Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Placement policies are additional rules that can be used to govern service placement in some specific, less-common scenarios. Some examples of those scenarios are:
- Your Service Fabric cluster spans geographic distances, such as multiple on-premises datacenters or across Azure regions
- Your environment spans multiple areas of geopolitical or legal control, or some other case where you have policy boundaries you need to enforce
- There are communication performance or latency considerations due to large distances or use of slower or less reliable network links
- You need to keep certain workloads collocated as a best effort, either with other workloads or in proximity to customers
- You need multiple stateless instances of a partition on a single node
Most of these requirements align with the physical layout of the cluster, represented as the fault domains of the cluster.
The advanced placement policies that help address these scenarios are:
- Invalid domains
- Required domains
- Preferred domains
- Disallowing replica packing
- Allow multiple stateless instances on node
Most of the following controls could be configured via node properties and placement constraints, but some are more complicated. To make things simpler, the Service Fabric Cluster Resource Manager provides these additional placement policies. Placement policies are configured on a per-named service instance basis. They can also be updated dynamically.
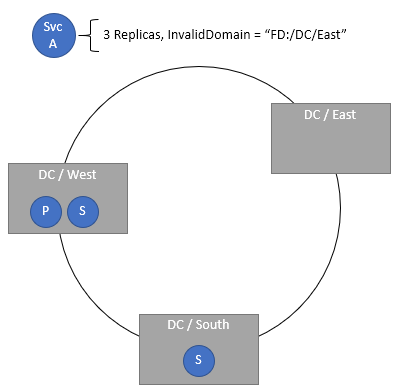
Specifying invalid domains
The InvalidDomain placement policy allows you to specify that a particular Fault Domain is invalid for a specific service. This policy ensures that a particular service never runs in a particular area, for example for geopolitical or corporate policy reasons. Multiple invalid domains may be specified via separate policies.
Code:
ServicePlacementInvalidDomainPolicyDescription invalidDomain = new ServicePlacementInvalidDomainPolicyDescription();
invalidDomain.DomainName = "fd:/DCEast"; //regulations prohibit this workload here
serviceDescription.PlacementPolicies.Add(invalidDomain);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementPolicy @("InvalidDomain,fd:/DCEast”)
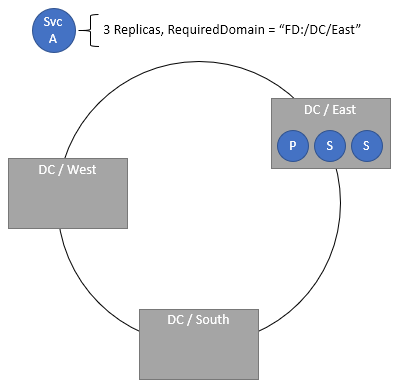
Specifying required domains
The required domain placement policy requires that the service is present only in the specified domain. Multiple required domains can be specified via separate policies.
Code:
ServicePlacementRequiredDomainPolicyDescription requiredDomain = new ServicePlacementRequiredDomainPolicyDescription();
requiredDomain.DomainName = "fd:/DC01/RK03/BL2";
serviceDescription.PlacementPolicies.Add(requiredDomain);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementPolicy @("RequiredDomain,fd:/DC01/RK03/BL2")
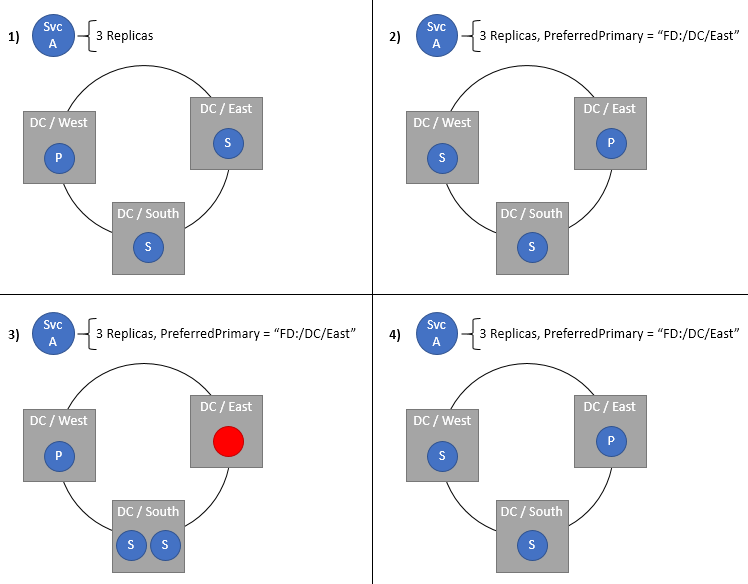
Specifying a preferred domain for the primary replicas of a stateful service
The Preferred Primary Domain specifies the fault domain to place the Primary in. The Primary ends up in this domain when everything is healthy. If the domain or the Primary replica fails or shuts down, the Primary moves to some other location, ideally in the same domain. If this new location isn't in the preferred domain, the Cluster Resource Manager moves it back to the preferred domain as soon as possible. Naturally this setting only makes sense for stateful services. This policy is most useful in clusters that are spanned across Azure regions or multiple datacenters but have services that prefer placement in a certain location. Keeping Primaries close to their users or other services helps provide lower latency, especially for reads, which are handled by Primaries by default.
ServicePlacementPreferPrimaryDomainPolicyDescription primaryDomain = new ServicePlacementPreferPrimaryDomainPolicyDescription();
primaryDomain.DomainName = "fd:/EastUS/";
serviceDescription.PlacementPolicies.Add(primaryDomain);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementPolicy @("PreferredPrimaryDomain,fd:/EastUS")
Requiring replica distribution and disallowing packing
Replicas are normally distributed across fault and upgrade domains when the cluster is healthy. However, there are cases where more than one replica for a given partition may end up temporarily packed into a single domain. For example, let's say that the cluster has nine nodes in three fault domains, fd:/0, fd:/1, and fd:/2. Let's also say that your service has three replicas. Let's say that the nodes that were being used for those replicas in fd:/1 and fd:/2 went down. Normally the Cluster Resource Manager would prefer other nodes in those same fault domains. In this case, let's say due to capacity issues none of the other nodes in those domains were valid. If the Cluster Resource Manager builds replacements for those replicas, it would have to choose nodes in fd:/0. However, doing that creates a situation where the Fault Domain constraint is violated. Packing replicas increases the chance that the whole replica set could go down or be lost.
Note
For more information on constraints and constraint priorities generally, check out this topic.
If you've ever seen a health message such as "The Load Balancer has detected a Constraint Violation for this Replica:fabric:/<some service name> Secondary Partition <some partition ID> is violating the Constraint: FaultDomain", then you've hit this condition or something like it. Usually only one or two replicas are packed together temporarily. So long as there is fewer than a quorum of replicas in a given domain, you're safe. Packing is rare, but it can happen, and usually these situations are transient since the nodes come back. If the nodes do stay down and the Cluster Resource Manager needs to build replacements, usually there are other nodes available in the ideal fault domains.
Some workloads would prefer always having the target number of replicas, even if they are packed into fewer domains. These workloads are betting against total simultaneous permanent domain failures and can usually recover local state. Other workloads would rather take the downtime earlier than risk correctness or loss of data. Most production workloads run with more than three replicas, more than three fault domains, and many valid nodes per fault domain. Because of this, the default behavior allows domain packing by default. The default behavior allows normal balancing and failover to handle these extreme cases, even if that means temporary domain packing.
If you want to disable such packing for a given workload, you can specify the RequireDomainDistribution policy on the service. When this policy is set, the Cluster Resource Manager ensures no two replicas from the same partition run in the same fault or upgrade domain.
Code:
ServicePlacementRequireDomainDistributionPolicyDescription distributeDomain = new ServicePlacementRequireDomainDistributionPolicyDescription();
serviceDescription.PlacementPolicies.Add(distributeDomain);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementPolicy @("RequiredDomainDistribution")
Now, would it be possible to use these configurations for services in a cluster that was not geographically spanned? You could, but there’s not a great reason too. The required, invalid, and preferred domain configurations should be avoided unless the scenarios require them. It doesn't make any sense to try to force a given workload to run in a single rack, or to prefer some segment of your local cluster over another. Different hardware configurations should be spread across fault domains and handled via normal placement constraints and node properties.
Placement of multiple stateless instances of a partition on single node
The AllowMultipleStatelessInstancesOnNode placement policy allows placement of multiple stateless instances of a partition on a single node. By default, multiple instances of a single partition cannot be placed on a node. Even with a -1 service, it is not possible to scale the number of instances beyond the number of nodes in the cluster, for a given named service. This placement policy removes this restriction and allows InstanceCount to be specified higher than node count.
If you've ever seen a health message such as "The Load Balancer has detected a Constraint Violation for this Replica:fabric:/<some service name> Secondary Partition <some partition ID> is violating the Constraint: ReplicaExclusion", then you've hit this condition or something like it.
To opt in to apply this placement policy on your service, enable the following configurations:
<Section Name="Common">
<Parameter Name="AllowCreateUpdateMultiInstancePerNodeServices" Value="True" />
<Parameter Name="HostReuseModeForExclusiveStateless" Value="1" />
</Section>
By specifying the AllowMultipleStatelessInstancesOnNode policy on the service, InstanceCount can be set beyond the number of nodes in the cluster.
Code:
ServicePlacementAllowMultipleStatelessInstancesOnNodePolicyDescription allowMultipleInstances = new ServicePlacementAllowMultipleStatelessInstancesOnNodePolicyDescription();
serviceDescription.PlacementPolicies.Add(allowMultipleInstances);
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName -Stateless –PartitionSchemeSingleton –PlacementPolicy @(“AllowMultipleStatelessInstancesOnNode”) -InstanceCount 10 -ServicePackageActivationMode ExclusiveProcess
Note
Currently the policy is only supported for Stateless services with ExclusiveProcess service package activation mode.
Warning
The policy is not supported when used with static port endpoints. Using both in conjunction can lead to an unhealthy cluster as multiple instances on the same node try to bind to the same port, and cannot come up.
Note
Using a high value of MinInstanceCount with this placement policy can lead to stuck Application Upgrades. For example, if you have a five-node cluster and set InstanceCount=10, you will have two instances on each node. If you set MinInstanceCount=9, an attempted app upgrade can get stuck; with MinInstanceCount=8, this can be avoided.
Next steps
- For more information on configuring services, Learn about configuring Services