data sources. It's then transformed into a structured format and loaded into a data store. You can use the transformed data for data science or data warehousing.
Data warehousing
You can use HDInsight to perform interactive queries at petabyte scales over structured or unstructured data in any format. You can also build models connecting them to BI tools.

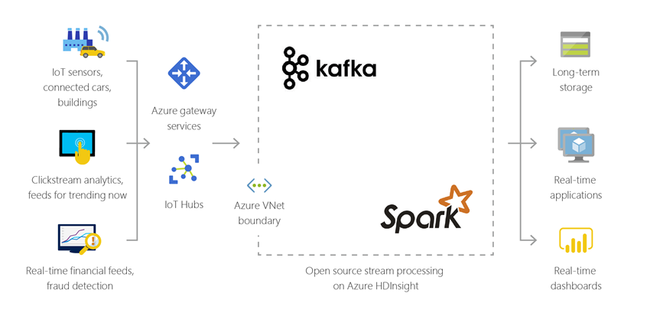
Internet of Things (IoT)
You can use HDInsight to process streaming data that is received in real time from different kinds of devices. For more information, read this blog post from Azure that announces the public preview of Apache Kafka on HDInsight with Azure Managed disks.
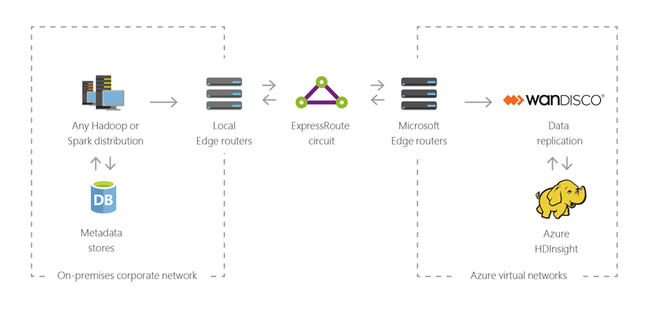
Hybrid
You can use HDInsight to extend your existing on-premises big data infrastructure to Azure to apply the advanced analytics capabilities of the cloud.
Open-source components in HDInsight
Azure HDInsight enables you to create clusters with open-source frameworks such as Spark, Hive, LLAP, Kafka, Hadoop and HBase. By default, these clusters include various open-source components such as Apache Ambari, Avro, Apache Hive 3, HCatalog, Apache Hadoop MapReduce, Apache Hadoop YARN, Apache Phoenix, Apache Pig, Apache Sqoop, Apache Tez, Apache Oozie, and Apache ZooKeeper.
Programming languages in HDInsight
HDInsight clusters, including Spark, HBase, Kafka, Hadoop, and others, support many programming languages. Some programming languages aren't installed by default. For libraries, modules, or packages that aren't installed by default, use a script action to install the component.
| Programming language | Information |
|---|---|
| Default programming language support | By default, HDInsight clusters support:
|
| Java virtual machine (JVM) languages | Many languages other than Java can run on a Java virtual machine (JVM). However, if you run some of these languages, you might have to install more components on the cluster. The following JVM-based languages are supported on HDInsight clusters:
|
| Hadoop-specific languages | HDInsight clusters support the following languages that are specific to the Hadoop technology stack:
|
Development tools for HDInsight
You can use HDInsight development tools, including IntelliJ, Eclipse, Visual Studio Code, and Visual Studio, to author and submit HDInsight data query and job with seamless integration with Azure.
- Azure toolkit for IntelliJ 10
- Azure toolkit for Eclipse 6
- Azure HDInsight tools for VS Code 13
- Azure data lake tools for Visual Studio 9
Business intelligence on HDInsight
Familiar business intelligence (BI) tools retrieve, analyze, and report data that is integrated with HDInsight by using either the Power Query add-in or the Microsoft Hive ODBC Driver:
Apache Spark BI using data visualization tools with Azure HDInsight
Visualize Apache Hive data with Microsoft Power BI in Azure HDInsight
Visualize Interactive Query Hive data with Power BI in Azure HDInsight
Connect Excel to Apache Hadoop with Power Query (requires Windows)
Connect Excel to Apache Hadoop with the Microsoft Hive ODBC Driver (requires Windows)
In-region data residency
Spark, Hadoop, and LLAP don't store customer data, so these services automatically satisfy in-region data residency requirements specified in the Azure global infrastructure site.
Kafka and HBase do store customer data. This data is automatically stored by Kafka and HBase in a single region, so this service satisfies in-region data residency requirements specified in the Azure global infrastructure site.
Familiar business intelligence (BI) tools retrieve, analyze, and report data that is integrated with HDInsight by using either the Power Query add-in or the Microsoft Hive ODBC Driver.