Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Health status is an Azure Load Balancer feature that gives detailed health information about the backend instances in your Azure Load Balancer backend pool. Linked to your load balancing rule, this status provides insights into the health state and reasoning of these backend instances.
State of backend instances
Health status exposes the state of your backend instances. There are two state values:
| State | Description |
|---|---|
| Up | This state value represents a healthy backend instance. |
| Down | This state value represents an unhealthy backend instance. |
Reason codes
Health status also exposes reason codes, categorized into User Triggered Reason Codes and Platform Triggered Reason Codes. These codes help you understand the precise reasons for the health probe state of your backend instances and why they're being probed Up or Down.
User Triggered Reason Codes
User triggered reason codes are triggered based on how you configured your Load Balancer; these can be addressed by you, the user. The following tables describe the user-triggered reason codes along with the portal displayed reason for success and failed reason codes.
Success reason codes
The following table describes the success reason codes where the backend state is equal to Up:
| Reason Code | Portal displayed reason | Description |
|---|---|---|
| Up_Probe_Success | The backend instance is responding to health probe successfully. | Your backend instance is responding to the health probe successfully. |
| Up_Probe_AllDownIsUp | The backend instance is considered healthy due to enablement of NoHealthyBackendsBehavior. | Health probe state of the backend instance is ignored because NoHealthyBackendsBehavior is enabled. The backend instance is considered healthy and can receive traffic. |
| Up_Probe_ApproachingUnhealthyThreshold | Health probe is approaching an unhealthy threshold but backend instance remains healthy based on last response. | The most recent probe has failed to respond but the backend instance remains healthy enough based on earlier responses. |
| Up_Admin | The backend instance is healthy due to Admin State set to Up. | Health probe state of the backend instance is ignored because the Admin State is set to UP. The backend instance is considered healthy and can receive traffic. |
Failure reason codes
The following table describes the failure reason codes where the backend state is equal to Down:
| Reason Code | Portal displayed reason | Description |
|---|---|---|
| Down_Probe_ApproachingHealthyThreshold | Health probe is approaching a healthy threshold but backend instance remains unhealthy based on last response. | The most recent probe outcome is positive, but it doesn't meet the required number of responses in the healthy threshold, so the backend instance remains unhealthy. |
| Down_Probe_HttpStatusCodeError | A non-200 HTTP status code received; meaning there's an issue with the application listening on the port. | Your backend instance is returning a non-200 HTTP status code indicating an issue with the application listening on the port. |
| Down_Probe_HttpEndpointUnreachable | HTTP endpoint unreachable; meaning either an NSG rule blocking port or unhealthy app listening on port. | The health probe was able to establish a TCP handshake with your backend instance but the HTTP session was rejected which indicates two possibilities: An NSG rule blocking the port or no healthy application listening on the port. |
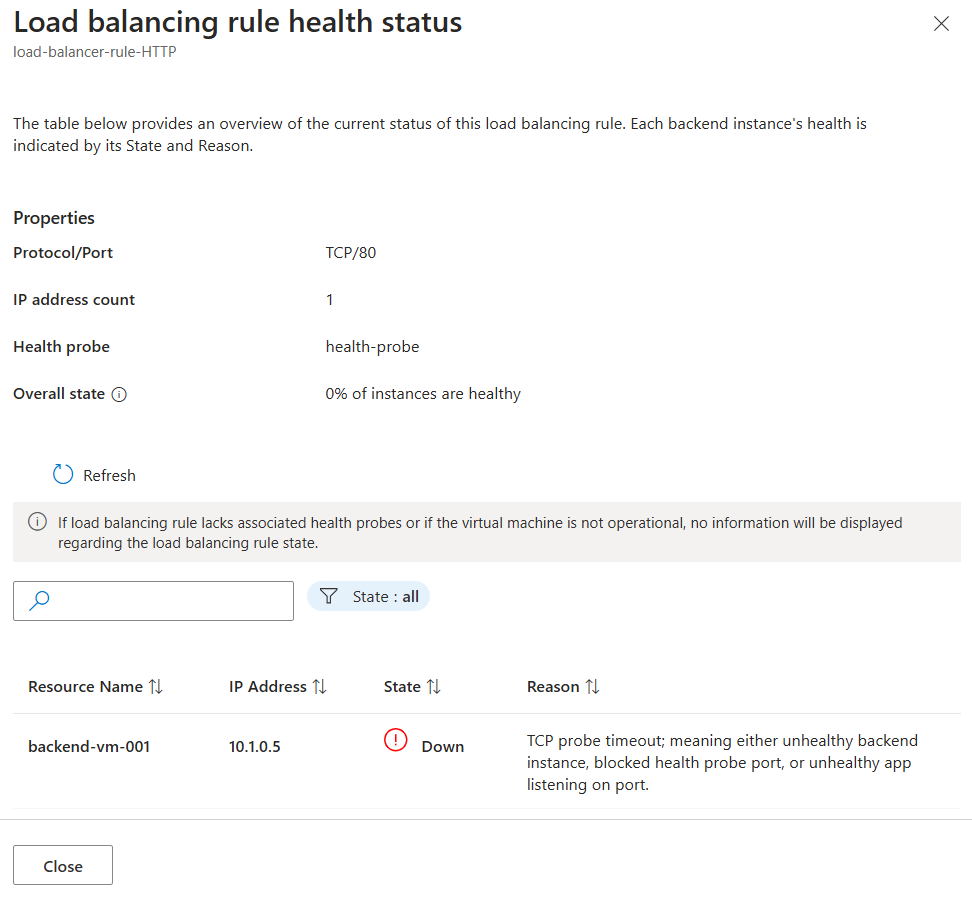
| Down_Probe_TcpProbeTimeout | TCP probe timeout; meaning either unhealthy backend instance, blocked health probe port, or unhealthy app listening on port. | Your backend instance has sent back no TCP response within the probe interval. This indicates three possibilities: An unhealthy Backend Instance, blocked health probe port, or unhealthy application listening on the port. |
| Down_Probe_NoHealthyBackend | No healthy backend instances behind the regional load balancer. | Your regional load balancer that is associated with a Global Load Balancer has no healthy backend instances behind it. |
| Down_Admin | The backend instance is unhealthy due to Admin State set to Down. | Health probe state of the backend instance is ignored because the Admin State is set to Down. The backend instance is considered unhealthy and can't receive new traffic. |
| Down_Probe_HttpNoResponse | Application isn't returning a response. | The health probe was able to establish an HTTP session but the application isn't returning a response. This indicates an unhealthy application listening on the port. |
Note
In rare cases, NA will show as a reason code. This code is shown when the health probe has not probed your backend instance yet so there is no reason code to display.
Platform Triggered reason codes
Platform triggered reason codes are triggered based on the Azure Load Balancer’s platform; these codes can't be addressed by you, the user. The following table below describes each reason code:
| Reason Code | Portal displayed reason | Description |
|---|---|---|
| Up_Platform | The backend instance is responding to the health probe successfully, but there may be an infrastructure related issue. The Azure service team is alerted and will resolve the issue. | The backend instance is responding to the health probe successfully, but there can be an infrastructure related issue. The Azure service team is alerted and will resolve the issue. |
| Down_Platform | The backend instance is unhealthy due to an infrastructure related issue. The Azure service team is alerted and will resolve the issue. | The backend instance is unhealthy due to an infrastructure related issue. The Azure service team is alerted and will resolve the issue. |
How to retrieve health status
Health status can be retrieved on a per load balancing rule basis. This is supported via Azure port and REST API.
Sign in to the Azure portal.
In the search bar, enter Load Balancers and select Load Balancers from the search results.
On the Load Balancers page, select your load balancer from the list.
In your load balancer's Settings section, select Load balancing rules.
In the Load balancing rules page, select View details under the Health status column for the rule you want to view.
Review the health status of your backend instances in the Load balancing rule health status window.
To retrieve the latest health status, select Refresh.
Important
The Load balancing rule health status window may take a few minutes to load the health status of your backend instances.
Select Close to exit the Load balancing rule health status window.