Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article is a collection of tips and best practices for boosting query and indexing performance for keyword search. Knowing which factors are most likely to affect search performance can help you avoid inefficiencies and get the most out of your search service. Some key factors include:
- Index composition (schema and size)
- Query design
- Service capacity (tier, and the number of replicas and partitions)
Note
Looking for strategies on high volume indexing? See Index large data sets in Azure AI Search.
Index size and schema
Queries run faster on smaller indexes. This is partly a function of having fewer fields to scan, but it's also due to how the system caches content for future queries. After the first query, some content remains in memory where it's searched more efficiently. Because index size tends to grow over time, one best practice is to periodically revisit index composition, both schema and documents, to look for content reduction opportunities. However, if the index is right-sized, the only other calibration you can make is to increase capacity by upgrading your service, adding replicas, or switching to a higher pricing tier. The section "Tip: Switch to a Standard S2 tier" discusses the scale up versus scale out decision.
Schema complexity can also adversely affect indexing and query performance. Excessive field attribution builds in limitations and processing requirements. Complex types take longer to index and query. The next few sections explore each condition.
Tip: Be selective in field attribution
A common mistake that administrators and developers make when creating a search index is selecting all available properties for the fields, as opposed to only selecting just the properties that are needed. For example, if a field doesn't need to be full text searchable, skip that field when setting the searchable attribute.
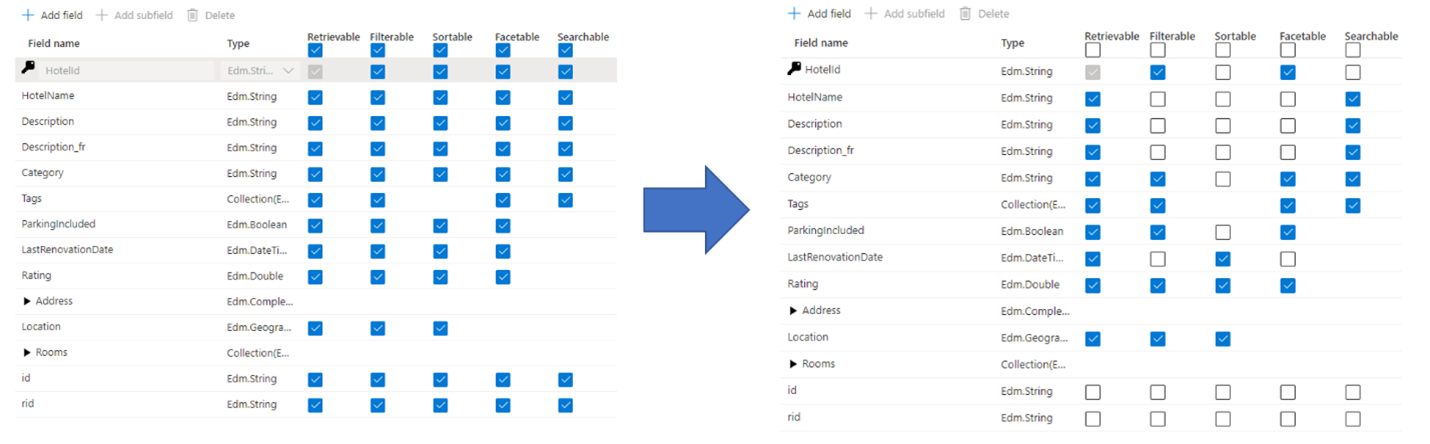
Support for filters, facets, and sorting can quadruple storage requirements. If you add suggesters, storage requirements go up even more. For an illustration on the impact of attributes on storage, see Attributes and index size.
Summarized, the ramifications of over-attribution include:
Degradation of indexing performance due to the extra work required to process the content in the field, and then store it within the search inverted index (set the "searchable" attribute only on fields that contain searchable content).
Creates a larger surface that each query has to cover. All fields marked as searchable are scanned in a full text search.
Increases operational costs due to extra storage. Filtering and sorting requires additional space for storing original (non-analyzed) strings. Avoid setting filterable or sortable on fields that don't need it.
In many cases, over attribution limits the capabilities of the field. For example, if a field is facetable, filterable, and searchable, you can only store 16 KB of text within a field, whereas a searchable field can hold up to 16 MB of text.
Note
Only unnecessary attribution should be avoided. Filters and facets are often essential to the search experience, and in cases where filters are used, you frequently need sorting so that you can order the results (filters by themselves return in an unordered set).
Tip: Consider alternatives to complex types
Complex data types are useful when data has a complicated nested structure, such as the parent-child elements found in JSON documents. The downside of complex types is the extra storage requirements and additional resources required to index the content, in comparison to non-complex data types.
In some cases, you can avoid these tradeoffs by mapping a complex data structure to a simpler field type, such as a Collection. Alternatively, you might opt for flattening a field hierarchy into individual root-level fields.

Query design
Query composition and complexity are one of the most important factors for performance, and query optimization can drastically improve performance. When designing queries, think about the following points:
Number of searchable fields. Each additional searchable field results in more work for the search service. You can limit the fields being searched at query time using the "searchFields" parameter. It's best to specify only the fields that you care about to improve performance.
Amount of data being returned. Retrieving a large amount content can make queries slower. When structuring a query, return only those fields that you need to render the results page, and then retrieve remaining fields using the Lookup API once a user selects a match.
Use of partial term searches. Partial term searches, such as prefix search, fuzzy search, and regular expression search, are more computationally expensive than typical keyword searches, as they require full index scans to produce results.
Number of facets. Adding facets to queries requires aggregations for each query. Requesting a higher "count" for a facet also requires extra work by the service. In general, only add the facets that you plan to render in your app and avoid requesting a high count for facets unless necessary.
High skip values. Setting the
$skipparameter to a high value (for example, in the thousands) increases search latency because the engine is retrieving and ranking a larger volume of documents for each request. For performance reasons, it's best to avoid high$skipvalues and use other techniques instead, such as filtering, to retrieve large numbers of documents.Limit high cardinality fields. A high cardinality field refers to a facetable or filterable field that has a significant number of unique values, and as a result, consumes significant resources when computing results. For example, setting a Product ID or Description field as facetable and filterable would count as high cardinality because most of the values from document to document are unique.
Tip: Use search functions instead overloading filter criteria
As a query uses increasingly complex filter criteria, the performance of the search query will degrade. Consider the following example that demonstrates the use of filters to trim results based on a user identity:
$filter= userid eq 123 or userid eq 234 or userid eq 345 or userid eq 456 or userid eq 567
In this case, the filter expressions are used to check whether a single field in each document is equal to one of many possible values of a user identity. You're most likely to find this pattern in applications that implement security trimming (checking a field containing one or more principal IDs against a list of principal IDs representing the user issuing the query).
A more efficient way to execute filters that contain a large number of values is to use search.in function, as shown in this example:
search.in(userid, '123,234,345,456,567', ',')
Tip: Add partitions for slow individual queries
When query performance is slowing down in general, adding more replicas frequently solves the issue. But what if the problem is a single query that takes too long to complete? In this scenario, adding replicas won't help, but more partitions might. A partition splits data across extra computing resources. Two partitions split data in half, a third partition splits it into thirds, and so forth.
One positive side-effect of adding partitions is that slower queries sometimes perform faster due to parallel computing. We've noted parallelization on low selectivity queries, such as queries that match many documents, or facets providing counts over a large number of documents. Since significant computation is required to score the relevancy of the documents, or to count the numbers of documents, adding extra partitions helps queries complete faster.
To add partitions, use the Azure portal, PowerShell, Azure CLI, or a management SDK.
Service capacity
A service is overburdened when queries take too long or when the service starts dropping requests. If this happens, you can address the problem by upgrading the service or by adding capacity.
The tier of your search service and the number of replicas/partitions also have a large impact on performance. Each progressively higher tier provides faster CPUs and more memory, both of which have a positive impact on performance.
Tip: Create a new high capacity search service
Basic and Standard services created in supported regions after April 3, 2024 have more storage per partition than older services. If you have an older service, check if you can upgrade your service to benefit from more capacity at the same billing rate. If an upgrade isn't available, review the tier service limits to see if the same tier on a newer service gives you the necessary storage.
Tip: Switch to a Standard S2 tier
The Standard S1 search tier is often where customers start. A common pattern for S1 services is that indexes grow over time, which requires more partitions. More partitions lead to slower response times, so more replicas are added to handle the query load. As you can imagine, the cost of running an S1 service has now progressed to levels beyond the initial configuration.
At this juncture, an important question to ask is whether it would be beneficial to switch to a higher pricing tier, as opposed to progressively increasing the number of partitions or replicas of the current service.
Consider the following topology as an example of a service that has taken on increasing levels of capacity:
- Standard S1 tier
- Index Size: 190 GB
- Partition Count: 8 (on S1, partition size is 25 GB per partition)
- Replica Count: 2
- Total Search Units: 16 (8 partitions x 2 replicas)
- Hypothetical Retail Price: ~$4,000 USD / month (assume 250 USD x 16 search units)
Suppose the service administrator is still seeing higher latency rates and is considering adding another replica. This would change the replica count from 2 to 3 and as a result change the Search Unit count to 24 and a resulting price of $6,000 USD/month.
However, if the administrator chose to move to a Standard S2 tier the topology would look like:
- Standard S2 tier
- Index Size: 190 GB
- Partition Count: 2 (on S2, partition size is 100 GB per partition)
- Replica Count: 2
- Total Search Units: 4 (2 partitions x 2 replicas)
- Hypothetical Retail Price: ~$4,000 USD / month (1,000 USD x 4 search units)
As this hypothetical scenario illustrates, you can have configurations on lower tiers that result in similar costs as if you had opted for a higher tier in the first place. However, higher tiers come with premium storage, which makes indexing faster. Higher tiers also have much more compute power, as well as extra memory. For the same costs, you could have more powerful infrastructure backing the same index.
An important benefit of added memory is that more of the index can be cached, resulting in lower search latency, and a greater number of queries per second. With this extra power, the administrator might not need to even need to increase the replica count and could potentially pay less than by staying on the S1 service.
Tip: Consider alternatives to regular expression queries
Regular expression queries or regex can be particularly expensive. While they can be very useful for advanced searches, execution can require a lot of processing power, especially if the regular expression is complicated or if you're searching through a large amount of data. All of these factors contribute to high search latency. As a mitigation, try to simplify the regular expression or break the complex query down into smaller, more manageable queries.
Next steps
Review these other articles related to service performance: