Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Important
This feature is currently in public preview. This preview version is provided without a service-level agreement, and we don't recommend it for production workloads. Certain features might not be supported or might have constrained capabilities.
For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
An Azure Machine Learning managed feature store lets you discover, create, and operationalize features. Features serve as the connective tissue in the machine learning lifecycle, starting from the prototyping phase, where you experiment with various features. That lifecycle continues to the operationalization phase, where you deploy your models, and proceeds to the inference steps that look up feature data. For more information about feature stores, visit feature store concepts.
This tutorial describes how to develop a feature set using Domain Specific Language. The Domain Specific Language (DSL) for the managed feature store provides a simple and user-friendly way to define the most commonly used feature aggregations. With the feature store SDK, users can perform the most commonly used aggregations with a DSL expression. Aggregations that use the DSL expression ensure consistent results, compared with user-defined functions (UDFs). Additionally, those aggregations avoid the overhead of writing UDFs.
This Tutorial shows how to
- Create a new, minimal feature store workspace
- Locally develop and test a feature, through use of Domain Specific Language (DSL)
- Develop a feature set through use of User Defined Functions (UDFs) that perform the same transformations as a feature set created with DSL
- Compare the results of the feature sets created with DSL, and feature sets created with UDFs
- Register a feature store entity with the feature store
- Register the feature set created using DSL with the feature store
- Generate sample training data using the created features
Prerequisites
Note
This tutorial uses an Azure Machine Learning notebook with Serverless Spark Compute.
Before you proceed with this tutorial, make sure that you cover these prerequisites:
- An Azure Machine Learning workspace. If you don't have one, visit Quickstart: Create workspace resources to learn how to create one.
- To perform the steps in this tutorial, your user account needs either the Owner or Contributor role to the resource group where the feature store will be created.
Set up
This tutorial relies on the Python feature store core SDK (azureml-featurestore). This SDK is used for create, read, update, and delete (CRUD) operations, on feature stores, feature sets, and feature store entities.
You don't need to explicitly install these resources for this tutorial, because in the set-up instructions shown here, the conda.yml file covers them.
To prepare the notebook environment for development:
Clone the examples repository - (azureml-examples) to your local machine with this command:
git clone --depth 1 https://github.com/Azure/azureml-examplesYou can also download a zip file from the examples repository (azureml-examples). At this page, first select the
codedropdown, and then selectDownload ZIP. Then, unzip the contents into a folder on your local machine.Upload the feature store samples directory to project workspace
- Open Azure Machine Learning studio UI of your Azure Machine Learning workspace
- Select Notebooks in left panel
- Select your user name in the directory listing
- Select the ellipses (...), and then select Upload folder
- Select the feature store samples folder from the cloned directory path:
azureml-examples/sdk/python/featurestore-sample
Run the tutorial
- Option 1: Create a new notebook, and execute the instructions in this document, step by step
- Option 2: Open existing notebook
featurestore_sample/notebooks/sdk_only/7.Develop-feature-set-domain-specific-language-dsl.ipynb. You can keep this document open, and refer to it for more explanation and documentation links
To configure the notebook environment, you must upload the
conda.ymlfileSelect Notebooks on the left panel, and then select the Files tab
Navigate to the
envdirectory (select Users > your_user_name > featurestore_sample > project > env), and then select theconda.ymlfileSelect Download
Select Serverless Spark Compute in the top navigation Compute dropdown. This operation might take one to two minutes. Wait for the status bar in the top to display the Configure session link
Select Configure session in the top status bar
Select Settings
Select Apache Spark version as
Spark version 3.3Optionally, increase the Session timeout (idle time) if you want to avoid frequent restarts of the serverless Spark session
Under Configuration settings, define Property
spark.jars.packagesand Valuecom.microsoft.azure:azureml-fs-scala-impl:1.0.4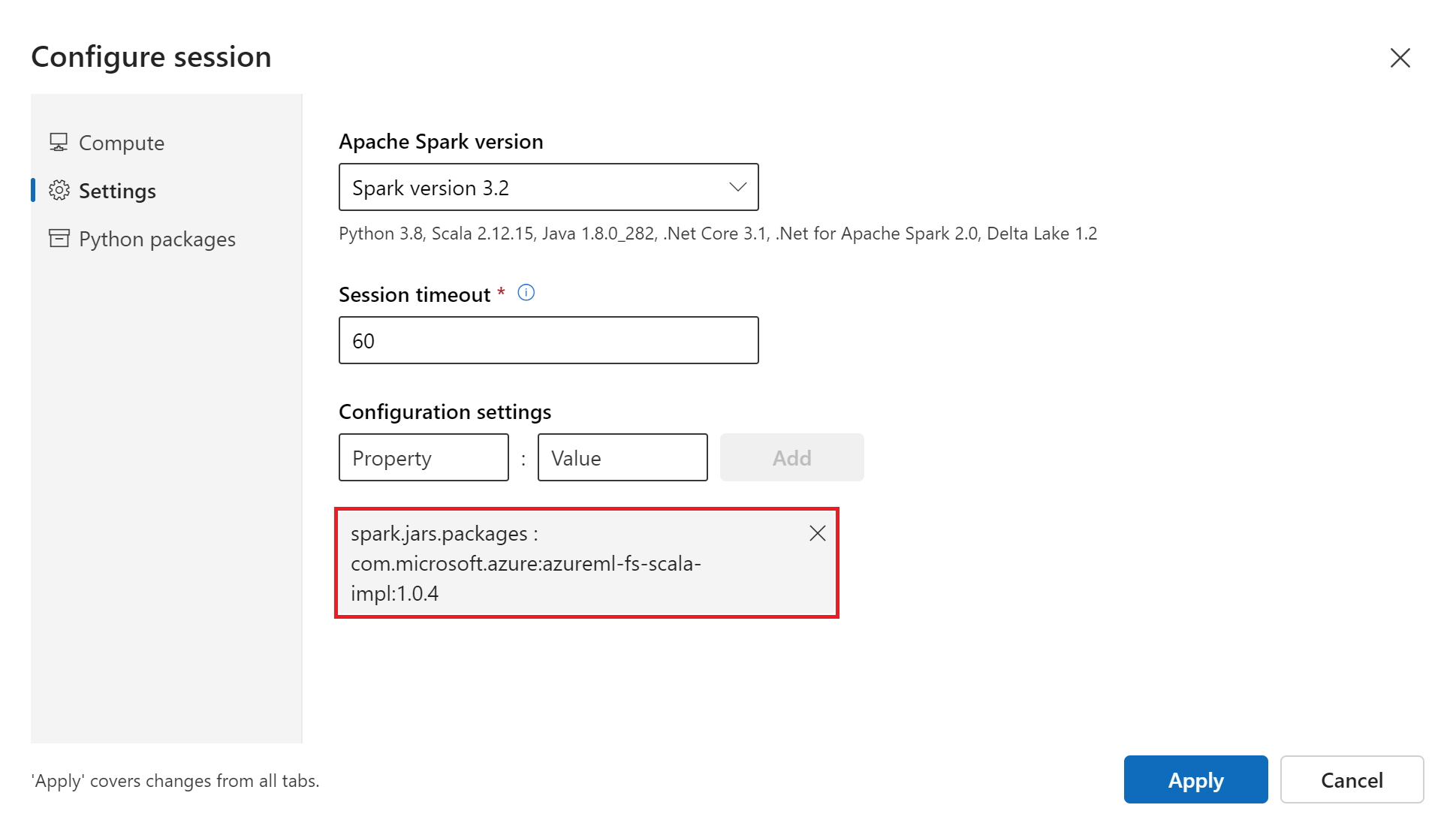
Select Python packages
Select Upload conda file
Select the
conda.ymlyou downloaded on your local deviceSelect Apply
Tip
Except for this specific step, you must run all the other steps every time you start a new spark session, or after session time out.
This code cell sets up the root directory for the samples and starts the Spark session. It needs about 10 minutes to install all the dependencies and start the Spark session:
import os # Please update your alias USER_NAME below (or any custom directory you uploaded the samples to). # You can find the name from the directory structure in the left nav root_dir = "./Users/USER_NAME/featurestore_sample" if os.path.isdir(root_dir): print("The folder exists.") else: print("The folder does not exist. Please create or fix the path")

Provision the necessary resources
Create a minimal feature store:
Create a feature store in a region of your choice, from the Azure Machine Learning studio UI or with Azure Machine Learning Python SDK code.
Option 1: Create feature store from the Azure Machine Learning studio UI
- Navigate to the feature store UI landing page
- Select + Create
- The Basics tab appears
- Choose a Name for your feature store
- Select the Subscription
- Select the Resource group
- Select the Region
- Select Apache Spark version 3.3, and then select Next
- The Materialization tab appears
- Toggle Enable materialization
- Select Subscription and User identity to Assign user managed identity
- Select From Azure subscription under Offline store
- Select Store name and Azure Data Lake Gen2 file system name, then select Next
- On the Review tab, verify the displayed information and then select Create
Option 2: Create a feature store using the Python SDK Provide
featurestore_name,featurestore_resource_group_name, andfeaturestore_subscription_idvalues, and execute this cell to create a minimal feature store:import os featurestore_name = "<FEATURE_STORE_NAME>" featurestore_resource_group_name = "<RESOURCE_GROUP>" featurestore_subscription_id = "<SUBSCRIPTION_ID>" ##### Create Feature Store ##### from azure.ai.ml import MLClient from azure.ai.ml.entities import ( FeatureStore, FeatureStoreEntity, FeatureSet, ) from azure.ai.ml.identity import AzureMLOnBehalfOfCredential ml_client = MLClient( AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, ) featurestore_location = "eastus" fs = FeatureStore(name=featurestore_name, location=featurestore_location) # wait for featurestore creation fs_poller = ml_client.feature_stores.begin_create(fs) print(fs_poller.result())
Assign permissions to your user identity on the offline store:
If feature data is materialized, then you must assign the Storage Blob Data Reader role to your user identity to read feature data from offline materialization store.
- Open the Azure ML global landing page
- Select Feature stores in the left navigation
- You'll see the list of feature stores that you have access to. Select the feature store that you created above
- Select the storage account link under Account name on the Offline materialization store card, to navigate to the ADLS Gen2 storage account for the offline store
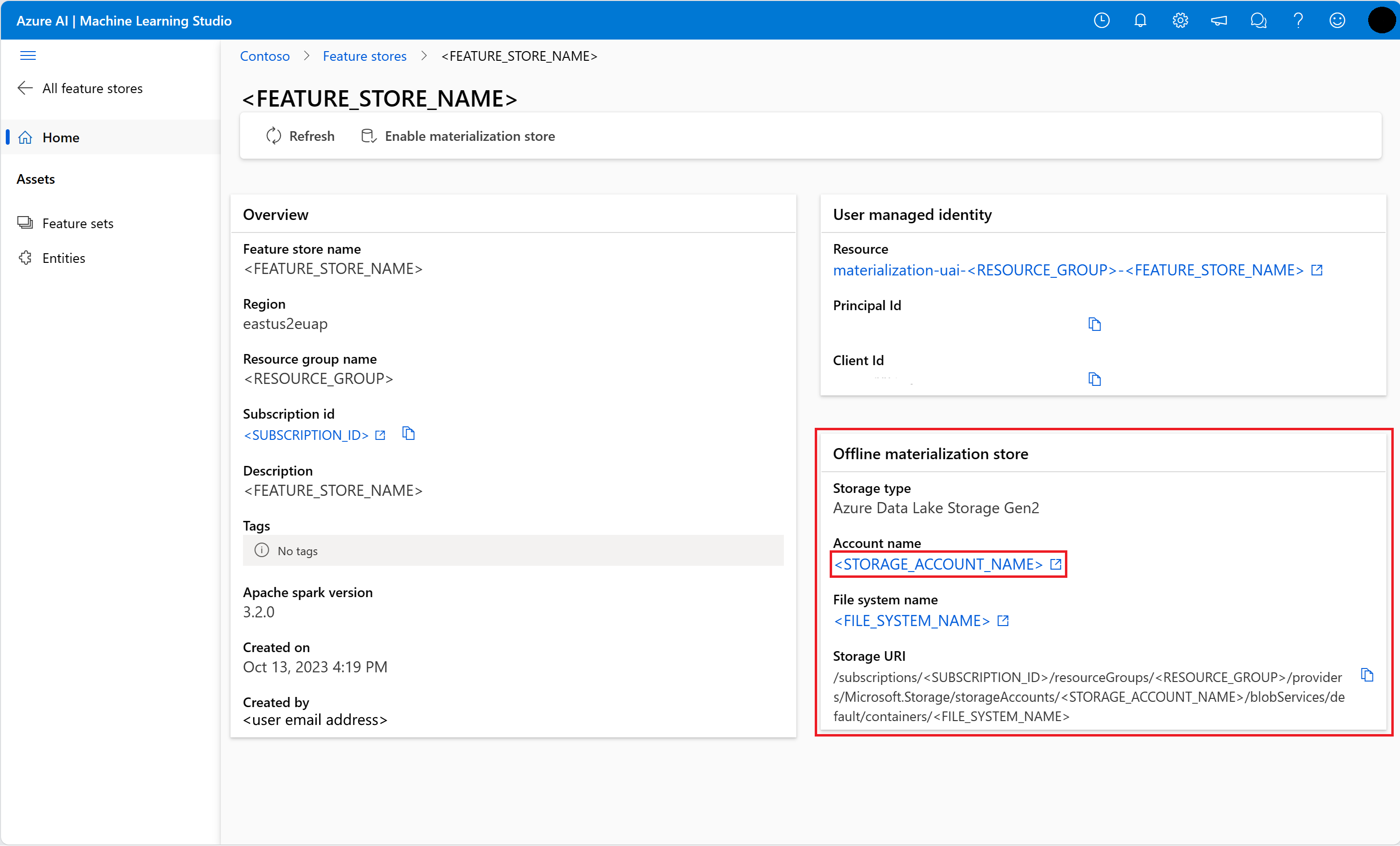
- Visit this resource for more information about how to assign the Storage Blob Data Reader role to your user identity on the ADLS Gen2 storage account for offline store. Allow some time for permissions to propagate.

Available DSL expressions and benchmarks
Currently, these aggregation expressions are supported:
- Average -
avg - Sum -
sum - Count -
count - Min -
min - Max -
max
This table provides benchmarks that compare performance of aggregations that use DSL expression with the aggregations that use UDF, using a representative dataset of size 23.5 GB with the following attributes:
numberOfSourceRows: 348,244,374numberOfOfflineMaterializedRows: 227,361,061
| Function | Expression | UDF execution time | DSL execution time |
|---|---|---|---|
get_offline_features(use_materialized_store=false) |
sum, avg, count |
~2 hours | < 5 minutes |
get_offline_features(use_materialized_store=true) |
sum, avg, count |
~1.5 hours | < 5 minutes |
materialize() |
sum, avg, count |
~1 hour | < 15 minutes |
Note
The min and max DSL expressions provide no performance improvement over UDFs. We recommend that you use UDFs for min and max transformations.
Create a feature set specification using DSL expressions
Execute this code cell to create a feature set specification, using DSL expressions and parquet files as source data.
from azureml.featurestore import create_feature_set_spec from azureml.featurestore.contracts.feature import Feature from azureml.featurestore.transformation import ( TransformationExpressionCollection, WindowAggregation, ) from azureml.featurestore.contracts import ( DateTimeOffset, TransformationCode, Column, ColumnType, SourceType, TimestampColumn, ) from azureml.featurestore.feature_source import ParquetFeatureSource dsl_feature_set_spec = create_feature_set_spec( source=ParquetFeatureSource( path="wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet", timestamp_column=TimestampColumn(name="timestamp"), source_delay=DateTimeOffset(days=0, hours=0, minutes=20), ), index_columns=[Column(name="accountID", type=ColumnType.string)], features=[ Feature(name="f_transaction_3d_count", type=ColumnType.Integer), Feature(name="f_transaction_amount_3d_sum", type=ColumnType.DOUBLE), Feature(name="f_transaction_amount_3d_avg", type=ColumnType.DOUBLE), Feature(name="f_transaction_7d_count", type=ColumnType.Integer), Feature(name="f_transaction_amount_7d_sum", type=ColumnType.DOUBLE), Feature(name="f_transaction_amount_7d_avg", type=ColumnType.DOUBLE), ], feature_transformation=TransformationExpressionCollection( transformation_expressions=[ WindowAggregation( feature_name="f_transaction_3d_count", aggregation="count", window=DateTimeOffset(days=3), ), WindowAggregation( feature_name="f_transaction_amount_3d_sum", source_column="transactionAmount", aggregation="sum", window=DateTimeOffset(days=3), ), WindowAggregation( feature_name="f_transaction_amount_3d_avg", source_column="transactionAmount", aggregation="avg", window=DateTimeOffset(days=3), ), WindowAggregation( feature_name="f_transaction_7d_count", aggregation="count", window=DateTimeOffset(days=7), ), WindowAggregation( feature_name="f_transaction_amount_7d_sum", source_column="transactionAmount", aggregation="sum", window=DateTimeOffset(days=7), ), WindowAggregation( feature_name="f_transaction_amount_7d_avg", source_column="transactionAmount", aggregation="avg", window=DateTimeOffset(days=7), ), ] ), ) dsl_feature_set_specThis code cell defines the start and end times for the feature window.
from datetime import datetime st = datetime(2020, 1, 1) et = datetime(2023, 6, 1)This code cell uses
to_spark_dataframe()to get a dataframe in the defined feature window from the above feature set specification defined using DSL expressions:dsl_df = dsl_feature_set_spec.to_spark_dataframe( feature_window_start_date_time=st, feature_window_end_date_time=et )Print some sample feature values from the feature set defined with DSL expressions:
display(dsl_df)
Create a feature set specification using UDF
Create a feature set specification that uses UDF to perform the same transformations:
from azureml.featurestore import create_feature_set_spec from azureml.featurestore.contracts import ( DateTimeOffset, TransformationCode, Column, ColumnType, SourceType, TimestampColumn, ) from azureml.featurestore.feature_source import ParquetFeatureSource transactions_featureset_code_path = ( root_dir + "/featurestore/featuresets/transactions/transformation_code" ) udf_feature_set_spec = create_feature_set_spec( source=ParquetFeatureSource( path="wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/datasources/transactions-source/*.parquet", timestamp_column=TimestampColumn(name="timestamp"), source_delay=DateTimeOffset(days=0, hours=0, minutes=20), ), transformation_code=TransformationCode( path=transactions_featureset_code_path, transformer_class="transaction_transform.TransactionFeatureTransformer", ), index_columns=[Column(name="accountID", type=ColumnType.string)], infer_schema=True, ) udf_feature_set_specThis transformation code shows that the UDF defines the same transformations as the DSL expressions:
class TransactionFeatureTransformer(Transformer): def _transform(self, df: DataFrame) -> DataFrame: days = lambda i: i * 86400 w_3d = ( Window.partitionBy("accountID") .orderBy(F.col("timestamp").cast("long")) .rangeBetween(-days(3), 0) ) w_7d = ( Window.partitionBy("accountID") .orderBy(F.col("timestamp").cast("long")) .rangeBetween(-days(7), 0) ) res = ( df.withColumn("transaction_7d_count", F.count("transactionID").over(w_7d)) .withColumn( "transaction_amount_7d_sum", F.sum("transactionAmount").over(w_7d) ) .withColumn( "transaction_amount_7d_avg", F.avg("transactionAmount").over(w_7d) ) .withColumn("transaction_3d_count", F.count("transactionID").over(w_3d)) .withColumn( "transaction_amount_3d_sum", F.sum("transactionAmount").over(w_3d) ) .withColumn( "transaction_amount_3d_avg", F.avg("transactionAmount").over(w_3d) ) .select( "accountID", "timestamp", "transaction_3d_count", "transaction_amount_3d_sum", "transaction_amount_3d_avg", "transaction_7d_count", "transaction_amount_7d_sum", "transaction_amount_7d_avg", ) ) return resUse
to_spark_dataframe()to get a dataframe from the above feature set specification, defined using UDF:udf_df = udf_feature_set_spec.to_spark_dataframe( feature_window_start_date_time=st, feature_window_end_date_time=et )Compare the results and verify consistency between the results from the DSL expressions and the transformations performed with UDF. To verify, select one of the
accountIDvalues to compare the values in the two dataframes:display(dsl_df.where(dsl_df.accountID == "A1899946977632390").sort("timestamp"))display(udf_df.where(udf_df.accountID == "A1899946977632390").sort("timestamp"))
Export feature set specifications as YAML
To register the feature set specification with the feature store, it must be saved in a specific format. To review the generated transactions-dsl feature set specification, open this file from the file tree, to see the specification: featurestore/featuresets/transactions-dsl/spec/FeaturesetSpec.yaml
The feature set specification contains these elements:
source: Reference to a storage resource; in this case, a parquet file in a blob storagefeatures: List of features and their datatypes. If you provide transformation code, the code must return a dataframe that maps to the features and data typesindex_columns: The join keys required to access values from the feature set
For more information, read the top level feature store entities document and the feature set specification YAML reference resources.
As an extra benefit of persisting the feature set specification, it can be source controlled.
Execute this code cell to write YAML specification file for the feature set, using parquet data source and DSL expressions:
dsl_spec_folder = root_dir + "/featurestore/featuresets/transactions-dsl/spec" dsl_feature_set_spec.dump(dsl_spec_folder, overwrite=True)Execute this code cell to write a YAML specification file for the feature set, using UDF:
udf_spec_folder = root_dir + "/featurestore/featuresets/transactions-udf/spec" udf_feature_set_spec.dump(udf_spec_folder, overwrite=True)
Initialize SDK clients
The following steps of this tutorial use two SDKs.
Feature store CRUD SDK: The Azure Machine Learning (AzureML) SDK
MLClient(package nameazure-ai-ml), similar to the one used with Azure Machine Learning workspace. This SDK facilitates feature store CRUD operations- Create
- Read
- Update
- Delete
for feature store and feature set entities, because feature store is implemented as a type of Azure Machine Learning workspace
Feature store core SDK: This SDK (
azureml-featurestore) facilitates feature set development and consumption:from azure.ai.ml import MLClient from azure.ai.ml.entities import ( FeatureStore, FeatureStoreEntity, FeatureSet, ) from azure.ai.ml.identity import AzureMLOnBehalfOfCredential from azureml.featurestore import FeatureStoreClient fs_client = MLClient( AzureMLOnBehalfOfCredential(), featurestore_subscription_id, featurestore_resource_group_name, featurestore_name, ) featurestore = FeatureStoreClient( credential=AzureMLOnBehalfOfCredential(), subscription_id=featurestore_subscription_id, resource_group_name=featurestore_resource_group_name, name=featurestore_name, )
Register account entity with the feature store
Create an account entity that has a join key accountID of string type:
from azure.ai.ml.entities import DataColumn
account_entity_config = FeatureStoreEntity(
name="account",
version="1",
index_columns=[DataColumn(name="accountID", type="string")],
)
poller = fs_client.feature_store_entities.begin_create_or_update(account_entity_config)
print(poller.result())Register the feature set with the feature store
Register the
transactions-dslfeature set (that uses DSL) with the feature store, with offline materialization enabled, using the exported feature set specification:from azure.ai.ml.entities import ( FeatureSet, FeatureSetSpecification, MaterializationSettings, MaterializationComputeResource, ) materialization_settings = MaterializationSettings( offline_enabled=True, resource=MaterializationComputeResource(instance_type="standard_e8s_v3"), spark_configuration={ "spark.driver.cores": 4, "spark.driver.memory": "36g", "spark.executor.cores": 4, "spark.executor.memory": "36g", "spark.executor.instances": 2, }, schedule=None, ) fset_config = FeatureSet( name="transactions-dsl", version="1", entities=["azureml:account:1"], stage="Development", specification=FeatureSetSpecification(path=dsl_spec_folder), materialization_settings=materialization_settings, tags={"data_type": "nonPII"}, ) poller = fs_client.feature_sets.begin_create_or_update(fset_config) print(poller.result())Materialize the feature set to persist the transformed feature data to the offline store:
poller = fs_client.feature_sets.begin_backfill( name="transactions-dsl", version="1", feature_window_start_time=st, feature_window_end_time=et, spark_configuration={}, data_status=["None", "Incomplete"], ) print(poller.result().job_ids)Execute this code cell to track the progress of the materialization job:
# get the job URL, and stream the job logs (the back fill job could take 10+ minutes to complete) fs_client.jobs.stream(poller.result().job_ids[0])Print sample data from the feature set. The output information shows that the data was retrieved from the materialization store. The
get_offline_features()method used to retrieve the training/inference data also uses the materialization store by default:# look up the featureset by providing name and version transactions_featureset = featurestore.feature_sets.get("transactions-dsl", "1") display(transactions_featureset.to_spark_dataframe().head(5))
Generate a training dataframe using the registered feature set
Load observation data
Observation data is typically the core data used in training and inference steps. Then, the observation data is joined with the feature data, to create a complete training data resource. Observation data is the data captured during the time of the event. In this case, it has core transaction data including transaction ID, account ID, and transaction amount. Since this data is used for training, it also has the target variable appended (is_fraud).
First, explore the observation data:
observation_data_path = "wasbs://data@azuremlexampledata.blob.core.windows.net/feature-store-prp/observation_data/train/*.parquet" observation_data_df = spark.read.parquet(observation_data_path) obs_data_timestamp_column = "timestamp" display(observation_data_df) # Note: the timestamp column is displayed in a different format. Optionally, you can can call training_df.show() to see correctly formatted valueSelect features that would be part of the training data, and use the feature store SDK to generate the training data:
featureset = featurestore.feature_sets.get("transactions-dsl", "1") # you can select features in pythonic way features = [ featureset.get_feature("f_transaction_amount_7d_sum"), featureset.get_feature("f_transaction_amount_7d_avg"), ] # you can also specify features in string form: featureset:version:feature more_features = [ "transactions-dsl:1:f_transaction_amount_3d_sum", "transactions-dsl:1:f_transaction_3d_count", ] more_features = featurestore.resolve_feature_uri(more_features) features.extend(more_features)The
get_offline_features()function appends the features to the observation data with a point-in-time join. Display the training dataframe obtained from the point-in-time join:from azureml.featurestore import get_offline_features training_df = get_offline_features( features=features, observation_data=observation_data_df, timestamp_column=obs_data_timestamp_column, ) display(training_df.sort("transactionID", "accountID", "timestamp"))
Generate a training dataframe from feature sets using DSL and UDF
Register the
transactions-udffeature set (that uses UDF) with the feature store, using the exported feature set specification. Enable offline materialization for this feature set while registering with the feature store:fset_config = FeatureSet( name="transactions-udf", version="1", entities=["azureml:account:1"], stage="Development", specification=FeatureSetSpecification(path=udf_spec_folder), materialization_settings=materialization_settings, tags={"data_type": "nonPII"}, ) poller = fs_client.feature_sets.begin_create_or_update(fset_config) print(poller.result())Select features from the feature sets (created using DSL and UDF) that you would like to become part of the training data, and use the feature store SDK to generate the training data:
featureset_dsl = featurestore.feature_sets.get("transactions-dsl", "1") featureset_udf = featurestore.feature_sets.get("transactions-udf", "1") # you can select features in pythonic way features = [ featureset_dsl.get_feature("f_transaction_amount_7d_sum"), featureset_udf.get_feature("transaction_amount_7d_avg"), ] # you can also specify features in string form: featureset:version:feature more_features = [ "transactions-udf:1:transaction_amount_3d_sum", "transactions-dsl:1:f_transaction_3d_count", ] more_features = featurestore.resolve_feature_uri(more_features) features.extend(more_features)The function
get_offline_features()appends the features to the observation data with a point-in-time join. Display the training dataframe obtained from the point-in-time join:from azureml.featurestore import get_offline_features training_df = get_offline_features( features=features, observation_data=observation_data_df, timestamp_column=obs_data_timestamp_column, ) display(training_df.sort("transactionID", "accountID", "timestamp"))
The features are appended to the training data with a point-in-time join. The generated training data can be used for subsequent training and batch inferencing steps.
Clean up
The fifth tutorial in the series describes how to delete the resources.