Boost Checkpoint Speed and Reduce Cost with Nebula
Learn how to boost checkpoint speed and reduce checkpoint cost for large Azure Machine Learning training models using Nebula.
Overview
Nebula is a fast, simple, disk-less, model-aware checkpoint tool in Azure Container for PyTorch (ACPT). Nebula offers a simple, high-speed checkpointing solution for distributed large-scale model training jobs using PyTorch. By utilizing the latest distributed computing technologies, Nebula can reduce checkpoint times from hours to seconds - potentially saving 95% to 99.9% of time. Large-scale training jobs can greatly benefit from Nebula's performance.
To make Nebula available for your training jobs, import the nebulaml python package in your script. Nebula has full compatibility with different distributed PyTorch training strategies, including PyTorch Lightning, DeepSpeed, and more. The Nebula API offers a simple way to monitor and view checkpoint lifecycles. The APIs support various model types, and ensure checkpoint consistency and reliability.
Important
The nebulaml package is not available on the public PyPI python package index. It is only available in the Azure Container for PyTorch (ACPT) curated environment on Azure Machine Learning. To avoid issues, do not attempt to install nebulaml from PyPI or using the pip command.
In this document, you'll learn how to use Nebula with ACPT on Azure Machine Learning to quickly checkpoint your model training jobs. Additionally, you'll learn how to view and manage Nebula checkpoint data. You'll also learn how to resume the model training jobs from the last available checkpoint if there is interruption, failure or termination of Azure Machine Learning.
Why checkpoint optimization for large model training matters
As data volumes grow and data formats become more complex, machine learning models have also become more sophisticated. Training these complex models can be challenging due to GPU memory capacity limits and lengthy training times. As a result, distributed training is often used when working with large datasets and complex models. However, distributed architectures can experience unexpected faults and node failures, which can become increasingly problematic as the number of nodes in a machine learning model increases.
Checkpoints can help mitigate these issues by periodically saving a snapshot of the complete model state at a given time. In the event of a failure, this snapshot can be used to rebuild the model to its state at the time of the snapshot so that training can resume from that point.
When large model training operations experience failures or terminations, data scientists and researchers can restore the training process from a previously saved checkpoint. However, any progress made between the checkpoint and termination is lost as computations must be re-executed to recover unsaved intermediate results. Shorter checkpoint intervals could help reduce this loss. The diagram illustrates the time wasted between the training process from checkpoints and termination:

However, the process of saving checkpoints itself can generate significant overhead. Saving a TB-sized checkpoint can often become a bottleneck in the training process, with the synchronized checkpoint process blocking training for hours. On average, checkpoint-related overheads can account for 12% of total training time and can rise to as much as 43% (Maeng et al., 2021).
To summarize, large model checkpoint management involves heavy storage, and job recovery time overheads. Frequent checkpoint saves, combined with training job resumptions from the latest available checkpoints, become a great challenge.
Nebula to the Rescue
To effectively train large distributed models, it is important to have a reliable and efficient way to save and resume training progress that minimizes data loss and waste of resources. Nebula helps reduce checkpoint save times and GPU hour demands for large model Azure Machine Learning training jobs by providing faster and easier checkpoint management.
With Nebula you can:
Boost checkpoint speeds by up to 1000 times with a simple API that works asynchronously with your training process. Nebula can reduce checkpoint times from hours to seconds - a potential reduction of 95% to 99%.
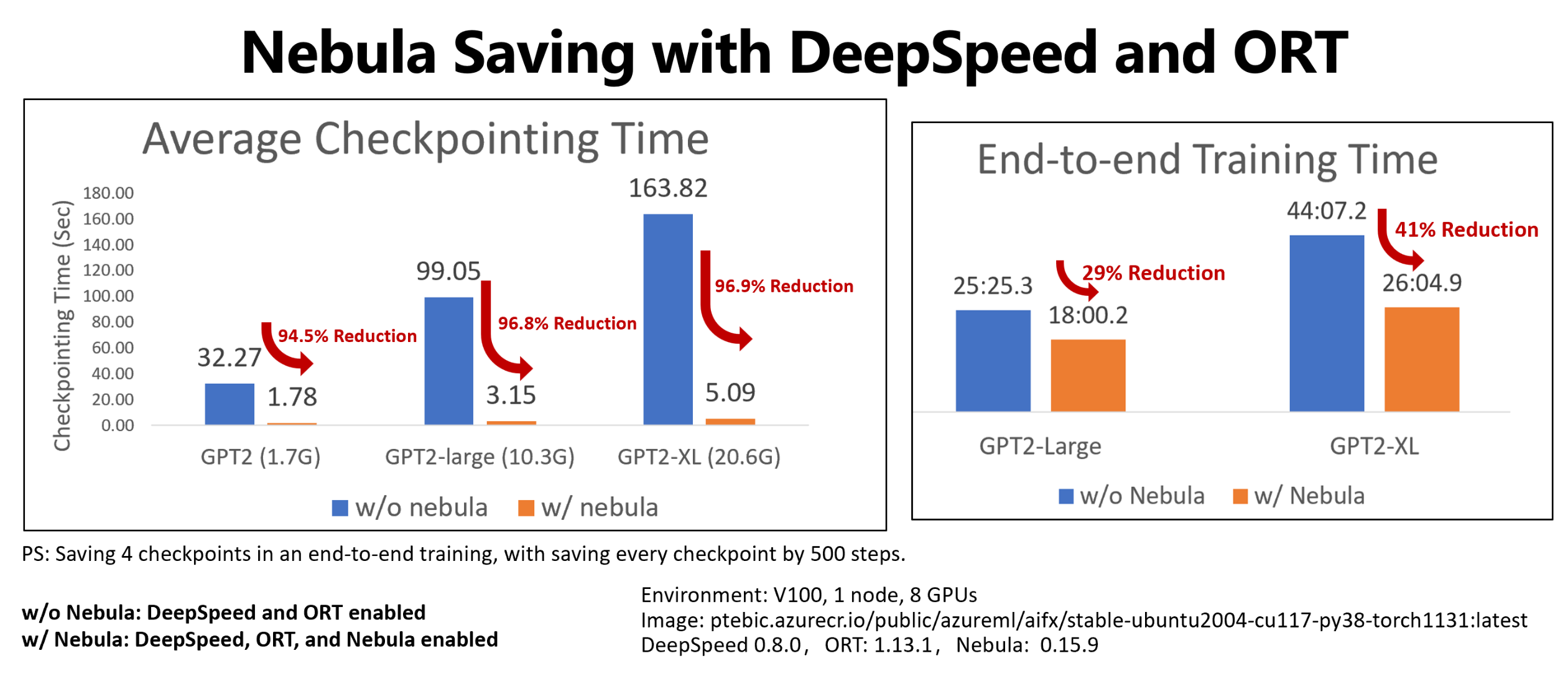
This example shows the checkpoint and end-to-end training time reduction for four checkpoints saving of Hugging Face GPT2, GPT2-Large, and GPT-XL training jobs. For the medium-sized Hugging Face GPT2-XL checkpoint saves (20.6 GB), Nebula achieved a 96.9% time reduction for one checkpoint.
The checkpoint speed gain can still increase with model size and GPU numbers. For example, testing a training point checkpoint save of 97 GB on 128 A100 Nvidia GPUs can shrink from 20 minutes to 1 second.
Reduce end-to-end training time and computation costs for large models by minimizing checkpoint overhead and reducing the number of GPU hours wasted on job recovery. Nebula saves checkpoints asynchronously, and unblocks the training process, to shrink the end-to-end training time. It also allows for more frequent checkpoint saves. This way, you can resume your training from the latest checkpoint after any interruption, and save time and money wasted on job recovery and GPU training hours.
Provide full compatibility with PyTorch. Nebula offers full compatibility with PyTorch, and offers full integration with distributed training frameworks, including DeepSpeed (>=0.7.3), and PyTorch Lightning (>=1.5.0). You can also use it with different Azure Machine Learning compute targets, such as Azure Machine Learning Compute or AKS.
Easily manage your checkpoints with a Python package that helps list, get, save and load your checkpoints. To show the checkpoint lifecycle, Nebula also provides comprehensive logs on Azure Machine Learning studio. You can choose to save your checkpoints to a local or remote storage location
- Azure Blob Storage
- Azure Data Lake Storage
- NFS
and access them at any time with a few lines of code.

Prerequisites
- An Azure subscription and an Azure Machine Learning workspace. See Create workspace resources for more information about workspace resource creation
- An Azure Machine Learning compute target. See Manage training & deploy computes to learn more about compute target creation
- A training script that uses PyTorch.
- ACPT-curated (Azure Container for PyTorch) environment. See Curated environments to obtain the ACPT image. Learn how to use the curated environment
How to Use Nebula
Nebula provides a fast, easy checkpoint experience, right in your existing training script. The steps to quick start Nebula include:
Using ACPT environment
Azure Container for PyTorch (ACPT), a curated environment for PyTorch model training, includes Nebula as a preinstalled, dependent Python package. See Azure Container for PyTorch (ACPT) to view the curated environment, and Enabling Deep Learning with Azure Container for PyTorch in Azure Machine Learning to learn more about the ACPT image.
Initializing Nebula
To enable Nebula with the ACPT environment, you only need to modify your training script to import the nebulaml package, and then call the Nebula APIs in the appropriate places. You can avoid Azure Machine Learning SDK or CLI modification. You can also avoid modification of other steps to train your large model on Azure Machine Learning Platform.
Nebula needs initialization to run in your training script. At the initialization phase, specify the variables that determine the checkpoint save location and frequency, as shown in this code snippet:
import nebulaml as nm
nm.init(persistent_storage_path=<YOUR STORAGE PATH>) # initialize Nebula
Nebula has been integrated into DeepSpeed and PyTorch Lightning. As a result, initialization becomes simple and easy. These examples show how to integrate Nebula into your training scripts.
Important
Saving checkpoints with Nebula requires some memory to store checkpoints. Please make sure your memory is larger than at least three copies of the checkpoints.
If the memory is not enough to hold checkpoints, you are suggested to set up an environment variable NEBULA_MEMORY_BUFFER_SIZE in the command to limit the use of the memory per each node when saving checkpoints. When setting this variable, Nebula will use this memory as buffer to save checkpoints. If the memory usage is not limited, Nebula will use the memory as much as possible to store the checkpoints.
If multiple processes are running on the same node, the maximum memory for saving checkpoints will be half of the limit divided by the number of processes. Nebula will use the other half for multi-process coordination. For example, if you want to limit the memory usage per each node to 200MB, you can set the environment variable as export NEBULA_MEMORY_BUFFER_SIZE=200000000 (in bytes, around 200MB) in the command. In this case, Nebula will only use 200MB memory to store the checkpoints in each node. If there are 4 processes running on the same node, Nebula will use 25MB memory per each process to store the checkpoints.
Calling APIs to save and load checkpoints
Nebula provides APIs to handle checkpoint saves. You can use these APIs in your training scripts, similar to the PyTorch torch.save() API. These examples show how to use Nebula in your training scripts.
View your checkpointing histories
When your training job finishes, navigate to the Job Name> Outputs + logs pane. In the left panel, expand the Nebula folder, and select checkpointHistories.csv to see detailed information about Nebula checkpoint saves - duration, throughput, and checkpoint size.

Examples
These examples show how to use Nebula with different framework types. You can choose the example that best fits your training script.
To enable full Nebula compatibility with PyTorch-based training scripts, modify your training script as needed.
First, import the required
nebulamlpackage:# Import the Nebula package for fast-checkpointing import nebulaml as nmTo initialize Nebula, call the
nm.init()function inmain(), as shown here:# Initialize Nebula with variables that helps Nebula to know where and how often to save your checkpoints persistent_storage_path="/tmp/test", nm.init(persistent_storage_path, persistent_time_interval=2)To save checkpoints, replace the original
torch.save()statement to save your checkpoint with Nebula. Please ensure that your checkpoint instance begins with "global_step", such as "global_step500" or "global_step1000":checkpoint = nm.Checkpoint('global_step500') checkpoint.save('<CKPT_NAME>', model)Note
<'CKPT_TAG_NAME'>is the unique ID for the checkpoint. A tag is usually the number of steps, the epoch number, or any user-defined name. The optional<'NUM_OF_FILES'>optional parameter specifies the state number which you would save for this tag.Load the latest valid checkpoint, as shown here:
latest_ckpt = nm.get_latest_checkpoint() p0 = latest_ckpt.load(<'CKPT_NAME'>)Since a checkpoint or snapshot may contain many files, you can load one or more of them by the name. With the latest checkpoint, the training state can be restored to the state saved by the last checkpoint.
Other APIs can handle checkpoint management
- list all checkpoints
- get latest checkpoints
# Managing checkpoints ## List all checkpoints ckpts = nm.list_checkpoints() ## Get Latest checkpoint path latest_ckpt_path = nm.get_latest_checkpoint_path("checkpoint", persisted_storage_path)
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for