Troubleshoot Apache Spark by using Azure HDInsight
Article
Learn about the top issues and their resolutions when working with Apache Spark payloads in Apache Ambari.
How do I configure an Apache Spark application by using Apache Ambari on clusters?
Spark configuration values can be tuned help avoid an Apache Spark application OutofMemoryError exception. The following steps show default Spark configuration values in Azure HDInsight:
Log in to Ambari at https://CLUSTERNAME.azurehdidnsight.net with your cluster credentials. The initial screen displays an overview dashboard. There are slight cosmetic differences between HDInsight 4.0.
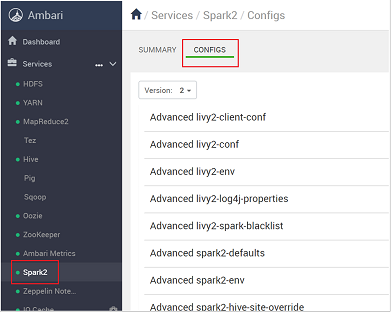
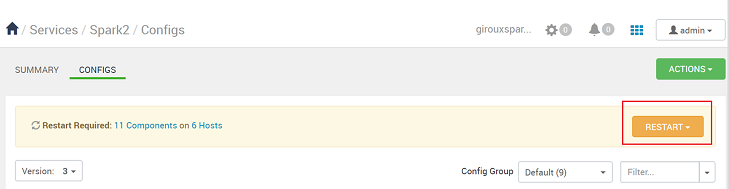
Navigate to Spark2 > Configs.
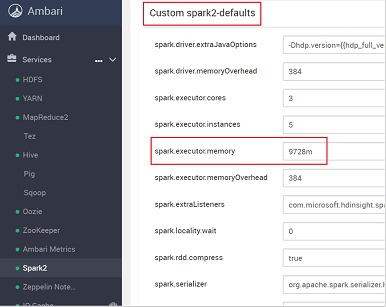
In the list of configurations, select and expand Custom-spark2-defaults.
Look for the value setting that you need to adjust, such as spark.executor.memory. In this case, the value of 9728m is too high.
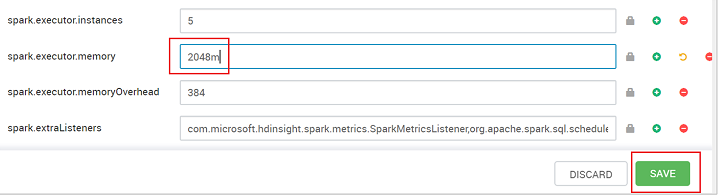
Set the value to the recommended setting. The value 2048m is recommended for this setting.
Save the value, and then save the configuration. Select Save.
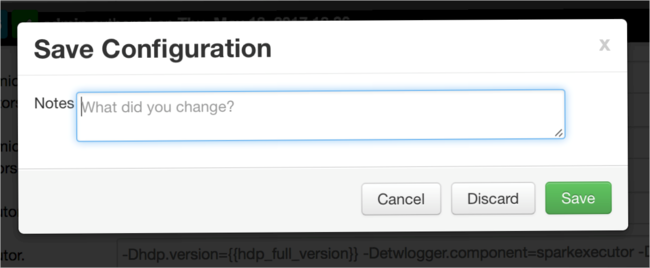
Write a note about the configuration changes, and then select Save.
You're notified if any configurations need attention. Note the items, and then select Proceed Anyway.
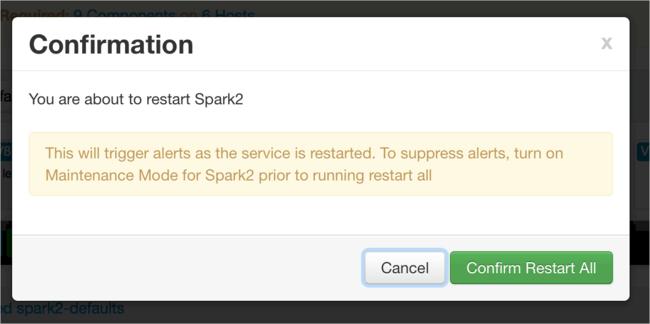
Whenever a configuration is saved, you're prompted to restart the service. Select Restart.
Confirm the restart.
You can review the processes that are running.
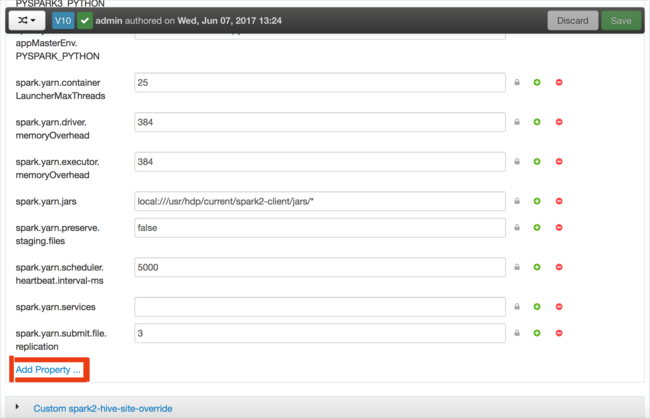
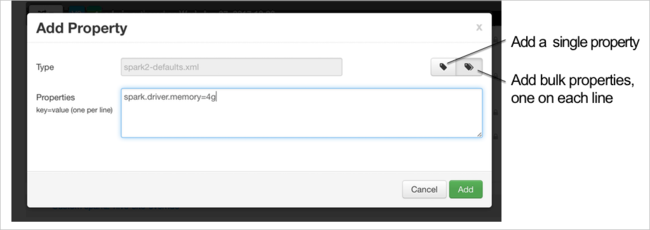
You can add configurations. In the list of configurations, select Custom-spark2-defaults, and then select Add Property.
Define a new property. You can define a single property by using a dialog box for specific settings such as the data type. Or, you can define multiple properties by using one definition per line.
In this example, the spark.driver.memory property is defined with a value of 4g.
Save the configuration, and then restart the service as described in steps 6 and 7.
These changes are cluster-wide but can be overridden when you submit the Spark job.
How do I configure an Apache Spark application by using a Jupyter Notebook on clusters?
In the first cell of the Jupyter Notebook, after the %%configure directive, specify the Spark configurations in valid JSON format. Change the actual values as necessary:
How do I configure an Apache Spark application by using Apache Livy on clusters?
Submit the Spark application to Livy by using a REST client like cURL. Use a command similar to the following. Change the actual values as necessary:
Connect with @AzureSupport - the official Microsoft Azure account for improving customer experience. Connecting the Azure community to the right resources: answers, support, and experts.
If you need more help, you can submit a support request from the Azure portal. Select Support from the menu bar or open the Help + support hub. For more detailed information, review How to create an Azure support request. Access to Subscription Management and billing support is included with your Microsoft Azure subscription, and Technical Support is provided through one of the Azure Support Plans.
Apache Spark is a core technology for large-scale data analytics. Microsoft Fabric provides support for Spark clusters, enabling you to analyze and process data at scale.