Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Important
On September 30, 2027, network security group (NSG) flow logs will be retired. As part of this retirement, you'll no longer be able to create new NSG flow logs starting June 30, 2025. We recommend migrating to virtual network flow logs, which overcome the limitations of NSG flow logs. After the retirement date, traffic analytics enabled with NSG flow logs will no longer be supported, and existing NSG flow logs resources in your subscriptions will be deleted. However, NSG flow logs records won't be deleted and will continue to follow their respective retention policies. For more information, see the official announcement.
Network Security Group (NSG) flow logs provide information that can be used to understand ingress and egress IP traffic on network interfaces. These flow logs show outbound and inbound flows on a per NSG rule basis, the NIC the flow applies to, 5-tuple information about the flow (Source/Destination IP, Source/Destination Port, Protocol), and if the traffic was allowed or denied.
You can have many NSGs in your network with flow logging enabled. This amount of logging data makes it cumbersome to parse and gain insights from your logs. This article provides a solution to centrally manage these NSG flow logs using Grafana, an open source graphing tool, Elasticsearch, a distributed search and analytics engine, and Logstash, which is an open source server-side data processing pipeline.
Scenario
NSG flow logs are enabled using Network Watcher and are stored in Azure blob storage. A Logstash plugin is used to connect and process flow logs from blob storage and send them to Elasticsearch. Once the flow logs are stored in Elasticsearch, they can be analyzed and visualized into customized dashboards in Grafana.
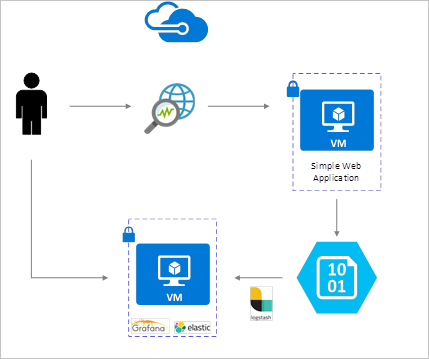
Installation steps
Enable Network Security Group flow logging
For this scenario, you must have Network Security Group Flow Logging enabled on at least one Network Security Group in your account. For instructions on enabling Network Security Flow Logs, refer to the following article Introduction to flow logging for Network Security Groups.
Setup considerations
In this example Grafana, Elasticsearch, and Logstash are configured on an Ubuntu LTS Server deployed in Azure. This minimal setup is used for running all three components - they are all running on the same VM. This setup should only be used for testing and non-critical workloads. Logstash, Elasticsearch, and Grafana can all be architected to scale independently across many instances. For more information, see the documentation for each of these components.
Install Logstash
You use Logstash to flatten the JSON formatted flow logs to a flow tuple level.
The following instructions are used to install Logstash in Ubuntu. For instructions about how to install this package in Red Hat Enterprise Linux, see Installing from Package Repositories - yum.
To install Logstash, run the following commands:
curl -L -O https://artifacts.elastic.co/downloads/logstash/logstash-5.2.0.deb sudo dpkg -i logstash-5.2.0.debConfigure Logstash to parse the flow logs and send them to Elasticsearch. Create a Logstash.conf file using:
sudo touch /etc/logstash/conf.d/logstash.confAdd the following content to the file. Change the storage account name and access key to reflect your storage account details:
input { azureblob { storage_account_name => "mystorageaccount" storage_access_key => "VGhpcyBpcyBhIGZha2Uga2V5Lg==" container => "insights-logs-networksecuritygroupflowevent" codec => "json" # Refer https://learn.microsoft.com/azure/network-watcher/network-watcher-read-nsg-flow-logs # Typical numbers could be 21/9 or 12/2 depends on the nsg log file types file_head_bytes => 12 file_tail_bytes => 2 # Enable / tweak these settings when event is too big for codec to handle. # break_json_down_policy => "with_head_tail" # break_json_batch_count => 2 } } filter { split { field => "[records]" } split { field => "[records][properties][flows]"} split { field => "[records][properties][flows][flows]"} split { field => "[records][properties][flows][flows][flowTuples]"} mutate { split => { "[records][resourceId]" => "/"} add_field => { "Subscription" => "%{[records][resourceId][2]}" "ResourceGroup" => "%{[records][resourceId][4]}" "NetworkSecurityGroup" => "%{[records][resourceId][8]}" } convert => {"Subscription" => "string"} convert => {"ResourceGroup" => "string"} convert => {"NetworkSecurityGroup" => "string"} split => { "[records][properties][flows][flows][flowTuples]" => "," } add_field => { "unixtimestamp" => "%{[records][properties][flows][flows][flowTuples][0]}" "srcIp" => "%{[records][properties][flows][flows][flowTuples][1]}" "destIp" => "%{[records][properties][flows][flows][flowTuples][2]}" "srcPort" => "%{[records][properties][flows][flows][flowTuples][3]}" "destPort" => "%{[records][properties][flows][flows][flowTuples][4]}" "protocol" => "%{[records][properties][flows][flows][flowTuples][5]}" "trafficflow" => "%{[records][properties][flows][flows][flowTuples][6]}" "traffic" => "%{[records][properties][flows][flows][flowTuples][7]}" "flowstate" => "%{[records][properties][flows][flows][flowTuples][8]}" "packetsSourceToDest" => "%{[records][properties][flows][flows][flowTuples][9]}" "bytesSentSourceToDest" => "%{[records][properties][flows][flows][flowTuples][10]}" "packetsDestToSource" => "%{[records][properties][flows][flows][flowTuples][11]}" "bytesSentDestToSource" => "%{[records][properties][flows][flows][flowTuples][12]}" } add_field => { "time" => "%{[records][time]}" "systemId" => "%{[records][systemId]}" "category" => "%{[records][category]}" "resourceId" => "%{[records][resourceId]}" "operationName" => "%{[records][operationName]}" "Version" => "%{[records][properties][Version]}" "rule" => "%{[records][properties][flows][rule]}" "mac" => "%{[records][properties][flows][flows][mac]}" } convert => {"unixtimestamp" => "integer"} convert => {"srcPort" => "integer"} convert => {"destPort" => "integer"} add_field => { "message" => "%{Message}" } } date { match => ["unixtimestamp" , "UNIX"] } } output { stdout { codec => rubydebug } elasticsearch { hosts => "localhost" index => "nsg-flow-logs" } }
The Logstash config file provided is composed of three parts: the input, filter, and output. The input section designates the input source of the logs that Logstash will process – in this case we are going to use an “azureblob” input plugin (installed in the next steps) that will allow us to access the NSG flow log JSON files stored in blob storage.
The filter section then flattens each flow log file so that each individual flow tuple and its associated properties becomes a separate Logstash event.
Finally, the output section forwards each Logstash event to the Elasticsearch server. Feel free to modify the Logstash config file to suit your specific needs.
Install the Logstash input plugin for Azure Blob storage
This Logstash plugin enables you to directly access the flow logs from their designated blob storage account. To install this plug in, from the default Logstash installation directory (in this case /usr/share/logstash/bin) run the command:
sudo /usr/share/logstash/bin/logstash-plugin install logstash-input-azureblob
For more information about this plug in, see Logstash input plugin for Azure Storage Blobs.
Install Elasticsearch
You can use the following script to install Elasticsearch. For information about installing Elasticsearch, see Elastic Stack.
sudo apt-get install apt-transport-https openjdk-8-jre-headless uuid-runtime pwgen -y
wget -qO - https://packages.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
echo "deb https://packages.elastic.co/elasticsearch/5.x/debian stable main" | sudo tee -a /etc/apt/sources.list.d/elasticsearch-5.x.list
sudo apt-get update && apt-get install elasticsearch
sudo sed -i s/#cluster.name:.*/cluster.name:\ grafana/ /etc/elasticsearch/elasticsearch.yml
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch.service
sudo systemctl start elasticsearch.service
Install Grafana
To install and run Grafana, run the following commands:
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana_4.5.1_amd64.deb
sudo apt-get install -y adduser libfontconfig
sudo dpkg -i grafana_4.5.1_amd64.deb
sudo service grafana-server start
For additional installation information, see Installing on Debian / Ubuntu.
Add the Elasticsearch server as a data source
Next, you need to add the Elasticsearch index containing flow logs as a data source. You can add a data source by selecting Add data source and completing the form with the relevant information.
Create a dashboard
Now that you have successfully configured Grafana to read from the Elasticsearch index containing NSG flow logs, you can create and personalize dashboards. To create a new dashboard, select Create your first dashboard. The following sample graph configuration shows flows segmented by NSG rule:
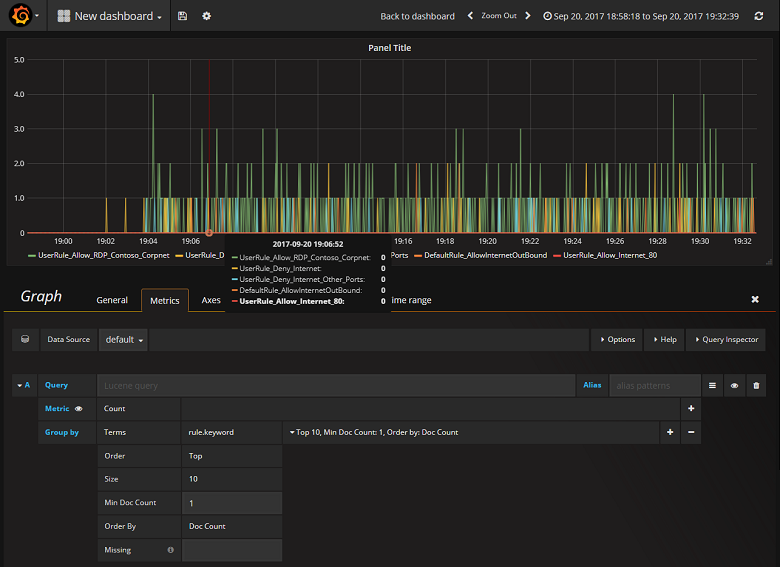
Conclusion
By integrating Network Watcher with Elasticsearch and Grafana, you now have a convenient and centralized way to manage and visualize NSG flow logs as well as other data. Grafana has a number of other powerful graphing features that can also be used to further manage flow logs and better understand your network traffic. Now that you have a Grafana instance set up and connected to Azure, feel free to continue to explore the other functionality that it offers.
Next step
- Learn more about using Network Watcher.