Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article describes how to use the Select Columns Transform component in Azure Machine Learning designer. The purpose of the Select Columns Transform component is to ensure that a predictable, consistent set of columns is used in downstream machine learning operations.
This component is helpful for tasks such as scoring, which require specific columns. Changes in the available columns might break the pipeline or change the results.
You use Select Columns Transform to create and save a set of columns. Then, use the Apply Transformation component to apply those selections to new data.
How to use Select Columns Transform
This scenario assumes that you want to use feature selection to generate a dynamic set of columns that will be used for training a model. To ensure that column selections are the same for the scoring process, you use the Select Columns Transform component to capture the column selections and apply them elsewhere in the pipeline.
Add an input dataset to your pipeline in the designer.
Add an instance of Filter Based Feature Selection.
Connect the components and configure the feature selection component to automatically find a number of best features in the input dataset.
Add an instance of Train Model and use the output of Filter Based Feature Selection as the input for training.
Important
Because feature importance is based on the values in the column, you can't know in advance which columns might be available for input to Train Model.
Attach an instance of the Select Columns Transform component.
This step generates a column selection as a transformation that can be saved or applied to other datasets. This step ensures that the columns identified in feature selection are saved for other components to reuse.
Add the Score Model component.
Do not connect the input dataset. Instead, add the Apply Transformation component, and connect the output of the feature selection transformation.
The pipeline structure should be like following:
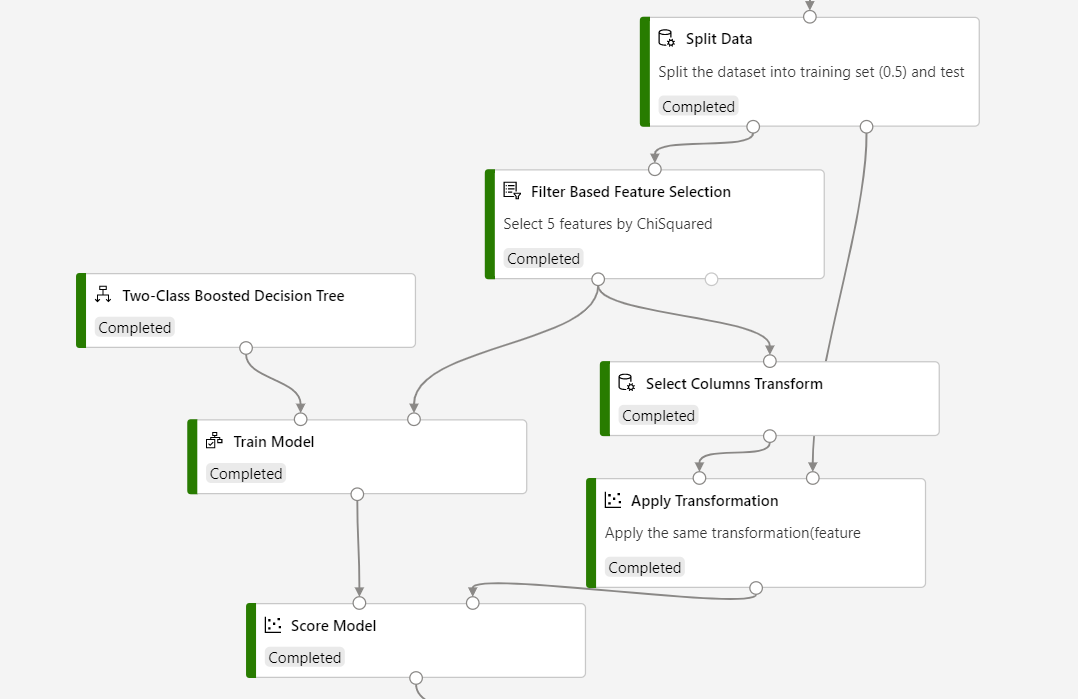
Important
You can't expect to apply Filter Based Feature Selection to the scoring dataset and get the same results. Because feature selection is based on values, it might choose a different set of columns, which would cause the scoring operation to fail.
Submit the pipeline.
This process of saving and then applying a column selection ensures that the same data schema is available for training and scoring.
Next steps
See the set of components available to Azure Machine Learning.