Run batch endpoints from Azure Data Factory
APPLIES TO:
 Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Big data requires a service that can orchestrate and operationalize processes to refine these enormous stores of raw data into actionable business insights. Azure Data Factory is a managed cloud service that's built for these complex hybrid extract-transform-load (ETL), extract-load-transform (ELT), and data integration projects.
Azure Data Factory allows the creation of pipelines that can orchestrate multiple data transformations and manage them as a single unit. Batch endpoints are an excellent candidate to become a step in such processing workflow. In this example, learn how to use batch endpoints in Azure Data Factory activities by relying on the Web Invoke activity and the REST API.
Prerequisites
This example assumes that you have a model correctly deployed as a batch endpoint. Particularly, we are using the heart condition classifier created in the tutorial Using MLflow models in batch deployments.
An Azure Data Factory resource created and configured. If you have not created your data factory yet, follow the steps in Quickstart: Create a data factory by using the Azure portal and Azure Data Factory Studio to create one.
After creating it, browse to the data factory in the Azure portal:
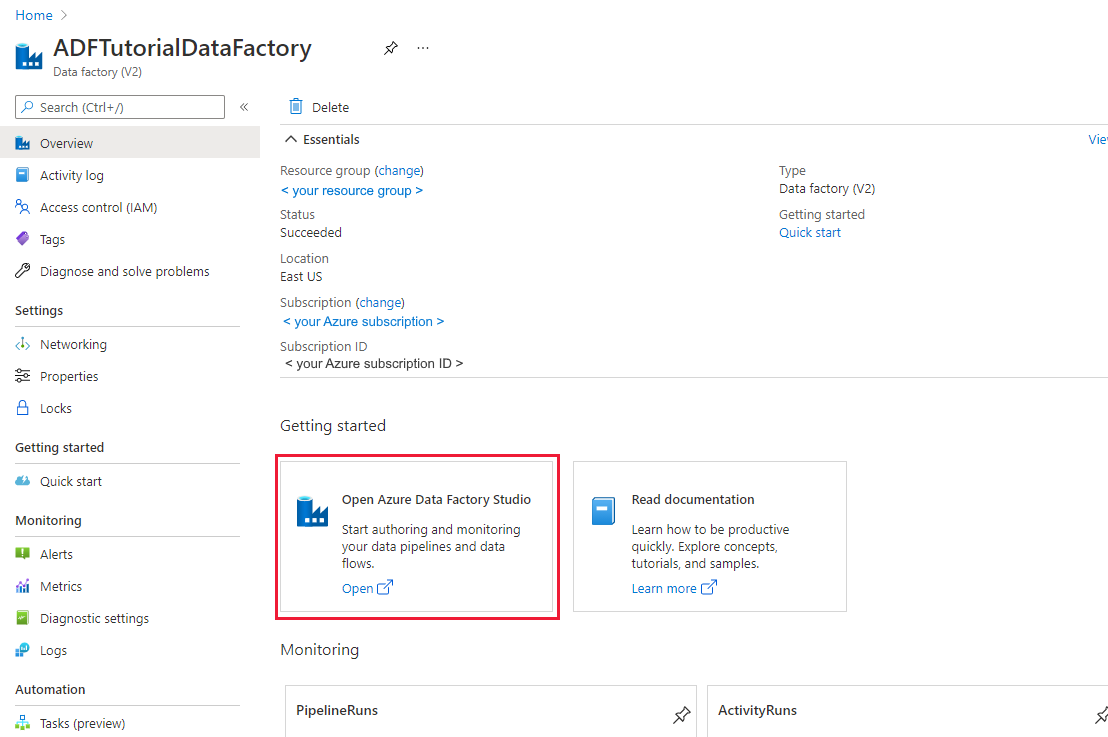
Select Open on the Open Azure Data Factory Studio tile to launch the Data Integration application in a separate tab.
Authenticating against batch endpoints
Azure Data Factory can invoke the REST APIs of batch endpoints by using the Web Invoke activity. Batch endpoints support Microsoft Entra ID for authorization and hence the request made to the APIs require a proper authentication handling.
You can use a service principal or a managed identity to authenticate against Batch Endpoints. We recommend using a managed identity as it simplifies the use of secrets.
You can use Azure Data Factory managed identity to communicate with Batch Endpoints. In this case, you only need to make sure that your Azure Data Factory resource was deployed with a managed identity.
If you don't have an Azure Data Factory resource or it was already deployed without a managed identity, please follow the following steps to create it: Managed identity for Azure Data Factory.
Warning
Notice that changing the resource identity once deployed is not possible in Azure Data Factory. Once the resource is created, you will need to recreate it if you need to change the identity of it.
Once deployed, grant access for the managed identity of the resource you created to your Azure Machine Learning workspace as explained at Grant access. In this example the service principal will require:
- Permission in the workspace to read batch deployments and perform actions over them.
- Permissions to read/write in data stores.
- Permissions to read in any cloud location (storage account) indicated as a data input.
About the pipeline
We are going to create a pipeline in Azure Data Factory that can invoke a given batch endpoint over some data. The pipeline will communicate with Azure Machine Learning batch endpoints using REST. To know more about how to use the REST API of batch endpoints read Create jobs and input data for batch endpoints.
The pipeline will look as follows:
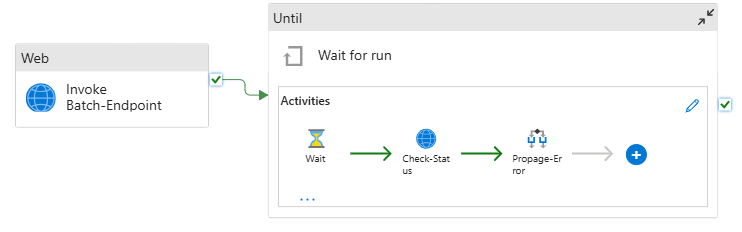
It is composed of the following activities:
- Run Batch-Endpoint: It's a Web Activity that uses the batch endpoint URI to invoke it. It passes the input data URI where the data is located and the expected output file.
- Wait for job: It's a loop activity that checks the status of the created job and waits for its completion, either as Completed or Failed. This activity, in turns, uses the following activities:
- Check status: It's a Web Activity that queries the status of the job resource that was returned as a response of the Run Batch-Endpoint activity.
- Wait: It's a Wait Activity that controls the polling frequency of the job's status. We set a default of 120 (2 minutes).
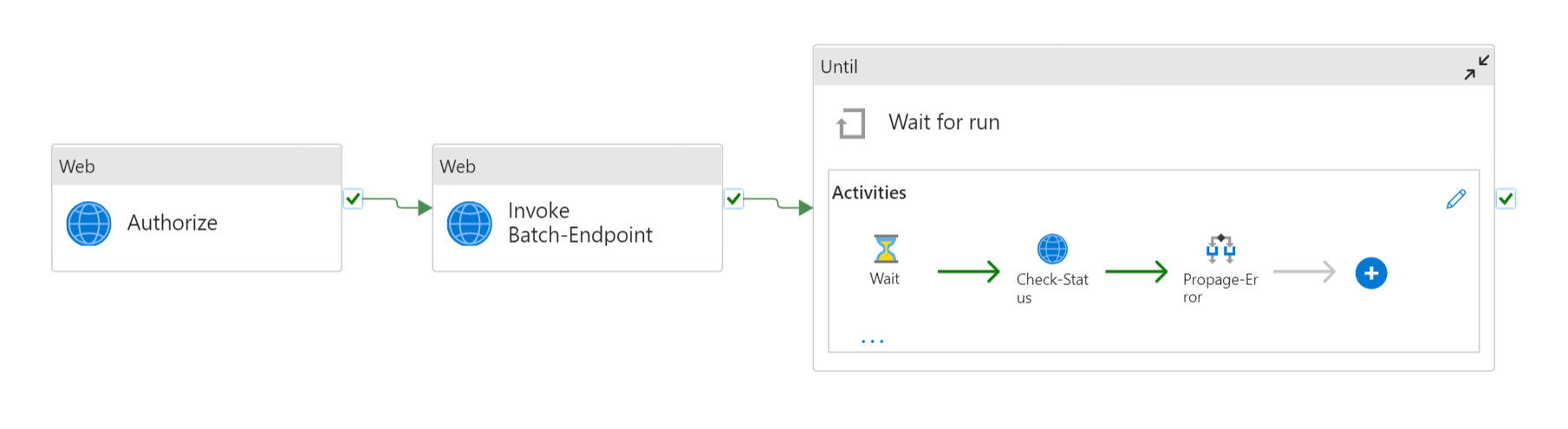
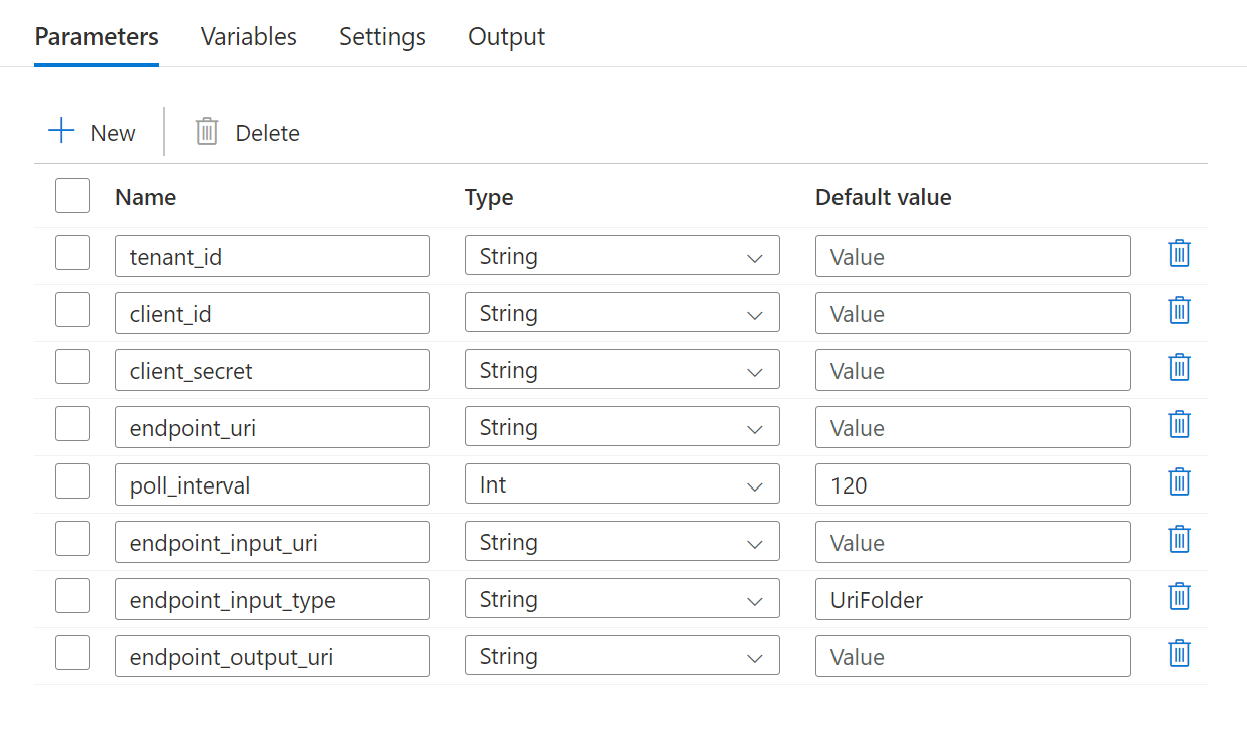
The pipeline requires the following parameters to be configured:
| Parameter | Description | Sample value |
|---|---|---|
endpoint_uri |
The endpoint scoring URI | https://<endpoint_name>.<region>.inference.ml.azure.com/jobs |
poll_interval |
The number of seconds to wait before checking the job status for completion. Defaults to 120. |
120 |
endpoint_input_uri |
The endpoint's input data. Multiple data input types are supported. Ensure that the manage identity you are using for executing the job has access to the underlying location. Alternative, if using Data Stores, ensure the credentials are indicated there. | azureml://datastores/.../paths/.../data/ |
endpoint_input_type |
The type of the input data you are providing. Currently batch endpoints support folders (UriFolder) and File (UriFile). Defaults to UriFolder. |
UriFolder |
endpoint_output_uri |
The endpoint's output data file. It must be a path to an output file in a Data Store attached to the Machine Learning workspace. Not other type of URIs is supported. You can use the default Azure Machine Learning data store, named workspaceblobstore. |
azureml://datastores/workspaceblobstore/paths/batch/predictions.csv |
Warning
Remember that endpoint_output_uri should be the path to a file that doesn't exist yet. Otherwise, the job will fail with the error the path already exists.
Steps
To create this pipeline in your existing Azure Data Factory and invoke batch endpoints, follow these steps:
Ensure the compute where the batch endpoint is running has permissions to mount the data Azure Data Factory is providing as input. Notice that access is still granted by the identity that invokes the endpoint (in this case Azure Data Factory). However, the compute where the batch endpoint runs needs to have permission to mount the storage account your Azure Data Factory provide. See Accessing storage services for details.
Open Azure Data Factory Studio and under Factory Resources click the plus sign.
Select Pipeline > Import from pipeline template
You will be prompted to select a
zipfile. Uses the following template if using managed identities or the following one if using a service principal.A preview of the pipeline will show up in the portal. Click Use this template.
The pipeline will be created for you with the name Run-BatchEndpoint.
Configure the parameters of the batch deployment you are using:
Warning
Ensure that your batch endpoint has a default deployment configured before submitting a job to it. The created pipeline will invoke the endpoint and hence a default deployment needs to be created and configured.
Tip
For best reusability, use the created pipeline as a template and call it from within other Azure Data Factory pipelines by leveraging the Execute pipeline activity. In that case, do not configure the parameters in the inner pipeline but pass them as parameters from the outer pipeline as shown in the following image:
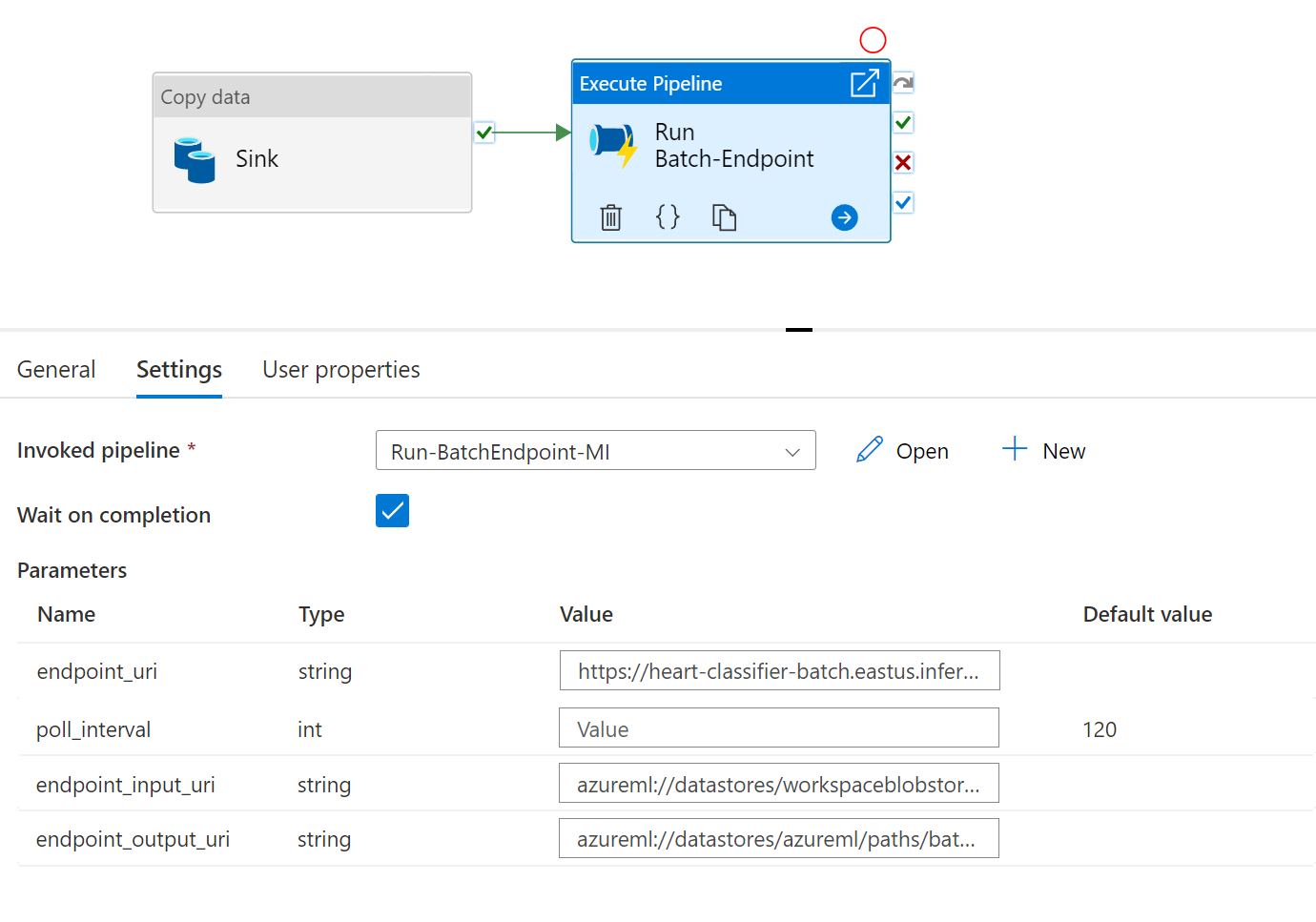
- Your pipeline is ready to be used.
Limitations
When calling Azure Machine Learning batch deployments consider the following limitations:
Data inputs
- Only Azure Machine Learning data stores or Azure Storage Accounts (Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2) are supported as inputs. If your input data is in another source, use the Azure Data Factory Copy activity before the execution of the batch job to sink the data to a compatible store.
- Batch endpoint jobs don't explore nested folders and hence can't work with nested folder structures. If your data is distributed in multiple folders, notice that you will have to flatten the structure.
- Make sure that your scoring script provided in the deployment can handle the data as it is expected to be fed into the job. If the model is MLflow, read the limitation in terms of the file type supported by the moment at Using MLflow models in batch deployments.
Data outputs
- Only registered Azure Machine Learning data stores are supported by the moment. We recommend you to register the storage account your Azure Data Factory is using as a Data Store in Azure Machine Learning. In that way, you will be able to write back to the same storage account from where you are reading.
- Only Azure Blob Storage Accounts are supported for outputs. For instance, Azure Data Lake Storage Gen2 isn't supported as output in batch deployment jobs. If you need to output the data to a different location/sink, use the Azure Data Factory Copy activity after the execution of the batch job.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for