Evaluation flows and metrics
Evaluation flows are a special type of prompt flow that calculates metrics to assess how well the outputs of a run meet specific criteria and goals. You can create or customize evaluation flows and metrics tailored to your tasks and objectives, and use them to evaluate other prompt flows. This article explains evaluation flows, how to develop and customize them, and how to use them in prompt flow batch runs to evaluate flow performance.
Understand evaluation flows
A prompt flow is a sequence of nodes that process input and generate output. Evaluation flows also consume required inputs and produce corresponding outputs that are usually scores or metrics. Evaluation flows differ from standard flows in their authoring experience and usage.
Evaluation flows usually run following the run they're testing by receiving its outputs and using the outputs to calculate scores and metrics. Evaluation flows log metrics by using the prompt flow SDK log_metric() function.
The outputs of the evaluation flow are results that measure the performance of the flow being tested. Evaluation flows can have an aggregation node that calculates the overall performance of the flow being tested over the test dataset.
The next sections describe how to define inputs and outputs in evaluation flows.
Inputs
Evaluation flows calculate metrics or scores for batch runs by taking in the outputs of the run they're testing. For example, if the flow being tested is a QnA flow that generates an answer based on a question, you might name an evaluation input as answer. If the flow being tested is a classification flow that classifies a text into a category, you might name an evaluation input as category.
You might need other inputs as ground truth. For example, if you want to calculate the accuracy of a classification flow, you need to provide the category column of the dataset as ground truth. If you want to calculate the accuracy of a QnA flow, you need to provide the answer column of the dataset as the ground truth. You might need some other inputs to calculate metrics, such as question and context in QnA or retrieval augmented generation (RAG) scenarios.
You define the inputs of the evaluation flow the same way you define the inputs of a standard flow. By default, evaluation uses the same dataset as the run being tested. However, if the corresponding labels or target ground truth values are in a different dataset, you can easily switch to that dataset.
Input descriptions
To describe the inputs needed for calculating metrics, you can add descriptions. The descriptions appear when you map the input sources in batch run submissions.
To add descriptions for each input, select Show description in the input section when developing your evaluation method, and then enter the descriptions.

To hide the descriptions from the input form, select Hide description.

Outputs and metrics
The outputs of an evaluation are results that show the performance of the flow being tested. The output usually contains metrics such as scores, and can also include text for reasoning and suggestions.
Output scores
A prompt flows processes one row of data at a time and generates an output record. Evaluation flows likewise can calculate scores for each row of data, so you can check how a flow performs on each individual data point.
You can record the scores for each data instance as evaluation flow outputs by specifying them in the output section of the evaluation flow. The authoring experience is the same as defining a standard flow output.
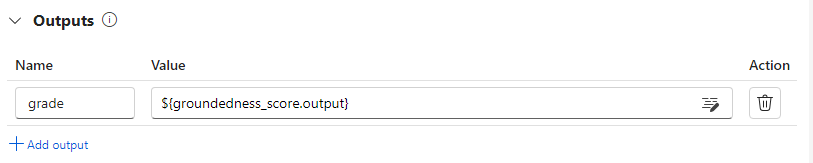
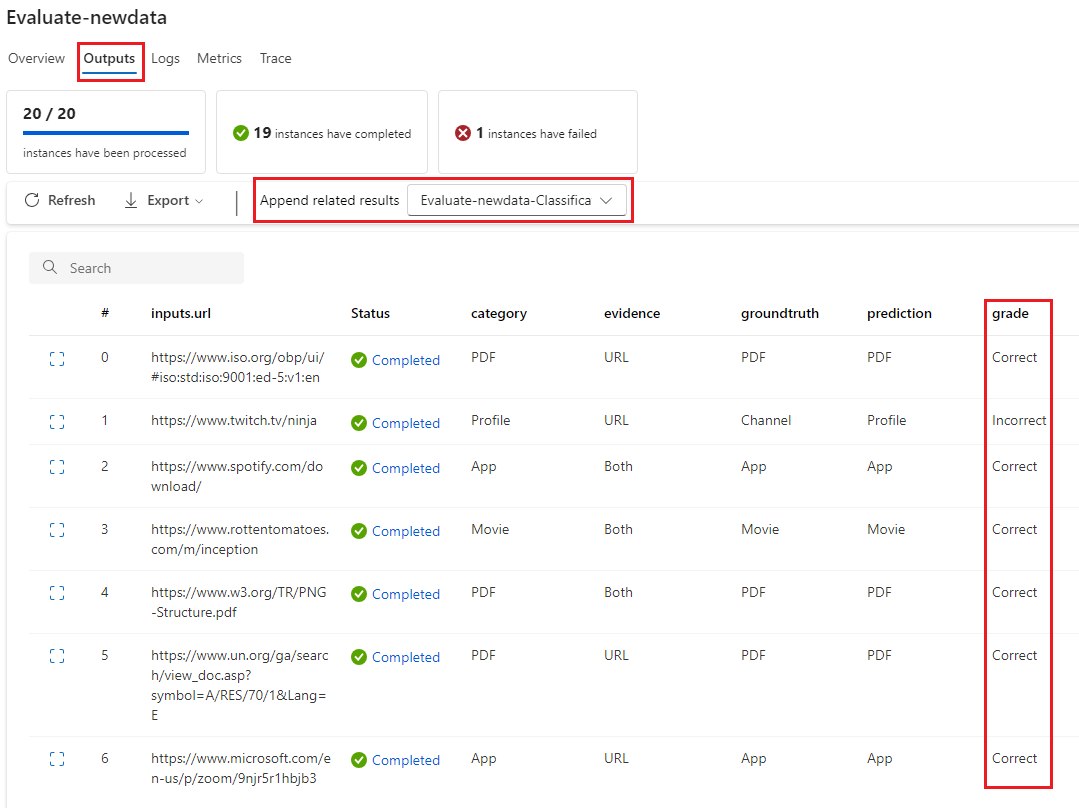
You can view the individual scores in the Outputs tab when you select View outputs, the same as you check the outputs of a standard flow batch run. You can append these instance-level scores to the output of the flow you tested.
Aggregation and metrics logging
The evaluation flow also provides an overall assessment for the run. To distinguish the overall results from individual output scores, these overall run performance values are called metrics.
To calculate an overall assessment value based on individual scores, select the Aggregation checkbox on a Python node in an evaluation flow to turn it into a reduce node. The node then takes in the inputs as a list and processes them as a batch.

By using aggregation, you can calculate and process all the scores of each flow output and compute an overall result by using each score. For example, to calculate the accuracy of a classification flow, you can calculate the accuracy of each score output and then calculate the average accuracy of all the score outputs. Then, you can log the average accuracy as a metric by using promptflow_sdk.log_metric(). Metrics must be numerical, such as float or int. String type metrics logging isn't supported.
The following code snippet is an example of calculating overall accuracy by averaging the accuracy score grades of all data points. The overall accuracy is logged as a metric by using promptflow_sdk.log_metric().
from typing import List
from promptflow import tool, log_metric
@tool
def calculate_accuracy(grades: List[str]): # Receive a list of grades from a previous node
# calculate accuracy
accuracy = round((grades.count("Correct") / len(grades)), 2)
log_metric("accuracy", accuracy)
return accuracy
Because you call this function in the Python node, you don't need to assign it elsewhere, and you can view the metrics later. After you use this evaluation method in a batch run, you can view the metric showing overall performance by selecting the Metrics tab when you view outputs.

Develop an evaluation flow
To develop your own evaluation flow, select Create on the Azure Machine Learning studio Prompt flow page. On the Create a new flow page, you can either:
Select Create on the Evaluation flow card under Create by type. This selection provides a template for developing a new evaluation method.
Select Evaluation flow in the Explore gallery, and select from one of the available built-in flows. Select View details to get a summary of each flow, and select Clone to open and customize the flow. The flow creation wizard helps you modify the flow for your own scenario.

Calculate scores for each data point
Evaluation flows calculate scores and metrics for flows that run on datasets. The first step in evaluation flows is calculating scores for each individual data output.
For example, in the built-in Classification Accuracy Evaluation flow, the grade that measures the accuracy of each flow-generated output to its corresponding ground truth is calculated in the grade Python node.
If you use the evaluation flow template, you calculate this score in the line_process Python node. You can also replace the line_process python node with a large language model (LLM) node to use an LLM to calculate the score, or use multiple nodes to perform the calculation.

You specify the outputs of this node as the outputs of the evaluation flow, which indicates that the outputs are the scores calculated for each data sample. You can also output reasoning for more information, and it's the same experience as defining outputs in a standard flow.
Calculate and log metrics
The next step in evaluation is to calculate overall metrics to assess the run. You calculate metrics in a Python node that has the Aggregation option selected. This node takes in the scores from the previous calculation node and organizes them into a list, then calculates overall values.
If you use the evaluation template, this score is calculated in the aggregate node. The following code snippet shows the template for the aggregation node.
from typing import List
from promptflow import tool
@tool
def aggregate(processed_results: List[str]):
"""
This tool aggregates the processed result of all lines and log metric.
:param processed_results: List of the output of line_process node.
"""
# Add your aggregation logic here
aggregated_results = {}
# Log metric
# from promptflow import log_metric
# log_metric(key="<my-metric-name>", value=aggregated_results["<my-metric-name>"])
return aggregated_results
You can use your own aggregation logic, such as calculating score mean, median, or standard deviation.
Log the metrics by using the promptflow.log_metric() function. You can log multiple metrics in a single evaluation flow. Metrics must be numerical (float/int).
Use evaluation flows
After you create your own evaluation flow and metrics, you can use the flow to assess performance of a standard flow. For example, you can evaluate a QnA flow to test how it performs on a large dataset.
In Azure Machine Learning studio, open the flow that you want to evaluate, and select Evaluate in the top menu bar.

In the Batch run & Evaluate wizard, complete the Basic settings and Batch run settings to load the dataset for testing and configure the input mapping. For more information, see Submit batch run and evaluate a flow.
In the Select evaluation step, you can select one or more of your customized evaluations or built-in evaluations to run. Customized evaluation lists all the evaluation flows that you created, cloned, or customized. Evaluation flows created by others working on the same project don't appear in this section.

On the Configure evaluation screen, specify the sources of any input data needed for the evaluation method. For example, the ground truth column might come from a dataset. If your evaluation method doesn't require data from a dataset, you don't need to select a dataset, or reference any dataset columns in the input mapping section.
In the Evaluation input mapping section, you can indicate the sources of required inputs for the evaluation. If the data source is from your run output, set the source as
${run.outputs.[OutputName]}. If the data is from your test dataset, set the source as${data.[ColumnName]}. Any descriptions you set for the data inputs also appear here. For more information, see Submit batch run and evaluate a flow.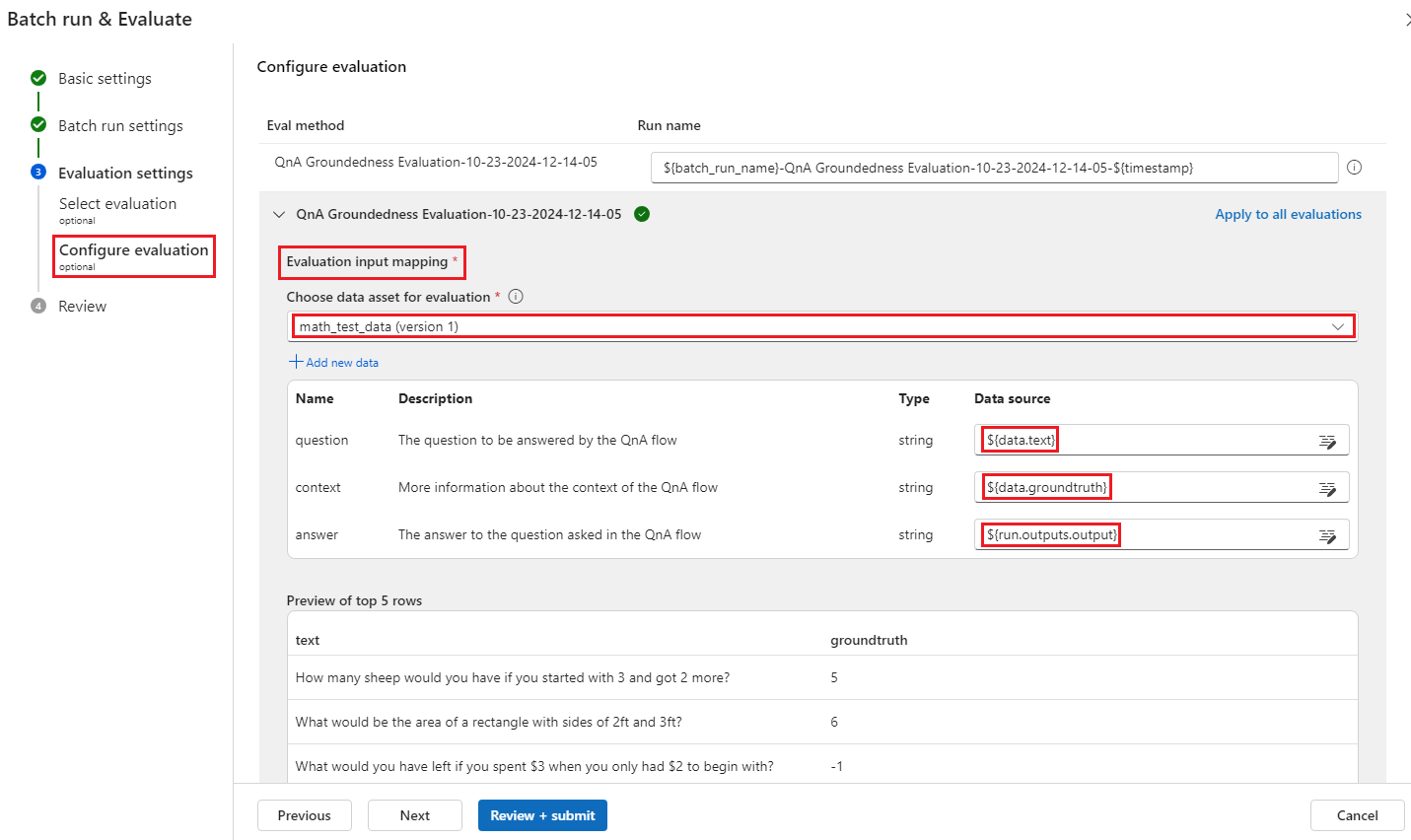
Important
If your evaluation flow has an LLM node or requires a connection to consume credentials or other keys, you must enter the connection data in the Connection section of this screen to be able to use the evaluation flow.
Select Review + submit and then select Submit to run the evaluation flow.
After the evaluation flow completes, you can see the instance-level scores by selecting View batch runs > View latest batch run outputs at the top of the flow you evaluated. Select your evaluation run from the Append related results dropdown list to see the grade for each data row.