Quickstart: Create Apache Kafka cluster in Azure HDInsight using ARM template
In this quickstart, you use an Azure Resource Manager template (ARM template) to create an Apache Kafka cluster in Azure HDInsight. Kafka is an open-source, distributed streaming platform. It's often used as a message broker, as it provides functionality similar to a publish-subscribe message queue.
An Azure Resource Manager template is a JavaScript Object Notation (JSON) file that defines the infrastructure and configuration for your project. The template uses declarative syntax. You describe your intended deployment without writing the sequence of programming commands to create the deployment.
The Kafka API can only be accessed by resources inside the same virtual network. In this quickstart, you access the cluster directly using SSH. To connect other services, networks, or virtual machines to Kafka, you must first create a virtual network and then create the resources within the network. For more information, see the Connect to Apache Kafka using a virtual network document.
If your environment meets the prerequisites and you're familiar with using ARM templates, select the Deploy to Azure button. The template will open in the Azure portal.

Prerequisites
If you don't have an Azure subscription, create a free account before you begin.
Review the template
The template used in this quickstart is from Azure Quickstart Templates.
{
"$schema": "https://schema.management.azure.com/schemas/2019-04-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"metadata": {
"_generator": {
"name": "bicep",
"version": "0.26.54.24096",
"templateHash": "14433491779040889275"
}
},
"parameters": {
"clusterName": {
"type": "string",
"metadata": {
"description": "The name of the Kafka cluster to create. This must be a unique name."
}
},
"clusterLoginUserName": {
"type": "string",
"metadata": {
"description": "These credentials can be used to submit jobs to the cluster and to log into cluster dashboards."
}
},
"clusterLoginPassword": {
"type": "securestring",
"minLength": 10,
"metadata": {
"description": "The password must be at least 10 characters in length and must contain at least one digit, one upper case letter, one lower case letter, and one non-alphanumeric character except (single-quote, double-quote, backslash, right-bracket, full-stop). Also, the password must not contain 3 consecutive characters from the cluster username or SSH username."
}
},
"sshUserName": {
"type": "string",
"metadata": {
"description": "These credentials can be used to remotely access the cluster."
}
},
"sshPassword": {
"type": "securestring",
"minLength": 6,
"maxLength": 72,
"metadata": {
"description": "SSH password must be 6-72 characters long and must contain at least one digit, one upper case letter, and one lower case letter. It must not contain any 3 consecutive characters from the cluster login name"
}
},
"location": {
"type": "string",
"defaultValue": "[resourceGroup().location]",
"metadata": {
"description": "Location for all resources."
}
},
"HeadNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E4_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the headnode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
},
"WorkerNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E4_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the worerdnode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
},
"ZookeeperNodeVirtualMachineSize": {
"type": "string",
"defaultValue": "Standard_E4_v3",
"allowedValues": [
"Standard_A4_v2",
"Standard_A8_v2",
"Standard_E2_v3",
"Standard_E4_v3",
"Standard_E8_v3",
"Standard_E16_v3",
"Standard_E20_v3",
"Standard_E32_v3",
"Standard_E48_v3"
],
"metadata": {
"description": "This is the Zookeepernode Azure Virtual Machine size, and will affect the cost. If you don't know, just leave the default value."
}
}
},
"variables": {
"defaultStorageAccount": {
"name": "[uniqueString(resourceGroup().id)]",
"type": "Standard_LRS"
}
},
"resources": [
{
"type": "Microsoft.Storage/storageAccounts",
"apiVersion": "2023-01-01",
"name": "[variables('defaultStorageAccount').name]",
"location": "[parameters('location')]",
"sku": {
"name": "[variables('defaultStorageAccount').type]"
},
"kind": "StorageV2",
"properties": {
"minimumTlsVersion": "TLS1_2",
"supportsHttpsTrafficOnly": true,
"allowBlobPublicAccess": false
}
},
{
"type": "Microsoft.HDInsight/clusters",
"apiVersion": "2023-08-15-preview",
"name": "[parameters('clusterName')]",
"location": "[parameters('location')]",
"properties": {
"clusterVersion": "4.0",
"osType": "Linux",
"clusterDefinition": {
"kind": "kafka",
"configurations": {
"gateway": {
"restAuthCredential.isEnabled": true,
"restAuthCredential.username": "[parameters('clusterLoginUserName')]",
"restAuthCredential.password": "[parameters('clusterLoginPassword')]"
}
}
},
"storageProfile": {
"storageaccounts": [
{
"name": "[replace(replace(concat(reference(resourceId('Microsoft.Storage/storageAccounts', variables('defaultStorageAccount').name), '2021-08-01').primaryEndpoints.blob), 'https:', ''), '/', '')]",
"isDefault": true,
"container": "[parameters('clusterName')]",
"key": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', variables('defaultStorageAccount').name), '2021-08-01').keys[0].value]"
}
]
},
"computeProfile": {
"roles": [
{
"name": "headnode",
"targetInstanceCount": 2,
"hardwareProfile": {
"vmSize": "[parameters('HeadNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
},
{
"name": "workernode",
"targetInstanceCount": 4,
"hardwareProfile": {
"vmSize": "[parameters('WorkerNodeVirtualMachineSize')]"
},
"dataDisksGroups": [
{
"disksPerNode": 2
}
],
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
},
{
"name": "zookeepernode",
"targetInstanceCount": 3,
"hardwareProfile": {
"vmSize": "[parameters('ZookeeperNodeVirtualMachineSize')]"
},
"osProfile": {
"linuxOperatingSystemProfile": {
"username": "[parameters('sshUserName')]",
"password": "[parameters('sshPassword')]"
}
}
}
]
}
},
"dependsOn": [
"[resourceId('Microsoft.Storage/storageAccounts', variables('defaultStorageAccount').name)]"
]
}
],
"outputs": {
"name": {
"type": "string",
"value": "[parameters('clusterName')]"
},
"resourceId": {
"type": "string",
"value": "[resourceId('Microsoft.HDInsight/clusters', parameters('clusterName'))]"
},
"cluster": {
"type": "object",
"value": "[reference(resourceId('Microsoft.HDInsight/clusters', parameters('clusterName')), '2023-08-15-preview')]"
},
"resourceGroupName": {
"type": "string",
"value": "[resourceGroup().name]"
},
"location": {
"type": "string",
"value": "[parameters('location')]"
}
}
}
Two Azure resources are defined in the template:
- Microsoft.Storage/storageAccounts: create an Azure Storage Account.
- Microsoft.HDInsight/cluster: create an HDInsight cluster.
Deploy the template
Select the Deploy to Azure button below to sign in to Azure and open the ARM template.
Enter or select the following values:
Property Description Subscription From the drop-down list, select the Azure subscription that's used for the cluster. Resource group From the drop-down list, select your existing resource group, or select Create new. Location The value will autopopulate with the location used for the resource group. Cluster Name Enter a globally unique name. For this template, use only lowercase letters, and numbers. Cluster Login User Name Provide the username, default is admin.Cluster Login Password Provide a password. The password must be at least 10 characters in length and must contain at least one digit, one uppercase, and one lower case letter, one non-alphanumeric character (except characters ' ` ").Ssh User Name Provide the username, default is sshuser.Ssh Password Provide the password. 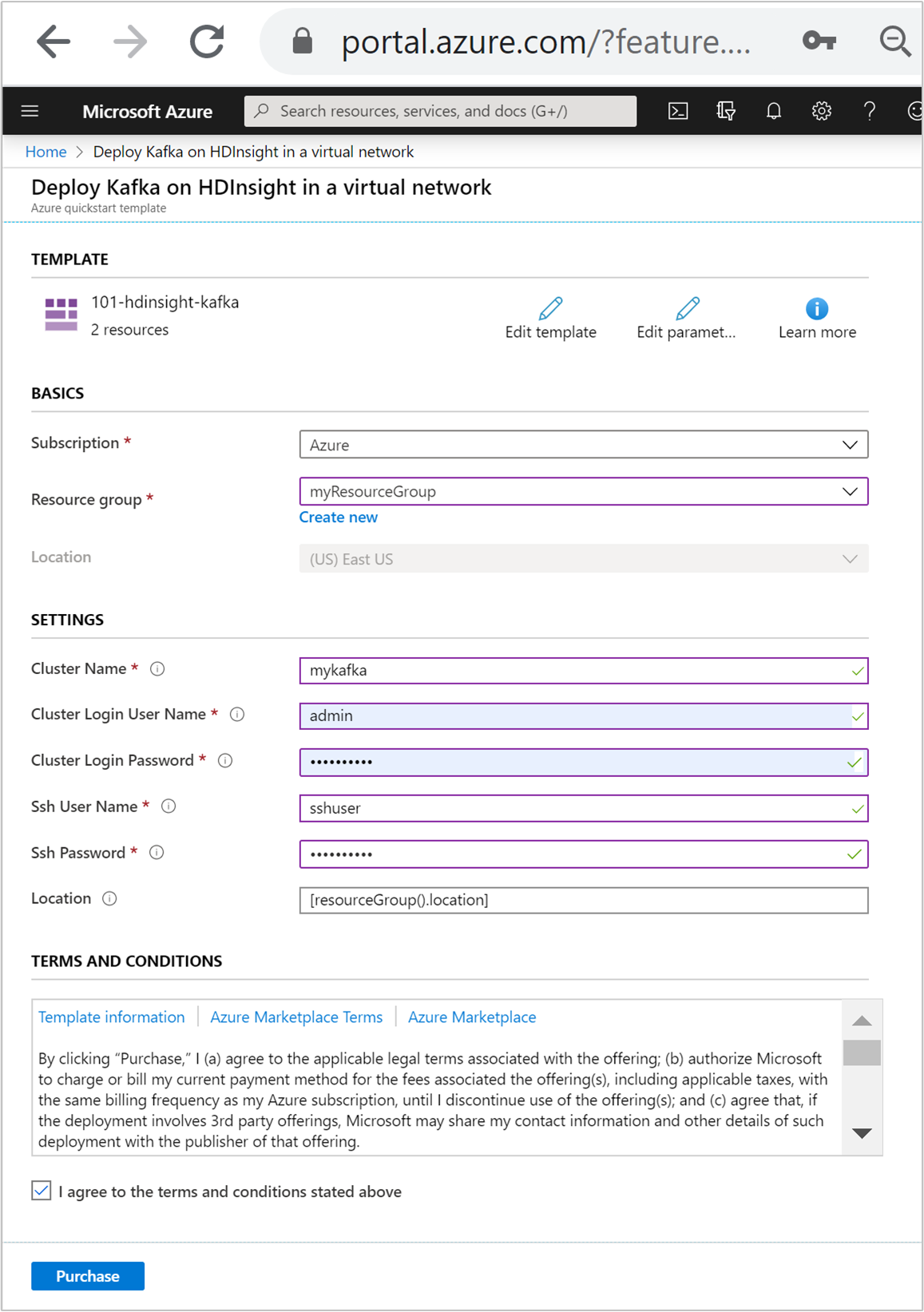
Review the TERMS AND CONDITIONS. Then select I agree to the terms and conditions stated above, then Purchase. You'll receive a notification that your deployment is in progress. It takes about 20 minutes to create a cluster.
Review deployed resources
Once the cluster is created, you'll receive a Deployment succeeded notification with a Go to resource link. Your Resource group page will list your new HDInsight cluster and the default storage associated with the cluster. Each cluster has an Azure Blob Storage account, or an Azure Data Lake Storage Gen2 dependency. It's referred as the default storage account. The HDInsight cluster and its default storage account must be colocated in the same Azure region. Deleting clusters doesn't delete the storage account.
Get the Apache Zookeeper and Broker host information
When working with Kafka, you must know the Apache Zookeeper and Broker hosts. These hosts are used with the Kafka API and many of the utilities that ship with Kafka.
In this section, you get the host information from the Ambari REST API on the cluster.
Use ssh command to connect to your cluster. Edit the command below by replacing CLUSTERNAME with the name of your cluster, and then enter the command:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netFrom the SSH connection, use the following command to install the
jqutility. This utility is used to parse JSON documents, and is useful in retrieving the host information:sudo apt -y install jqTo set an environment variable to the cluster name, use the following command:
read -p "Enter the Kafka on HDInsight cluster name: " CLUSTERNAMEWhen prompted, enter the name of the Kafka cluster.
To set an environment variable with Zookeeper host information, use the command below. The command retrieves all Zookeeper hosts, then returns only the first two entries. This is because you want some redundancy in case one host is unreachable.
export KAFKAZKHOSTS=`curl -sS -u admin -G https://$CLUSTERNAME.azurehdinsight.net/api/v1/clusters/$CLUSTERNAME/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["\(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2`When prompted, enter the password for the cluster login account (not the SSH account).
To verify that the environment variable is set correctly, use the following command:
echo '$KAFKAZKHOSTS='$KAFKAZKHOSTSThis command returns information similar to the following text:
<zookeepername1>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181,<zookeepername2>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181To set an environment variable with Kafka broker host information, use the following command:
export KAFKABROKERS=`curl -sS -u admin -G https://$CLUSTERNAME.azurehdinsight.net/api/v1/clusters/$CLUSTERNAME/services/KAFKA/components/KAFKA_BROKER | jq -r '["\(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2`When prompted, enter the password for the cluster login account (not the SSH account).
To verify that the environment variable is set correctly, use the following command:
echo '$KAFKABROKERS='$KAFKABROKERSThis command returns information similar to the following text:
<brokername1>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092,<brokername2>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
Manage Apache Kafka topics
Kafka stores streams of data in topics. You can use the kafka-topics.sh utility to manage topics.
To create a topic, use the following command in the SSH connection:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic test --zookeeper $KAFKAZKHOSTSThis command connects to Zookeeper using the host information stored in
$KAFKAZKHOSTS. It then creates a Kafka topic named test.Data stored in this topic is partitioned across eight partitions.
Each partition is replicated across three worker nodes in the cluster.
If you created the cluster in an Azure region that provides three fault domains, use a replication factor of 3. Otherwise, use a replication factor of 4.
In regions with three fault domains, a replication factor of 3 allows replicas to be spread across the fault domains. In regions with two fault domains, a replication factor of four spreads the replicas evenly across the domains.
For information on the number of fault domains in a region, see the Availability of Linux virtual machines document.
Kafka isn't aware of Azure fault domains. When you create partition replicas for topics, it may not distribute replicas properly for high availability.
To ensure high availability, use the Apache Kafka partition rebalance tool. This tool must be ran from an SSH connection to the head node of your Kafka cluster.
For the highest availability of your Kafka data, you should rebalance the partition replicas for your topic when:
You create a new topic or partition
You scale up a cluster
To list topics, use the following command:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --zookeeper $KAFKAZKHOSTSThis command lists the topics available on the Kafka cluster.
To delete a topic, use the following command:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic topicname --zookeeper $KAFKAZKHOSTSThis command deletes the topic named
topicname.Warning
If you delete the
testtopic created earlier, then you must recreate it. It is used by steps later in this document.
For more information on the commands available with the kafka-topics.sh utility, use the following command:
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh
Produce and consume records
Kafka stores records in topics. Records are produced by producers, and consumed by consumers. Producers and consumers communicate with the Kafka broker service. Each worker node in your HDInsight cluster is a Kafka broker host.
To store records into the test topic you created earlier, and then read them using a consumer, use the following steps:
To write records to the topic, use the
kafka-console-producer.shutility from the SSH connection:/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $KAFKABROKERS --topic testAfter this command, you arrive at an empty line.
Type a text message on the empty line and hit enter. Enter a few messages this way, and then use Ctrl + C to return to the normal prompt. Each line is sent as a separate record to the Kafka topic.
To read records from the topic, use the
kafka-console-consumer.shutility from the SSH connection:/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKABROKERS --topic test --from-beginningThis command retrieves the records from the topic and displays them. Using
--from-beginningtells the consumer to start from the beginning of the stream, so all records are retrieved.If you're using an older version of Kafka, replace
--bootstrap-server $KAFKABROKERSwith--zookeeper $KAFKAZKHOSTS.Use Ctrl + C to stop the consumer.
You can also programmatically create producers and consumers. For an example of using this API, see the Apache Kafka Producer and Consumer API with HDInsight document.
Clean up resources
After you complete the quickstart, you may want to delete the cluster. With HDInsight, your data is stored in Azure Storage, so you can safely delete a cluster when it isn't in use. You're also charged for an HDInsight cluster, even when it isn't in use. Since the charges for the cluster are many times more than the charges for storage, it makes economic sense to delete clusters when they aren't in use.
From the Azure portal, navigate to your cluster, and select Delete.
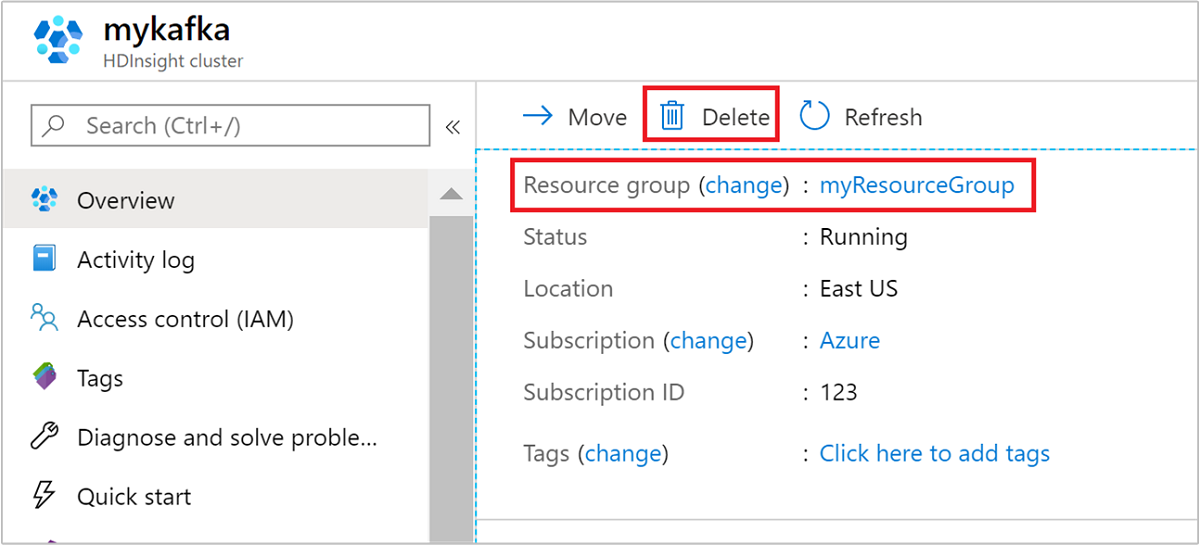
You can also select the resource group name to open the resource group page, and then select Delete resource group. By deleting the resource group, you delete both the HDInsight cluster, and the default storage account.
Next steps
In this quickstart, you learned how to create an Apache Kafka cluster in HDInsight using an ARM template. In the next article, you learn how to create an application that uses the Apache Kafka Streams API and run it with Kafka on HDInsight.