Run or reset indexers, skills, or documents
In Azure AI Search, there are several ways to run an indexer:
- Run immediately upon indexer creation, assuming it's not created in "disabled" mode.
- Run on a schedule to invoke execution at regular intervals.
- Run on demand, with or without a "reset".
This article explains how to run indexers on demand, with and without a reset. It also describes indexer execution, duration, and concurrency.
How indexers connect to Azure resources
Indexers are one of the few subsystems that make overt outbound calls to other Azure resources. In terms of Azure roles, indexers don't have separate identities: a connection from the search engine to another Azure resource is made using the system or user-assigned managed identity of a search service. If the indexer connects to an Azure resource on a virtual network, you should create a shared private link for that connection. For more information about secure connections, see the Security in Azure AI Search.
Indexer execution
A search service runs one indexer job per search unit. Every search service starts with one search unit, but each new partition or replica increases the search units of your service. You can check the search unit count in the portal's Essential section of the Overview page. If you need concurrent processing, make sure you have sufficient replicas. Indexers don't run in the background, so you might detect more query throttling than usual if the service is under pressure.
The following screenshot shows the number of search units, which determines how many indexers can run at once.

Once indexer execution starts, you can't pause or stop it. Indexer execution stops when there are no more documents to load or refresh, or when the maximum running time limit is reached.
You can run multiple indexers at one time assuming sufficient capacity, but each indexer itself is single-instance. Starting a new instance while the indexer is already in execution produces this error: "Failed to run indexer "<indexer name>" error: "Another indexer invocation is currently in progress; concurrent invocations are not allowed."
An indexer job runs in a managed execution environment. Currently, there are two environments. You can't control or configure which environment is used. Azure AI Search determines the environment based on job composition and the ability of the service to move an indexer job onto a content processor (some security features block the multitenant environment).
Indexer execution environments include:
A private execution environment that runs on search nodes, specific to your search service.
A multitenant environment with content processors, managed and secured by Microsoft at no extra cost. This environment is used to offload computationally intensive processing, leaving service-specific resources available for routine operations. Whenever possible, most indexer jobs are executed in the multitenant environment.
Indexer limits vary for each environment:
| Workload | Maximum duration | Maximum jobs | Execution environment |
|---|---|---|---|
| Private execution | 24 hours | One indexer job per search unit 1. | Indexing doesn't run in the background. Instead, the search service will balance all indexing jobs against ongoing queries and object management actions (such as creating or updating indexes). When running indexers, you should expect to see some query latency if indexing volumes are large. |
| Multitenant | 2 hours 2 | Indeterminate 3 | Because the content processing cluster is multitenant, nodes are added to meet demand. If you experience a delay in on-demand or scheduled execution, it's probably because the system is either adding nodes or waiting for one to become available. |
1 Search units can be flexible combinations of partitions and replicas, but indexer jobs aren't tied to one or the other. In other words, if you have 12 units, you can have 12 indexer jobs running concurrently in private execution, no matter how the search units are deployed.
2 If more than two hours are needed to process all of the data, enable change detection and schedule the indexer to run at two hour intervals. See Indexing a large data set for more strategies.
3 "Indeterminate" means that the limit isn't quantified by the number of jobs. Some workloads, such as skillset processing, can run in parallel, which could result in many jobs even though only one indexer is involved. Although the environment doesn't impose constraints, indexer limits for your search service still apply.
Run without reset
A Run Indexer operation will detect and process only what it necessary to synchronize the search index with changes in the underlying data source. Incremental indexing starts by locating an internal high-water mark to find the last updated search document, which becomes the starting point for indexer execution over new and updated documents in the data source.
Change detection is essential for determining what's new or updated in the data source. Indexers use the change detection capabilities of the underlying data source to determine what's new or updated in the data source.
Azure Storage has built-in change detection through its LastModified property.
Other data sources, such as Azure SQL or Azure Cosmos DB, have to be configured for change detection before the indexer can read new and updated rows.
If the underlying content is unchanged, a run operation has no effect. In this case, indexer execution history will indicate 0\0 documents processed.
You'll need to reset the indexer, as explained in the next section, to reprocess in full.
Resetting indexers
After the initial run, an indexer keeps track of which search documents have been indexed through an internal high-water mark. The marker is never exposed, but internally the indexer knows where it last stopped.
If you need to rebuild all or part of an index, you can clear the indexer's high-water mark through a reset. Reset APIs are available at decreasing levels in the object hierarchy:
- Reset Indexers clears the high-water mark and performs a full reindex of all documents
- Reset Documents (preview) reindexes a specific document or list of documents
- Reset Skills (preview) invokes skill processing for a specific skill
After reset, follow with a Run command to reprocess new and existing documents. Orphaned search documents having no counterpart in the data source can't be removed through reset/run. If you need to delete documents, see Add, Update or Delete Documents instead.
How to reset and run indexers
Reset clears the high-water mark. All documents in the search index will be flagged for full overwrite, without inline updates or merging into existing content. For indexers with a skillset and enrichment caching, resetting the index will also implicitly reset the skillset.
The actual work occurs when you follow a reset with a Run command:
- All new documents found the underlying source are added to the search index.
- All documents that exist in both the data source and search index will be overwritten in the search index.
- Any enriched content created from skillsets will be rebuilt. The enrichment cache, if one is enabled, is refreshed.
As previously noted, reset is a passive operation: you must follow up a Run request to rebuild the index.
Reset/run operations apply to a search index or a knowledge store, to specific documents or projections, and to cached enrichments if a reset explicitly or implicitly includes skills.
Reset also applies to create and update operations. It will not trigger deletion or clean up of orphaned documents in the search index. For more information about deleting documents, see Add, Update or Delete Documents.
Once you reset an indexer, you can't undo the action.
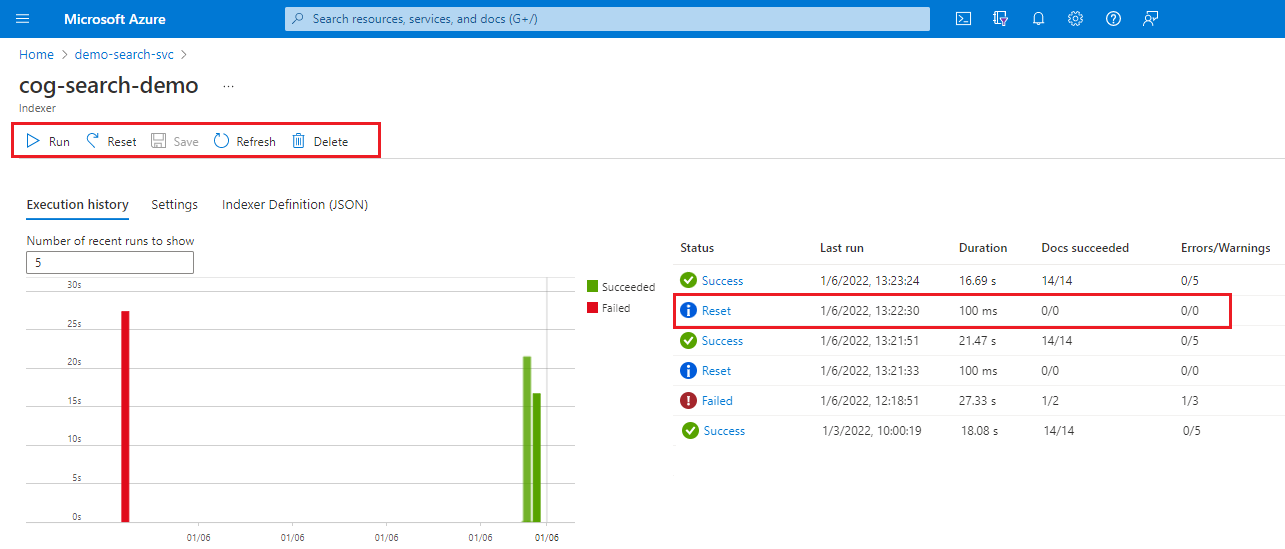
Sign in to the Azure portal and open the search service page.
On the Overview page, select the Indexers tab.
Select an indexer.
Select the Reset command, and then select Yes to confirm the action.
Refresh the page to show the status. You can select the item to view its details.
Select Run to start indexer processing, or wait for the next scheduled execution.
How to reset skills (preview)
For indexers that have skillsets, you can reset individual skills to force processing of just that skill and any downstream skills that depend on its output. The enrichment cache, if you enabled it, is also refreshed.
Reset Skills is currently REST-only, available through api-version=2020-06-30-Preview or later.
POST /skillsets/[skillset name]/resetskills?api-version=2020-06-30-Preview
{
"skillNames" : [
"#1",
"#5",
"#6"
]
}
You can specify individual skills, as indicated in the example above, but if any of those skills require output from unlisted skills (#2 through #4), unlisted skills will run unless the cache can provide the necessary information. In order for this to be true, cached enrichments for skills #2 through #4 must not have dependency on #1 (listed for reset).
If no skills are specified, the entire skillset is executed and if caching is enabled, the cache is also refreshed.
Remember to follow up with Run Indexer to invoke actual processing.
How to reset docs (preview)
The Reset Documents API accepts a list of document keys so that you can refresh specific documents. If specified, the reset parameters become the sole determinant of what gets processed, regardless of other changes in the underlying data. For example, if 20 blobs were added or updated since the last indexer run, but you only reset one document, only that document is processed.
On a per-document basis, all fields in that search document are refreshed with values from the data source. You can't pick and choose which fields to refresh.
If the document is enriched through a skillset and has cached data, the skillset is invoked for just the specified documents, and the cache is updated for the reprocessed documents.
When you're testing this API for the first time, the following APIs can help you validate and test the behaviors:
Call Get Indexer Status with API version
api-version=2020-06-30-Previewor later, to check reset status and execution status. You can find information about the reset request at the end of the status response.Call Reset Documents with API version
api-version=2020-06-30-Previewor later, to specify which documents to process.POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2020-06-30-Preview { "documentKeys" : [ "1001", "4452" ] }The document keys provided in the request are values from the search index, which can be different from the corresponding fields in the data source. If you're unsure of the key value, send a query to return the value.You can use
selectto return just the document key field.For blobs that are parsed into multiple search documents (where parsingMode is set to jsonLines or jsonArrays, or delimitedText), the document key is generated by the indexer and might be unknown to you. In this scenario, a query for the document key to return the correct value.
Call Run Indexer (any API version) to process the documents you specified. Only those specific documents are indexed.
Call Run Indexer a second time to process from the last high-water mark.
Call Search Documents to check for updated values, and also to return document keys if you're unsure of the value. Use
"select": "<field names>"if you want to limit which fields appear in the response.
Overwriting the document key list
Calling Reset Documents API multiple times with different keys appends the new keys to the list of document keys reset. Calling the API with the overwrite parameter set to true will overwrite the current list with the new one:
POST https://[service name].search.windows.net/indexers/[indexer name]/resetdocs?api-version=2020-06-30-Preview
{
"documentKeys" : [
"200",
"630"
],
"overwrite": true
}
Check reset status "currentState"
To check reset status and to see which document keys are queued up for processing, following these steps.
Call Get Indexer Status with
api-version=06-30-2020-Previewor later.The preview API will return the
currentStatesection, found at the end of the response."currentState": { "mode": "indexingResetDocs", "allDocsInitialTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "allDocsFinalTrackingState": "{\"LastFullEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"LastAttemptedEnumerationStartTime\":\"2021-02-06T19:02:07.0323764+00:00\",\"NameHighWaterMark\":null}", "resetDocsInitialTrackingState": null, "resetDocsFinalTrackingState": null, "resetDocumentKeys": [ "200", "630" ] }Check the "mode":
For Reset Skills, "mode" should be set to
indexingAllDocs(because potentially all documents are affected, in terms of the fields that are populated through AI enrichment).For Reset Documents, "mode" should be set to
indexingResetDocs. The indexer retains this status until all the document keys provided in the reset documents call are processed, during which time no other indexer jobs will execute while the operation is progressing. Finding all of the documents in the document keys list requires cracking each document to locate and match on the key, and this can take a while if the data set is large. If a blob container contains hundreds of blobs, and the docs you want to reset are at the end, the indexer won't find the matching blobs until all of the others have been checked first.After the documents are reprocessed, run Get Indexer Status again. The indexer returns to the
indexingAllDocsmode and will process any new or updated documents on the next run.
Next steps
Reset APIs are used to inform the scope of the next indexer run. For actual processing, you'll need to invoke an on-demand indexer run or allow a scheduled job to complete the work. After the run is finished, the indexer returns to normal processing, whether that is on a schedule or on-demand processing.
After you reset and rerun indexer jobs, you can monitor status from the search service, or obtain detailed information through resource logging.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for