Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Learn how to use Apache Pig with HDInsight.
Apache Pig is a platform for creating programs for Apache Hadoop by using a procedural language known as Pig Latin. Pig is an alternative to Java for creating MapReduce solutions, and it's included with Azure HDInsight. Use the following table to discover the various ways that Pig can be used with HDInsight:
Why use Apache Pig
One of the challenges of processing data by using MapReduce in Hadoop is implementing your processing logic by using only a map and a reduce function. For complex processing, you often have to break processing into multiple MapReduce operations that are chained together to achieve the desired result.
Pig allows you to define processing as a series of transformations that the data flows through to produce the desired output.
The Pig Latin language allows you to describe the data flow from raw input, through one or more transformations, to produce the desired output. Pig Latin programs follow this general pattern:
Load: Read data to be manipulated from the file system.
Transform: Manipulate the data.
Dump or store: Output data to the screen or store it for processing.
User-defined functions
Pig Latin also supports user-defined functions (UDF), which allows you to invoke external components that implement logic that is difficult to model in Pig Latin.
For more information about Pig Latin, see Pig Latin Reference Manual 1 and Pig Latin Reference Manual 2.
Example data
HDInsight provides various example data sets, which are stored in the /example/data and /HdiSamples directories. These directories are in the default storage for your cluster. The Pig example in this document uses the Log4j file from /example/data/sample.log.
Each log inside the file consists of a line of fields that contains a [LOG LEVEL] field to show the type and the severity, for example:
2012-02-03 20:26:41 SampleClass3 [ERROR] verbose detail for id 1527353937
In the previous example, the log level is ERROR.
Note
You can also generate a log4j file by using the Apache Log4j logging tool and then upload that file to your blob. See Upload Data to HDInsight for instructions. For more information about how blobs in Azure storage are used with HDInsight, see Use Azure Blob Storage with HDInsight.
Example job
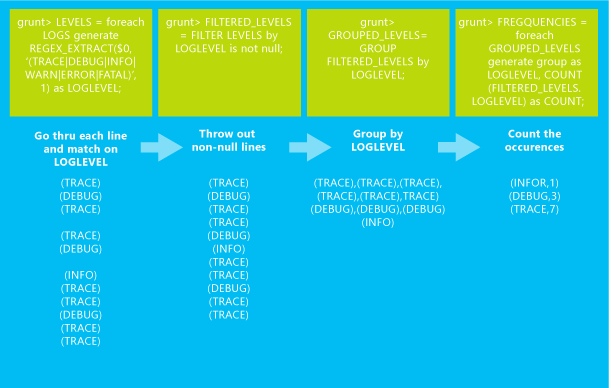
The following Pig Latin job loads the sample.log file from the default storage for your HDInsight cluster. Then it performs a series of transformations that result in a count of how many times each log level occurred in the input data. The results are written to STDOUT.
LOGS = LOAD 'wasb:///example/data/sample.log';
LEVELS = foreach LOGS generate REGEX_EXTRACT($0, '(TRACE|DEBUG|INFO|WARN|ERROR|FATAL)', 1) as LOGLEVEL;
FILTEREDLEVELS = FILTER LEVELS by LOGLEVEL is not null;
GROUPEDLEVELS = GROUP FILTEREDLEVELS by LOGLEVEL;
FREQUENCIES = foreach GROUPEDLEVELS generate group as LOGLEVEL, COUNT(FILTEREDLEVELS.LOGLEVEL) as COUNT;
RESULT = order FREQUENCIES by COUNT desc;
DUMP RESULT;
The following image shows a summary of what each transformation does to the data.
Run the Pig Latin job
HDInsight can run Pig Latin jobs by using various methods. Use the following table to decide which method is right for you, then follow the link for a walkthrough.
Pig and SQL Server Integration Services
You can use SQL Server Integration Services (SSIS) to run a Pig job. The Azure Feature Pack for SSIS provides the following components that work with Pig jobs on HDInsight.
Learn more about the Azure Feature Pack for SSIS here.
Next steps
Now that you have learned how to use Pig with HDInsight, use the following links to explore other ways to work with Azure HDInsight.