Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Where possible, we recommend using Apache Cassandra native replication to migrate data from your existing cluster into Azure Managed Instance for Apache Cassandra by configuring a hybrid cluster. This approach will use Apache Cassandra's gossip protocol to replicate data from your source data-center into your new managed instance datacenter. However, there may be some scenarios where your source database version isn't compatible, or a hybrid cluster setup is otherwise not feasible.
This tutorial describes how to migrate data to Migrate to Azure Managed Instance for Apache Cassandra in an offline fashion using the Cassandra Spark Connector, and Azure Databricks for Apache Spark.
Prerequisites
Provision an Azure Managed Instance for Apache Cassandra cluster using Azure portal or Azure CLI and ensure you can connect to your cluster with CQLSH.
Provision an Azure Databricks account inside your Managed Cassandra VNet. Ensure it also has network access to your source Cassandra cluster.
Ensure you've already migrated the keyspace/table scheme from your source Cassandra database to your target Cassandra Managed Instance database.
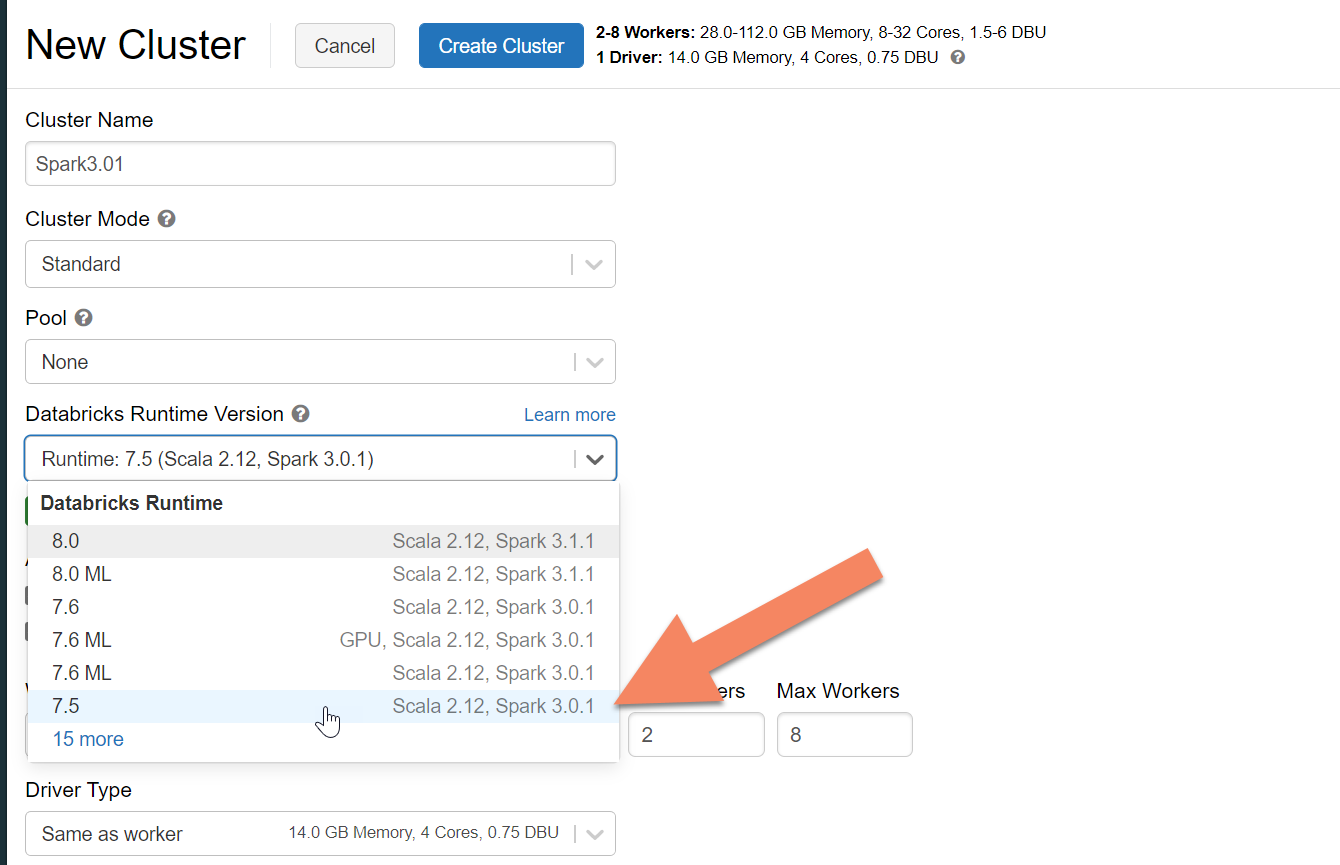
Provision an Azure Databricks cluster
We recommend selecting Databricks runtime version 7.5, which supports Spark 3.0.
Add dependencies
Add the Apache Spark Cassandra Connector library to your cluster to connect to both native and Azure Cosmos DB Cassandra endpoints. In your cluster, select Libraries > Install New > Maven, and then add com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 in Maven coordinates.

Select Install, and then restart the cluster when installation is complete.
Note
Make sure that you restart the Databricks cluster after the Cassandra Connector library has been installed.
Create Scala Notebook for migration
Create a Scala Notebook in Databricks. Replace your source and target Cassandra configurations with the corresponding credentials, and source and target keyspaces and tables. Then run the following code:
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val sourceCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "false",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val targetCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "10",
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//Read from source Cassandra
val DFfromSourceCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(sourceCassandra)
.load
//Write to target Cassandra
DFfromSourceCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(targetCassandra)
.mode(SaveMode.Append) // only required for Spark 3.x
.save
Note
If you have a need to preserve the original writetime of each row, refer to the cassandra migrator sample.