Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Learn how to create a time-series forecasting model without writing a single line of code using automated machine learning in Azure Machine Learning studio. This model predicts rental demand for a bike sharing service.
You don't write any code in this tutorial. Instead, you use the studio interface to perform training. You learn how to do the following tasks:
- Create and load a dataset.
- Configure and run an automated ML experiment.
- Specify forecasting settings.
- Explore the experiment results.
- Deploy the best model.
Also try automated machine learning for other model types:
- For a no-code example of a classification model, see Tutorial: Create a classification model with automated ML in Azure Machine Learning.
- For a code-first example of an object detection model, see Tutorial: Train an object detection model with AutoML and Python.
Prerequisites
An Azure Machine Learning workspace. See Create workspace resources.
Download the bike-no.csv data file.
Sign in to the studio
For this tutorial, you create your automated ML experiment run in Azure Machine Learning studio. Azure Machine Learning studio is a consolidated web interface that includes machine learning tools to perform data science scenarios for data science practitioners of all skill levels.
Sign in to Azure Machine Learning studio.
Select your subscription and the workspace you created.
Create an experiment
In the Authoring section in the left menu, select Automated ML:
Select New automated ML job to start the Submit an Automated ML job process.
By default, the process selects the Train automatically option on the Training method tab and continues to the configuration settings.
On the Basics settings tab, enter values for the required settings, including the Job name and Experiment name. For this tutorial, use
automl-bikeshareas the experiment name. You can also provide values for the optional settings, as desired.Select Next to continue.

Configure your task type and dataset
On the Task type & data tab, you specify the data asset for the experiment and the machine learning model to use to train the data. In this tutorial, you use the bike-no.csv file. If you haven't downloaded the file, do so now.
On the Task type and data form, select Time series forecasting as the task type.
Select Create to create a new data asset from the downloaded file.
On the Data type page, give your dataset a name and provide an optional description. Set the dataset type to Tabular. Select Next to continue.
On the Data source page, select From local files.
Additional options appear in the left menu for you to configure the data source.
Select Next to continue to the Destination storage type page, where you specify the Azure Storage location to upload your data asset.
- For the Datastore type, select Azure Blob Storage.
- In the list of datastores, select the default datastore that was automatically set up during your workspace creation: "workspaceblobstore".
- Select Next.
On the File and folder selection page, use the Upload files or folder dropdown menu and select the Upload files option.
Choose the bike-no.csv file on your local computer. This is the file you downloaded as a prerequisite.
After the files upload, select Next.
Check your uploaded data on the Settings page for accuracy. The fields on the page are prepopulated based on the file type of your data:
Field Description Value for tutorial File format Defines the layout and type of data stored in a file. Delimited Delimiter One or more characters for specifying the boundary between separate, independent regions in plain text or other data streams. Comma Encoding Identifies what bit to character schema table to use to read your dataset. UTF-8 Column headers Indicates how the headers of the dataset, if any, will be treated. Only first file has headers Skip rows Indicates how many, if any, rows are skipped in the dataset. None Select Next to continue to the Schema page. This page is also prepopulated based on your Settings selections.
For this tutorial, choose to ignore the casual and registered columns. These columns are a breakdown of the cnt column, so we don't include them.
Also for this tutorial, leave the defaults for the Properties and Type.
Select Next to continue to the Review + create page.
Review the settings for your data asset. If everything looks good, select Create to create the data asset.
Configure task and forecast settings
When the data asset is ready, Machine Learning studio returns to the Task type & data tab for the Submit an Automated ML job process. The new data asset appears on the page.
Follow these steps to complete the job configuration:
Expand the Select task type dropdown menu, and choose Time series forecasting.
After you specify the training model, select your dataset in the list. Select Next to continue to the Task settings tab.
In the Target column dropdown list, select the cnt column to use for the model predictions.
Select date as your Time column and leave Time series identifiers blank.
The Frequency is how often your historic data is collected. Keep Autodetect selected.
The forecast horizon is the length of time into the future you want to predict. Deselect Autodetect and type 14 in the field.
Leave Enable deep learning deselected.
Select View additional configuration settings and populate the fields as follows. These settings help you better control the training job and specify settings for your forecast. Otherwise, defaults are applied based on experiment selection and data.
Additional configurations Description Value for tutorial Primary metric Evaluation metric that the machine learning algorithm will be measured by. Normalized root mean squared error Explain best model Automatically shows explainability on the best model created by automated ML. Enable Blocked models Algorithms you want to exclude from the training job Extreme Random Trees Additional forecasting settings These settings help improve the accuracy of your model.
Forecast target lags: how far back you want to construct the lags of the target variable
Target rolling window: specifies the size of the rolling window over which features, such as the max, min, and sum, are generated.
Forecast target lags: None
Target rolling window size: NoneLimits If a criterion is met, the training job is stopped. Max concurrent trials: 6
Metric score threshold: None
Experiment timeout (minutes): 180On the [Optional] Validate and test form:
Select k-fold cross-validation as your Validation type.
Select 5 as your Number of cross validations.
Select Save.
Configure the compute target
After you load and configure your data, set up your remote compute target.
Populate the Compute form as follows:
Use the Select compute type dropdown list to select compute cluster as your compute type.
Select +New to configure your compute target. Automated ML only supports Azure Machine Learning compute.
Populate the Select virtual machine form to set up your compute:
Field Description Value for tutorial Virtual machine tier Select what priority your experiment should have Dedicated Virtual machine type Select the virtual machine type for your compute CPU (Central Processing Unit) Virtual machine size Select the virtual machine size for your compute. A list of recommended sizes is provided based on your data and experiment type. Standard_DS12_V2 Select Next to populate the Configure settings form:
Field Description Value for tutorial Compute name A unique name that identifies your compute context. bike-compute Min / Max nodes To profile data, you must specify one or more nodes. Min nodes: 1
Max nodes: 6Idle seconds before scale down Idle time before the cluster is automatically scaled down to the minimum node count. 120 (default) Advanced settings Settings to configure and authorize a virtual network for your experiment. None Select Create to create the compute target.
This takes a couple of minutes to complete.
After creation, select your new compute target from the dropdown list.
Select Next to continue to the Review page. Review the summary of your configuration settings for the job.
Run experiment
To run your experiment, select Submit training job. The Job details screen opens with the Job status at the top next to the job number. This status updates as the experiment progresses. Notifications also appear in the top right corner of the studio to inform you of the status of your experiment.
Important
Preparation takes 10-15 minutes to prepare the experiment job.
Once running, it takes 2-3 minutes more for each iteration.
In production, you'd likely walk away for a bit as this process takes time. While you wait, we suggest you start exploring the tested algorithms on the Models tab as they complete.
Explore models
Navigate to the Models + child jobs tab to see the algorithms (models) tested. By default, the models are ordered by metric score as they complete. For this tutorial, the model that scores the highest based on the chosen Normalized root mean squared error metric appears at the top of the list.
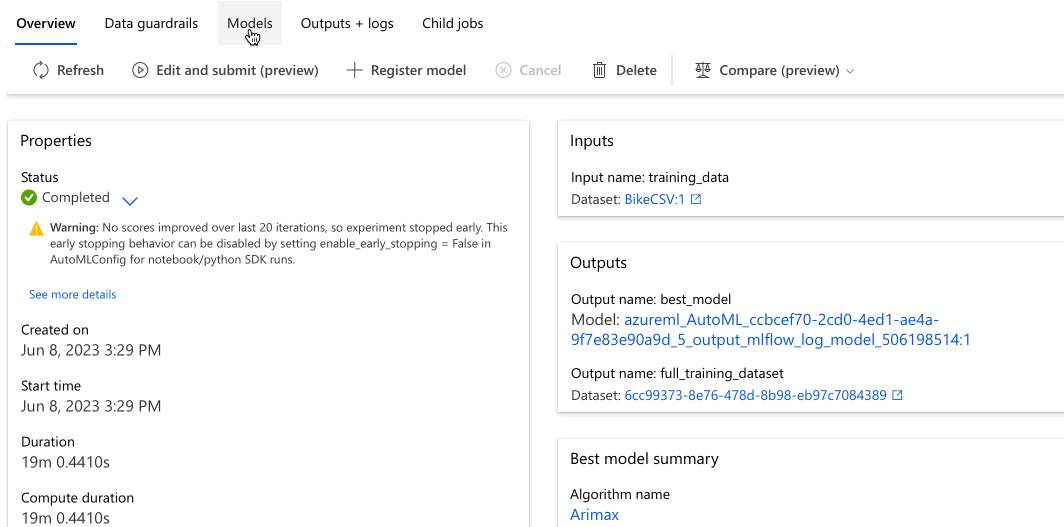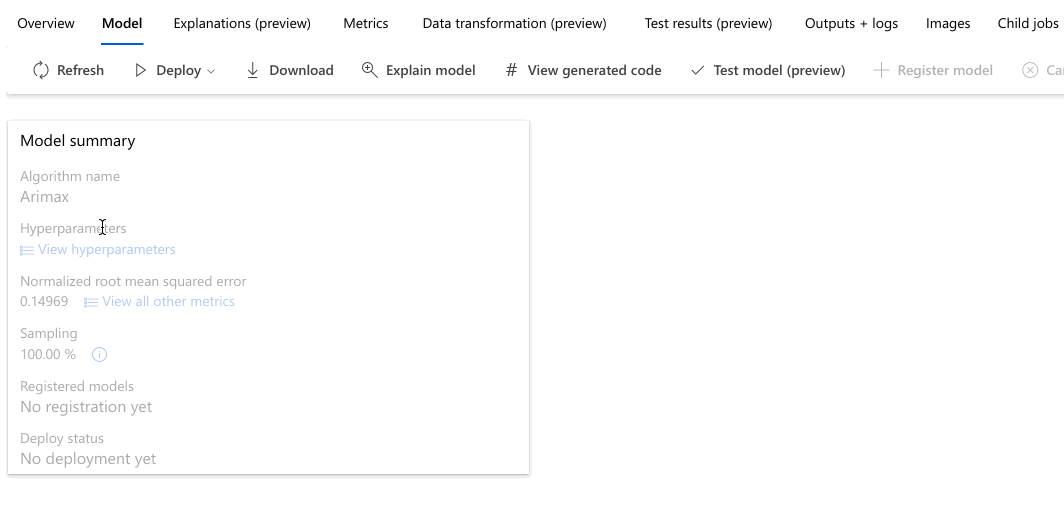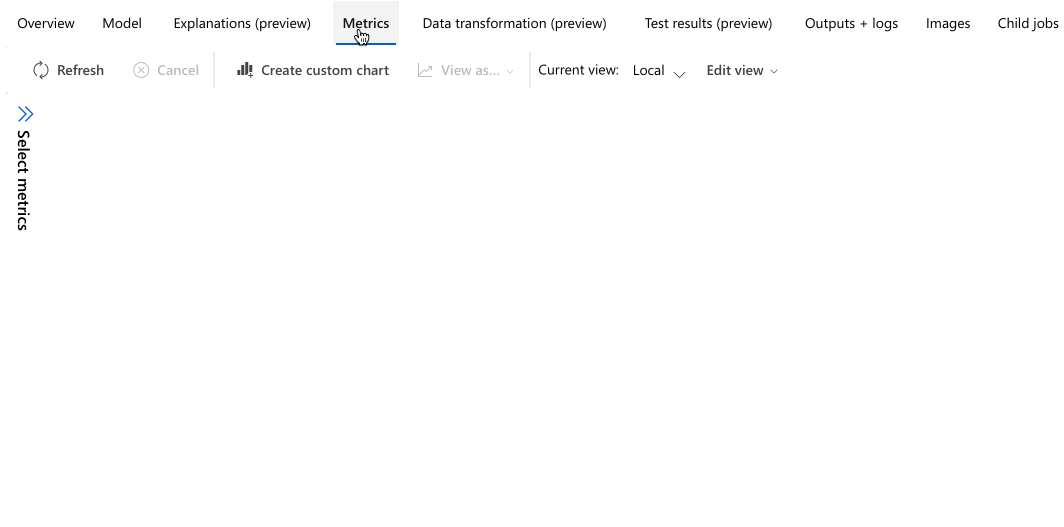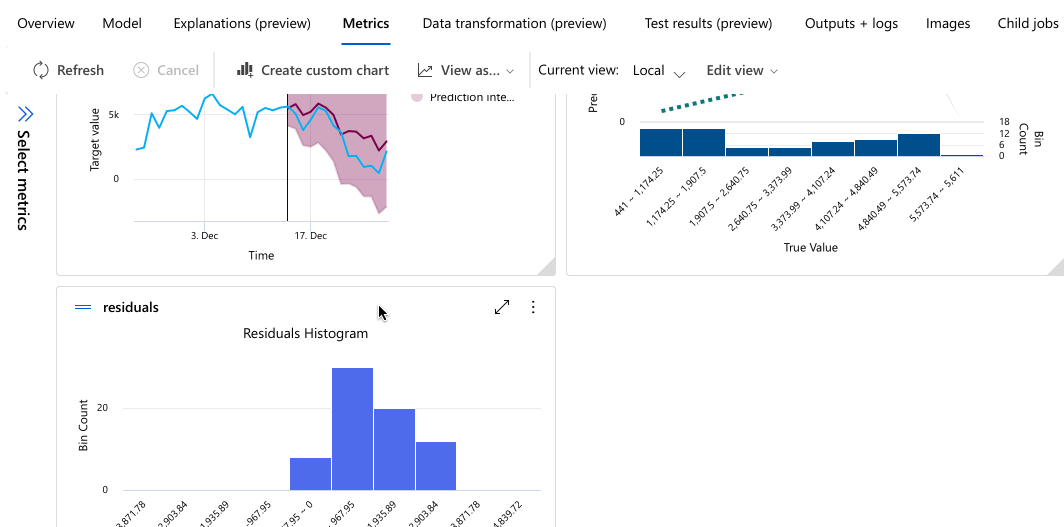
While you wait for all of the experiment models to finish, select the Algorithm name of a completed model to explore its performance details.
The following example navigates to select a model from the list of models that the job created. Then, you select the Overview and Metrics tabs to view the selected model's properties, metrics, and performance charts.
Deploy the model
Automated machine learning in Azure Machine Learning studio allows you to deploy the best model as a web service in a few steps. Deployment is the integration of the model so it can predict on new data and identify potential areas of opportunity.
For this experiment, deployment to a web service means that the bike share company now has an iterative and scalable web solution for forecasting bike share rental demand.
Once the job is complete, navigate back to the parent job page by selecting Job 1 at the top of your screen.
In the Best model summary section, the best model in the context of this experiment is selected based on the Normalized root mean squared error metric.
We deploy this model, but be advised that deployment takes about 20 minutes to complete. The deployment process entails several steps including registering the model, generating resources, and configuring them for the web service.
Select the best model to open the model-specific page.
Select the Deploy button in the top-left area of the screen.
Populate the Deploy a model pane as follows:
Field Value Deployment name bikeshare-deploy Deployment description bike share demand deployment Compute type Select Azure Compute Instance (ACI) Enable authentication Disable Use custom deployment assets Disable. Disabling allows for the default driver file (scoring script) and environment file to be autogenerated. For this example, we use the defaults provided in the Advanced menu.
Select Deploy.
A green success message appears at the top of the Job screen stating that the deployment was started successfully. The progress of the deployment can be found in the Model summary pane under Deploy status.
Once deployment succeeds, you have an operational web service to generate predictions.
Proceed to the Next steps to learn more about how to consume your new web service and test your predictions using Power BI's built-in Azure Machine Learning support.
Clean up resources
Deployment files are larger than data and experiment files, so they cost more to store. Delete only the deployment files to minimize costs to your account, or if you want to keep your workspace and experiment files. Otherwise, delete the entire resource group if you don't plan to use any of the files.
Delete the deployment instance
Delete just the deployment instance from Azure Machine Learning studio if you want to keep the resource group and workspace for other tutorials and exploration.
Go to Azure Machine Learning studio. Navigate to your workspace and on the left under the Assets pane, select Endpoints.
Select the deployment you want to delete and select Delete.
Select Proceed.
Delete the resource group
Important
The resources that you created can be used as prerequisites to other Azure Machine Learning tutorials and how-to articles.
If you don't plan to use any of the resources that you created, delete them so you don't incur any charges:
In the Azure portal, in the search box, enter Resource groups and select it from the results.
From the list, select the resource group that you created.
In the Overview page, select Delete resource group.
Enter the resource group name. Then select Delete.
Next steps
In this tutorial, you used automated ML in the Azure Machine Learning studio to create and deploy a time series forecasting model that predicts bike share rental demand.
- Learn more about automated machine learning.
- For more information on classification metrics and charts, see the Understand automated machine learning results article.
- For more information on FAQs on forecasting.
Note
This bike share dataset has been modified for this tutorial. This dataset was made available as part of a Kaggle competition and was originally available via Capital Bikeshare. It can also be found within the UCI Machine Learning Database.
Source: Fanaee-T, Hadi, and Gama, Joao, Event labeling combining ensemble detectors and background knowledge, Progress in Artificial Intelligence (2013): pp. 1-15, Springer Berlin Heidelberg.