Data ingestion with Azure Data Factory
In this article, you learn about the available options for building a data ingestion pipeline with Azure Data Factory. This Azure Data Factory pipeline is used to ingest data for use with Azure Machine Learning. Data Factory allows you to easily extract, transform, and load (ETL) data. Once the data has been transformed and loaded into storage, it can be used to train your machine learning models in Azure Machine Learning.
Simple data transformation can be handled with native Data Factory activities and instruments such as data flow. When it comes to more complicated scenarios, the data can be processed with some custom code. For example, Python or R code.
Compare Azure Data Factory data ingestion pipelines
There are several common techniques of using Data Factory to transform data during ingestion. Each technique has advantages and disadvantages that help determine if it's a good fit for a specific use case:
| Technique | Advantages | Disadvantages |
|---|---|---|
| Data Factory + Azure Functions | Only good for short running processing | |
| Data Factory + custom component | ||
| Data Factory + Azure Databricks notebook |
Azure Data Factory with Azure functions
Azure Functions allows you to run small pieces of code (functions) without worrying about application infrastructure. In this option, the data is processed with custom Python code wrapped into an Azure Function.
The function is invoked with the Azure Data Factory Azure Function activity. This approach is a good option for lightweight data transformations.
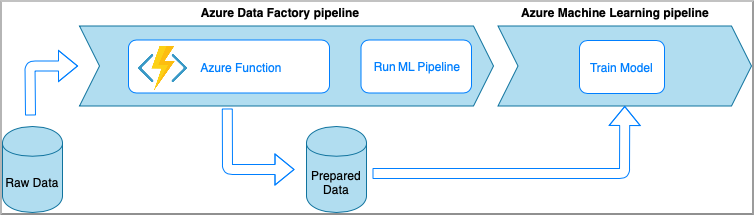
- Advantages:
- The data is processed on a serverless compute with a relatively low latency
- Data Factory pipeline can invoke a Durable Azure Function that may implement a sophisticated data transformation flow
- The details of the data transformation are abstracted away by the Azure Function that can be reused and invoked from other places
- Disadvantages:
- The Azure Functions must be created before use with ADF
- Azure Functions is good only for short running data processing
Azure Data Factory with Custom Component activity
In this option, the data is processed with custom Python code wrapped into an executable. It's invoked with an Azure Data Factory Custom Component activity. This approach is a better fit for large data than the previous technique.
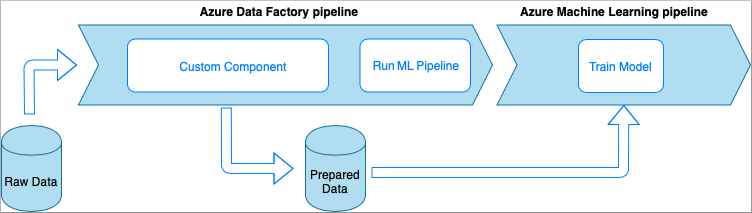
- Advantages:
- The data is processed on Azure Batch pool, which provides large-scale parallel and high-performance computing
- Can be used to run heavy algorithms and process significant amounts of data
- Disadvantages:
- Azure Batch pool must be created before use with Data Factory
- Over engineering related to wrapping Python code into an executable. Complexity of handling dependencies and input/output parameters
Azure Data Factory with Azure Databricks Python notebook
Azure Databricks is an Apache Spark-based analytics platform in the Microsoft cloud.
In this technique, the data transformation is performed by a Python notebook, running on an Azure Databricks cluster. This is probably, the most common approach that uses the full power of an Azure Databricks service. It's designed for distributed data processing at scale.
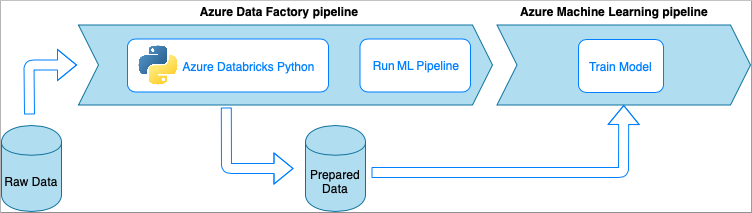
- Advantages:
- The data is transformed on the most powerful data processing Azure service, which is backed up by Apache Spark environment
- Native support of Python along with data science frameworks and libraries including TensorFlow, PyTorch, and scikit-learn
- There's no need to wrap the Python code into functions or executable modules. The code works as is.
- Disadvantages:
- Azure Databricks infrastructure must be created before use with Data Factory
- Can be expensive depending on Azure Databricks configuration
- Spinning up compute clusters from "cold" mode takes some time that brings high latency to the solution
Consume data in Azure Machine Learning
The Data Factory pipeline saves the prepared data to your cloud storage (such as Azure Blob or Azure Data Lake).
Consume your prepared data in Azure Machine Learning by,
- Invoking an Azure Machine Learning pipeline from your Data Factory pipeline.
OR - Creating an Azure Machine Learning datastore.
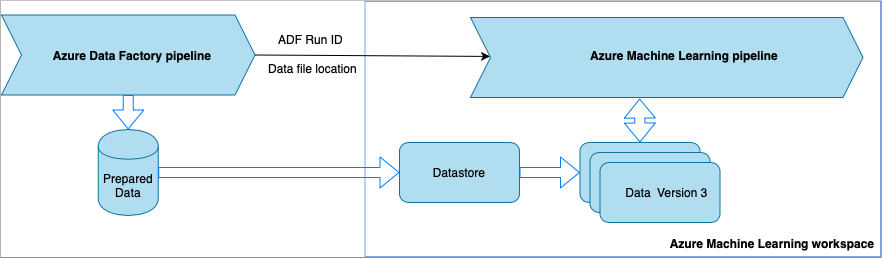
Invoke Azure Machine Learning pipeline from Data Factory
This method is recommended for Machine Learning Operations (MLOps) workflows. If you don't want to set up an Azure Machine Learning pipeline, see Read data directly from storage.
Each time the Data Factory pipeline runs,
- The data is saved to a different location in storage.
- To pass the location to Azure Machine Learning, the Data Factory pipeline calls an Azure Machine Learning pipeline. When calling the ML pipeline, the data location and job ID are sent as parameters.
- The ML pipeline can then create an Azure Machine Learning datastore and dataset with the data location. Learn more in Execute Azure Machine Learning pipelines in Data Factory.
Tip
Datasets support versioning, so the ML pipeline can register a new version of the dataset that points to the most recent data from the ADF pipeline.
Once the data is accessible through a datastore or dataset, you can use it to train an ML model. The training process might be part of the same ML pipeline that is called from ADF. Or it might be a separate process such as experimentation in a Jupyter notebook.
Since datasets support versioning, and each job from the pipeline creates a new version, it's easy to understand which version of the data was used to train a model.
Read data directly from storage
If you don't want to create an ML pipeline, you can access the data directly from the storage account where your prepared data is saved with an Azure Machine Learning datastore and dataset.
The following Python code demonstrates how to create a datastore that connects to Azure DataLake Generation 2 storage. Learn more about datastores and where to find service principal permissions.
APPLIES TO:  Python SDK azureml v1
Python SDK azureml v1
ws = Workspace.from_config()
adlsgen2_datastore_name = '<ADLS gen2 storage account alias>' #set ADLS Gen2 storage account alias in Azure Machine Learning
subscription_id=os.getenv("ADL_SUBSCRIPTION", "<ADLS account subscription ID>") # subscription id of ADLS account
resource_group=os.getenv("ADL_RESOURCE_GROUP", "<ADLS account resource group>") # resource group of ADLS account
account_name=os.getenv("ADLSGEN2_ACCOUNTNAME", "<ADLS account name>") # ADLS Gen2 account name
tenant_id=os.getenv("ADLSGEN2_TENANT", "<tenant id of service principal>") # tenant id of service principal
client_id=os.getenv("ADLSGEN2_CLIENTID", "<client id of service principal>") # client id of service principal
client_secret=os.getenv("ADLSGEN2_CLIENT_SECRET", "<secret of service principal>") # the secret of service principal
adlsgen2_datastore = Datastore.register_azure_data_lake_gen2(
workspace=ws,
datastore_name=adlsgen2_datastore_name,
account_name=account_name, # ADLS Gen2 account name
filesystem='<filesystem name>', # ADLS Gen2 filesystem
tenant_id=tenant_id, # tenant id of service principal
client_id=client_id, # client id of service principal
Next, create a dataset to reference the file(s) you want to use in your machine learning task.
The following code creates a TabularDataset from a csv file, prepared-data.csv. Learn more about dataset types and accepted file formats.
APPLIES TO:
Python SDK azureml v1
from azureml.core import Workspace, Datastore, Dataset
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
# retrieve data via Azure Machine Learning datastore
datastore = Datastore.get(ws, adlsgen2_datastore)
datastore_path = [(datastore, '/data/prepared-data.csv')]
prepared_dataset = Dataset.Tabular.from_delimited_files(path=datastore_path)
From here, use prepared_dataset to reference your prepared data, like in your training scripts. Learn how to Train models with datasets in Azure Machine Learning.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for