Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
One of the biggest challenges with current model-debugging practices is using aggregate metrics to score models on a benchmark dataset. Model accuracy might not be uniform across subgroups of data, and there might be input cohorts for which the model fails more often. These failures lead to a lack of reliability and safety, the appearance of fairness problems, and a loss of trust in machine learning altogether.

Error analysis moves away from aggregate accuracy metrics. It exposes the distribution of errors to developers in a transparent way, and it enables them to identify and diagnose errors efficiently.
The error analysis component of the Responsible AI dashboard provides machine learning practitioners with a deeper understanding of model failure distribution and helps them quickly identify erroneous cohorts of data. This component identifies the cohorts of data with a higher error rate compared to the overall benchmark error rate. It contributes to the identification stage of the model lifecycle workflow through:
- A decision tree that reveals cohorts with high error rates.
- A heatmap that visualizes how input features affect the error rate across cohorts.
Discrepancies in errors might occur when the system underperforms for specific demographic groups or infrequently observed input cohorts in the training data.
The capabilities of this component come from the Error Analysis package, which generates model error profiles.
Use error analysis when you need to:
- Gain a deep understanding of how model failures are distributed across a dataset and across several input and feature dimensions.
- Break down the aggregate performance metrics to automatically discover erroneous cohorts so you can take targeted mitigation steps.
Error tree
Error patterns are often complex and involve more than one or two features. You might have difficulty exploring all possible combinations of features to discover hidden data pockets with critical failures.
To alleviate the burden, the binary tree visualization automatically partitions the benchmark data into interpretable subgroups that have unexpectedly high or low error rates. In other words, the tree uses the input features to maximally separate model error from success. For each node that defines a data subgroup, you can investigate the following information:
- Error rate: The portion of instances in the node for which the model is incorrect. The visualization shows this value through the intensity of the red color.
- Error coverage: The portion of all errors that fall into the node. The visualization shows this value through the fill rate of the node.
- Data representation: The number of instances in each node of the error tree. The visualization shows this value through the thickness of the incoming edge to the node, along with the total number of instances in the node.

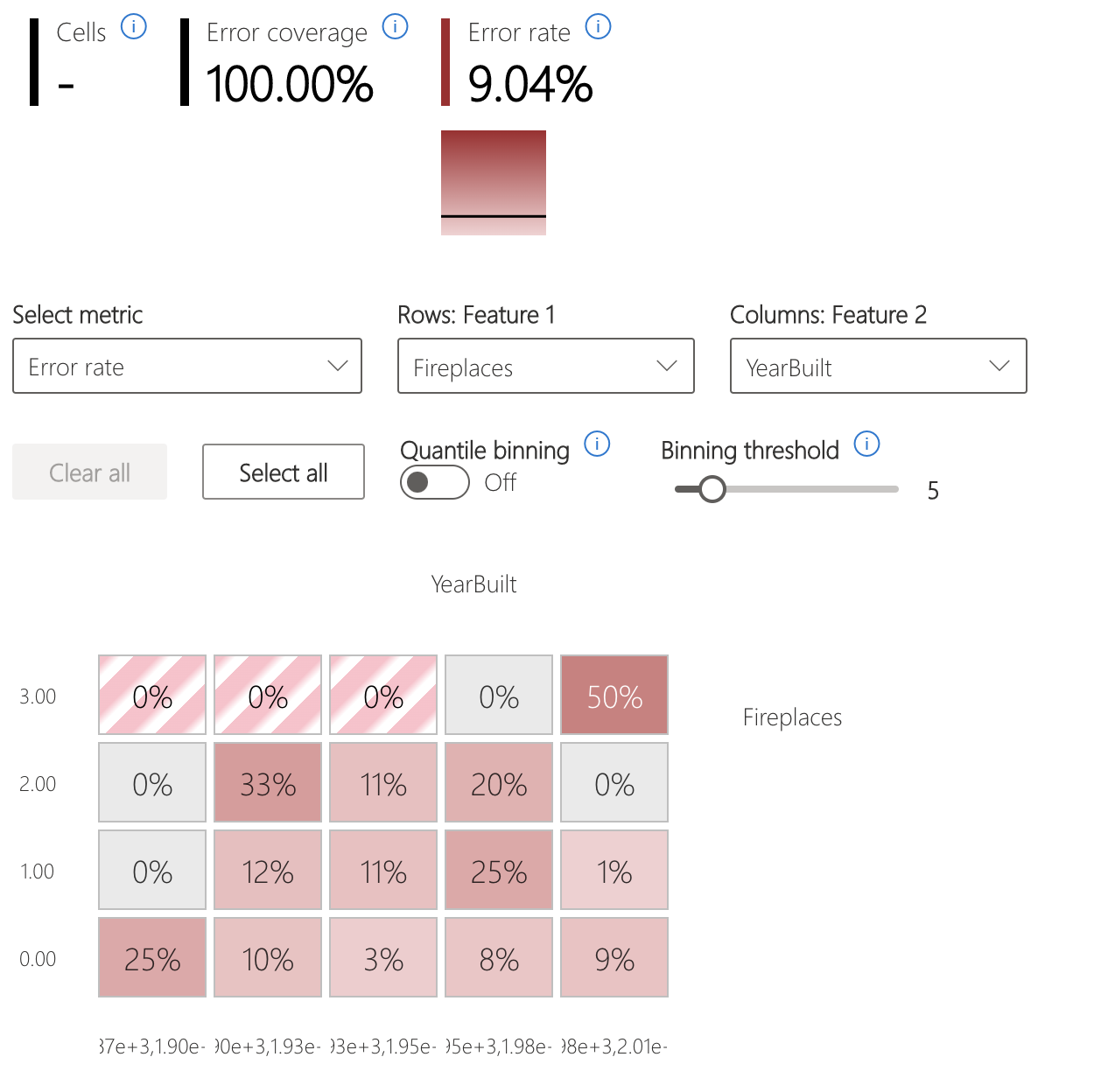
Error heatmap
This view slices the data based on a one-dimensional or two-dimensional grid of input features. You can choose the input features of interest for analysis.
The heatmap visualizes cells with high error by using a darker red color to bring your attention to those regions. This feature is especially beneficial when the error themes are different across partitions, which happens often in practice. In this error identification view, your knowledge or hypotheses guide the analysis and help you understand which features might be most important for understanding failures.
Next steps
- Learn how to generate the Responsible AI dashboard via CLI and SDK or Azure Machine Learning studio UI.
- Explore the supported error analysis visualizations.
- Learn how to generate a Responsible AI scorecard based on the insights observed in the Responsible AI dashboard.