StorSimple 1200 migration to Azure File Sync
StorSimple 1200 series is a virtual appliance that runs in an on-premises data center. It's possible to migrate the data from this appliance to an Azure File Sync environment. Azure File Sync is the default and strategic long-term Azure service that StorSimple appliances can be migrated to. This article provides the background knowledge and migrations steps for a successful migration to Azure File Sync.
Note
The StorSimple Service (including the StorSimple Device Manager for 8000 and 1200 series and StorSimple Data Manager) has reached the end of support. The end of support for StorSimple was published in 2019 on the Microsoft LifeCycle Policy and Azure Communications pages. Additional notifications were sent via email and posted on the Azure portal and in the StorSimple overview. Contact Microsoft Support for additional details.
Applies to
| File share type | SMB | NFS |
|---|---|---|
| Standard file shares (GPv2), LRS/ZRS | ||
| Standard file shares (GPv2), GRS/GZRS | ||
| Premium file shares (FileStorage), LRS/ZRS |
Azure File Sync
Azure File Sync is a Microsoft cloud service, based on two main components:
- File synchronization and cloud tiering.
- File shares as native storage in Azure that can be accessed over multiple protocols like SMB and FileREST. An Azure file share is comparable to a file share on a Windows Server that you can natively mount as a network drive. It supports important file fidelity aspects like attributes, permissions, and timestamps. Unlike with StorSimple, no application/service is required to interpret the files and folders stored in the cloud. The ideal and most flexible approach is to store general purpose file server data and some application data in the cloud.
This article focuses on the migration steps. If you'd like to learn more about Azure File Sync, we recommend the following articles:
Migration goals
The goal is to guarantee the integrity of the production data and guaranteeing availability. The latter requires keeping downtime to a minimum so that it can fit into or only slightly exceed regular maintenance windows.
StorSimple 1200 migration path to Azure File Sync
A local Windows Server is required to run an Azure File Sync agent. The Windows Server can be at a minimum a 2012R2 server but ideally is a Windows Server 2019.
There are numerous, alternative migration paths, and it would create too long of an article to document all of them and illustrate why they bear risk or disadvantages over the route we recommend as a best practice in this article.
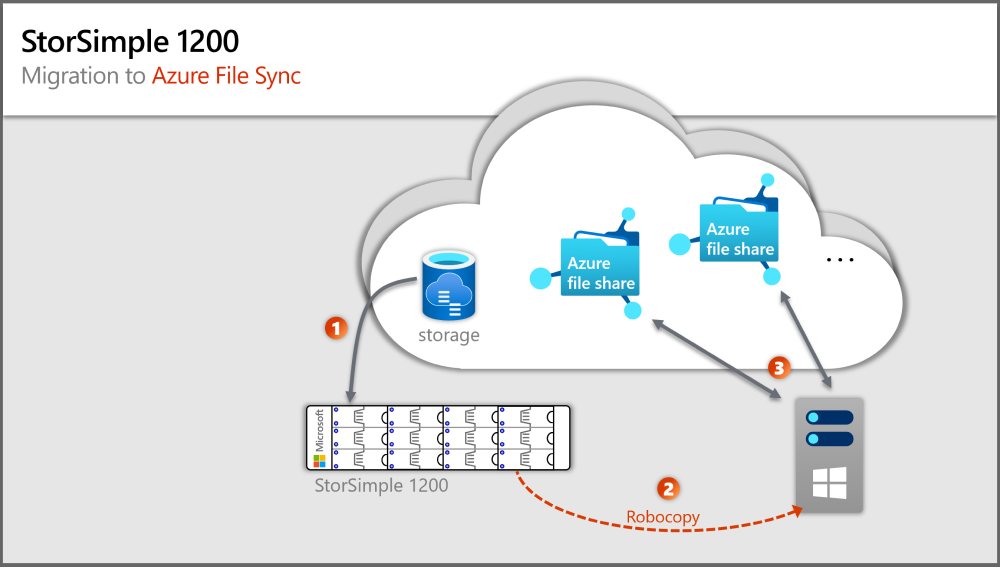
The previous image depicts steps that correspond to sections in this article.
Step 1: Provision your on-premises Windows Server and storage
- Create a Windows Server 2019 - at a minimum 2012R2 - as a virtual machine (VM) or physical server. A Windows Server failover cluster is also supported.
- Provision or add Direct Attached Storage (DAS as compared to NAS, which isn't supported). The size of the Windows Server storage must be equal to or larger than the size of the available capacity of your virtual StorSimple 1200 appliance.
Step 2: Configure your Windows Server storage
In this step, you map your StorSimple storage structure (volumes and shares) to your Windows Server storage structure. If you plan to make changes to your storage structure, meaning the number of volumes, the association of data folders to volumes, or the subfolder structure above or below your current SMB/NFS shares, then now is the time to take these changes into consideration. Changing your file and folder structure after Azure File Sync is configured is cumbersome and should be avoided. This article assumes you're mapping 1:1, so you must take your mapping changes into consideration when you follow the steps in this article.
- None of your production data should end up on the Windows Server system volume. Cloud tiering isn't supported on system volumes. However, this feature is required for the migration as well as continuous operations as a StorSimple replacement.
- Provision the same number of volumes on your Windows Server as you have on your StorSimple 1200 virtual appliance.
- Configure any Windows Server roles, features, and settings you need. We recommend you opt into Windows Server updates to keep your operating system safe and up to date. Similarly, we recommend opting into Microsoft Update to keep Microsoft applications up to date, including the Azure File Sync agent.
- Don't configure any folders or shares before reading the following steps.
Step 3: Deploy the first Azure File Sync cloud resource
To complete this step, you need your Azure subscription credentials.
The core resource to configure for Azure File Sync is called a Storage Sync Service. We recommend that you deploy only one for all servers that are syncing the same set of files now or in the future. Create multiple Storage Sync Services only if you have distinct sets of servers that must never exchange data. For example, you might have servers that must never sync the same Azure file share. Otherwise, using a single Storage Sync Service is the best practice.
Choose an Azure region for your Storage Sync Service that's close to your location. All other cloud resources must be deployed in the same region. To simplify management, create a new resource group in your subscription that houses sync and storage resources.
For more information, see the section about deploying the Storage Sync Service in the article about deploying Azure File Sync. Follow only this section of the article. There will be links to other sections of the article in later steps.
Step 4: Match your local volume and folder structure to Azure File Sync and Azure file share resources
In this step, you'll determine how many Azure file shares you need. A single Windows Server instance (or cluster) can sync up to 30 Azure file shares.
You might have more folders on your volumes that you currently share out locally as SMB shares to your users and apps. The easiest way to picture this scenario is to envision an on-premises share that maps 1:1 to an Azure file share. If you have a small enough number of shares, below 30 for a single Windows Server instance, we recommend a 1:1 mapping.
If you have more than 30 shares, mapping an on-premises share 1:1 to an Azure file share is often unnecessary. Consider the following options.
Share grouping
For example, if your human resources (HR) department has 15 shares, you might consider storing all the HR data in a single Azure file share. Storing multiple on-premises shares in one Azure file share doesn't prevent you from creating the usual 15 SMB shares on your local Windows Server instance. It only means that you organize the root folders of these 15 shares as subfolders under a common folder. You then sync this common folder to an Azure file share. That way, only a single Azure file share in the cloud is needed for this group of on-premises shares.
Volume sync
Azure File Sync supports syncing the root of a volume to an Azure file share. If you sync the volume root, all subfolders and files will go to the same Azure file share.
Syncing the root of the volume isn't always the best option. There are benefits to syncing multiple locations. For example, doing so helps keep the number of items lower per sync scope. We test Azure file shares and Azure File Sync with 100 million items (files and folders) per share. But a best practice is to try to keep the number below 20 million or 30 million in a single share. Setting up Azure File Sync with a lower number of items isn't beneficial only for file sync. A lower number of items also benefits scenarios like these:
- Initial scan of the cloud content can complete faster, which in turn decreases the wait for the namespace to appear on a server enabled for Azure File Sync.
- Cloud-side restore from an Azure file share snapshot will be faster.
- Disaster recovery of an on-premises server can speed up significantly.
- Changes made directly in an Azure file share (outside of sync) can be detected and synced faster.
Tip
If you don't know how many files and folders you have, check out the TreeSize tool from JAM Software GmbH.
A structured approach to a deployment map
Before you deploy cloud storage in a later step, it's important to create a map between on-premises folders and Azure file shares. This mapping will inform how many and which Azure File Sync sync group resources you'll provision. A sync group ties the Azure file share and the folder on your server together and establishes a sync connection.
To decide how many Azure file shares you need, review the following limits and best practices. Doing so will help you optimize your map.
A server on which the Azure File Sync agent is installed can sync with up to 30 Azure file shares.
An Azure file share is deployed in a storage account. That arrangement makes the storage account a scale target for performance numbers like IOPS and throughput.
Pay attention to a storage account's IOPS limitations when deploying Azure file shares. Ideally, you should map file shares 1:1 with storage accounts. However, this might not always be possible due to various limits and restrictions, both from your organization and from Azure. When it's not possible to have only one file share deployed in one storage account, consider which shares will be highly active and which shares will be less active to ensure that the hottest file shares don't get put in the same storage account together.
If you plan to lift an app to Azure that will use the Azure file share natively, you might need more performance from your Azure file share. If this type of use is a possibility, even in the future, it's best to create a single standard Azure file share in its own storage account.
There's a limit of 250 storage accounts per subscription per Azure region.
Tip
Given this information, it often becomes necessary to group multiple top-level folders on your volumes into a new common root directory. You then sync this new root directory, and all the folders you grouped into it, to a single Azure file share. This technique allows you to stay within the limit of 30 Azure file share syncs per server.
This grouping under a common root doesn't affect access to your data. Your ACLs stay as they are. You only need to adjust any share paths (like SMB or NFS shares) you might have on the local server folders that you now changed into a common root. Nothing else changes.
Important
The most important scale vector for Azure File Sync is the number of items (files and folders) that need to be synced. Review the Azure File Sync scale targets for more details.
It's a best practice to keep the number of items per sync scope low. That's an important factor to consider in your mapping of folders to Azure file shares. Azure File Sync is tested with 100 million items (files and folders) per share. But it's often best to keep the number of items below 20 million or 30 million in a single share. Split your namespace into multiple shares if you start to exceed these numbers. You can continue to group multiple on-premises shares into the same Azure file share if you stay roughly below these numbers. This practice will provide you with room to grow.
It's possible that, in your situation, a set of folders can logically sync to the same Azure file share (by using the new common root folder approach mentioned earlier). But it might still be better to regroup folders so they sync to two instead of one Azure file share. You can use this approach to keep the number of files and folders per file share balanced across the server. You can also split your on-premises shares and sync across more on-premises servers, adding the ability to sync with 30 more Azure file shares per extra server.
Common file sync scenarios and considerations
| # | Sync scenario | Supported | Considerations (or limitations) | Solution (or workaround) |
|---|---|---|---|---|
| 1 | File server with multiple disks/volumes and multiple shares to same target Azure file share (consolidation) | No | A target Azure file share (cloud endpoint) only supports syncing with one sync group. A sync group only supports one server endpoint per registered server. |
1) Start with syncing one disk (its root volume) to target Azure file share. Starting with largest disk/volume will help with storage requirements on-premises. Configure cloud tiering to tier all data to cloud, thereby freeing up space on the file server disk. Move data from other volumes/shares into the current volume which is syncing. Continue the steps one by one until all data is tiered up to cloud/migrated. 2) Target one root volume (disk) at a time. Use cloud tiering to tier all data to target Azure file share. Remove server endpoint from sync group, re-create the endpoint with the next root volume/disk, sync, and repeat the process. Note: Agent re-install might be required. 3) Recommend using multiple target Azure file shares (same or different storage account based on performance requirements) |
| 2 | File server with single volume and multiple shares to same target Azure file share (consolidation) | Yes | Can't have multiple server endpoints per registered server syncing to same target Azure file share (same as above) | Sync root of the volume holding multiple shares or top-level folders. Refer to Share grouping concept and Volume sync for more information. |
| 3 | File server with multiple shares and/or volumes to multiple Azure file shares under single storage account (1:1 share mapping) | Yes | A single Windows Server instance (or cluster) can sync up to 30 Azure file shares. A storage account is a scale target for performance. IOPS and throughput get shared across file shares. Keep number of items per sync group within 100 million items (files and folders) per share. Ideally it's best to stay below 20 or 30 million per share. |
1) Use multiple sync groups (number of sync groups = number of Azure file shares to sync to). 2) Only 30 shares can be synced in this scenario at a time. If you have more than 30 shares on that file server, use Share grouping concept and Volume sync to reduce the number of root or top-level folders at source. 3) Use additional File Sync servers on-premises and split/move data to these servers to work around limitations on the source Windows server. |
| 4 | File server with multiple shares and/or volumes to multiple Azure file shares under different storage account (1:1 share mapping) | Yes | A single Windows Server instance (or cluster) can sync up to 30 Azure file shares (same or different storage account). Keep number of items per sync group within 100 million items (files and folders) per share. Ideally it's best to stay below 20 or 30 million per share. |
Same approach as above |
| 5 | Multiple file servers with single (root volume or share) to same target Azure file share (consolidation) | No | A sync group can't use cloud endpoint (Azure file share) already configured in another sync group. Although a sync group can have server endpoints on different file servers, the files can't be distinct. |
Follow guidance in Scenario # 1 above with additional consideration of targeting one file server at a time. |
Create a mapping table

Use the previous information to determine how many Azure file shares you need and which parts of your existing data will end up in which Azure file share.
Create a table that records your thoughts so you can refer to it when you need to. Staying organized is important because it can be easy to lose details of your mapping plan when you're provisioning many Azure resources at once. Download the following Excel file to use as a template to help create your mapping.

|
Download a namespace-mapping template. |
Step 5: Provision Azure file shares
An Azure file share is stored in the cloud in an Azure storage account. Another level of performance considerations applies here.
If you have highly active shares (shares used by many users and/or applications), two Azure file shares might reach the performance limit of a storage account.
A best practice is to deploy storage accounts with one file share each. You can pool multiple Azure file shares into the same storage account if you have archival shares or you expect low day-to-day activity in them.
These considerations apply more to direct cloud access (through an Azure VM) than to Azure File Sync. If you plan to use only Azure File Sync on these shares, grouping several into a single Azure storage account is fine.
If you've made a list of your shares, you should map each share to the storage account it will be in.
In the previous phase, you determined the appropriate number of shares. In this step, you have a mapping of storage accounts to file shares. Now deploy the appropriate number of Azure storage accounts with the appropriate number of Azure file shares in them.
Make sure the region of each of your storage accounts is the same and matches the region of the Storage Sync Service resource you've already deployed.
Caution
If you create an Azure file share that has a 100 TiB limit, that share can use only locally redundant storage or zone-redundant storage redundancy options. Consider your storage redundancy needs before using 100 TiB file shares.
Azure file shares are still created with a 5 TiB limit by default. Follow the steps in Create an Azure file share to create a large file share.
Another consideration when you're deploying a storage account is the redundancy of Azure Storage. See Azure Storage redundancy options.
The names of your resources are also important. For example, if you group multiple shares for the HR department into an Azure storage account, you should name the storage account appropriately. Similarly, when you name your Azure file shares, you should use names similar to the ones used for their on-premises counterparts.
Storage account settings
There are many configurations you can make on a storage account. The following checklist should be used for your storage account configurations. For example, you can change the networking configuration after your migration is complete.
- Firewall and virtual networks: Disabled - don't configure any IP restrictions or limit storage account access to a specific virtual network. The public endpoint of the storage account is used during the migration. All IP addresses from Azure VMs must be allowed. It's best to configure any firewall rules on the storage account after the migration.
- Private Endpoints: Supported - You can enable private endpoints, but the public endpoint is used for the migration and must remain available.
Step 6: Configure Windows Server target folders
In previous steps, you considered all aspects that will determine the components of your sync topologies. Now it's time to prepare the server to receive files for upload.
Create all folders that will sync each to their own Azure file share. It's important that you follow the folder structure you've documented earlier. If for example you decided to sync multiple, local SMB shares together into a single Azure file share, then you must place them under a common root folder on the volume. Create this target root folder on the volume now.
The number of Azure file shares you provision should match the number of folders you've created in this step plus the number of volumes you want to sync at the root level.
Step 7: Deploy the Azure File Sync agent
In this section, you install the Azure File Sync agent on your Windows Server instance.
The deployment guide explains that you need to turn off Internet Explorer Enhanced Security Configuration. This security measure isn't applicable with Azure File Sync. Turning it off allows you to authenticate to Azure without any problems.
Open PowerShell. Install the required PowerShell modules by using the following commands. Be sure to install the full module and the NuGet provider when you're prompted to do so.
Install-Module -Name Az -AllowClobber
Install-Module -Name Az.StorageSync
If you have any problems reaching the internet from your server, now is the time to solve them. Azure File Sync uses any available network connection to the internet. Requiring a proxy server to reach the internet is also supported. You can either configure a machine-wide proxy now or, during agent installation, specify a proxy that only Azure File Sync will use.
If configuring a proxy means you need to open your firewalls for the server, that approach might be acceptable to you. At the end of the server installation, after you've completed server registration, a network connectivity report will show you the exact endpoint URLs in Azure that Azure File Sync needs to communicate with for the region you've selected. The report also tells you why communication is needed. You can use the report to lock down the firewalls around the server to specific URLs.
You can also take a more conservative approach in which you don't open the firewalls wide. You can instead limit the server to communicate with higher-level DNS namespaces. For more information, see Azure File Sync proxy and firewall settings. Follow your own networking best practices.
At the end of the server installation wizard, a server registration wizard will open. Register the server to your Storage Sync Service's Azure resource from earlier.
These steps are described in more detail in the deployment guide, which includes the PowerShell modules that you should install first: Azure File Sync agent installation.
Use the latest agent. You can download it from the Microsoft Download Center: Azure File Sync Agent.
After a successful installation and server registration, you can confirm that you've successfully completed this step. Go to the Storage Sync Service resource in the Azure portal. In the left menu, go to Registered servers. You'll see your server listed there.
Step 8: Configure sync
This step ties together all the resources and folders you've set up on your Windows Server instance during the previous steps.
- Sign in to the Azure portal.
- Locate your Storage Sync Service resource.
- Create a new sync group within the Storage Sync Service resource for each Azure file share. In Azure File Sync terminology, the Azure file share will become a cloud endpoint in the sync topology that you're describing with the creation of a sync group. When you create the sync group, give it a familiar name so that you recognize which set of files syncs there. Make sure you reference the Azure file share with a matching name.
- After you create the sync group, a row for it will appear in the list of sync groups. Select the name (a link) to display the contents of the sync group. You'll see your Azure file share under Cloud endpoints.
- Locate the Add Server Endpoint button. The folder on the local server that you've provisioned will become the path for this server endpoint.
Warning
Be sure to turn on cloud tiering! This is required if your local server doesn't have enough space to store the total size of your data in the StorSimple cloud storage. Set your tiering policy temporarily to 99% volume free space, and change it back to a more reasonable level after the migration is complete.
Repeat the steps of sync group creation and addition of the matching server folder as a server endpoint for all Azure file shares/server locations that must be configured for sync.
Step 9: Copy your files
The basic migration approach is a RoboCopy from your StorSimple virtual appliance to your Windows Server, and Azure File Sync to Azure file shares.
Run the first local copy to your Windows Server target folder:
- Identify the first location on your virtual StorSimple appliance.
- Identify the matching folder on the Windows Server that already has Azure File Sync configured on it.
- Start the copy using RoboCopy
The following RoboCopy command will recall files from your StorSimple Azure storage to your local StorSimple and then move them over to the Windows Server target folder. The Windows Server will sync it to the Azure file share(s). As the local Windows Server volume gets full, cloud tiering will kick in and tier files that have successfully synced already. Cloud tiering will generate enough space to continue the copy from the StorSimple virtual appliance. Cloud tiering checks once an hour to see what has synced and to free up disk space to reach the 99% volume free space.
robocopy <SourcePath> <Dest.Path> /MT:20 /R:2 /W:1 /B /MIR /IT /COPY:DATSO /DCOPY:DAT /NP /NFL /NDL /XD "System Volume Information" /UNILOG:<FilePathAndName>
| Switch | Meaning |
|---|---|
/MT:n |
Allows Robocopy to run multithreaded. Default for n is 8. The maximum is 128 threads. While a high thread count helps saturate the available bandwidth, it doesn't mean your migration will always be faster with more threads. Tests with Azure Files indicate between 8 and 20 shows balanced performance for an initial copy run. Subsequent /MIR runs are progressively affected by available compute vs available network bandwidth. For subsequent runs, match your thread count value more closely to your processor core count and thread count per core. Consider whether cores need to be reserved for other tasks that a production server might have. Tests with Azure Files have shown that up to 64 threads produce a good performance, but only if your processors can keep them alive at the same time. |
/R:n |
Maximum retry count for a file that fails to copy on first attempt. Robocopy will try n times before the file permanently fails to copy in the run. You can optimize the performance of your run: Choose a value of two or three if you believe timeout issues caused failures in the past. This may be more common over WAN links. Choose no retry or a value of one if you believe the file failed to copy because it was actively in use. Trying again a few seconds later may not be enough time for the in-use state of the file to change. Users or apps holding the file open may need hours more time. In this case, accepting the file wasn't copied and catching it in one of your planned, subsequent Robocopy runs, may succeed in eventually copying the file successfully. That helps the current run to finish faster without being prolonged by many retries that ultimately end up in a majority of copy failures due to files still open past the retry timeout. |
/W:n |
Specifies the time Robocopy waits before attempting to copy a file that didn't successfully copy during a previous attempt. n is the number of seconds to wait between retries. /W:n is often used together with /R:n. |
/B |
Runs Robocopy in the same mode that a backup application would use. This switch allows Robocopy to move files that the current user doesn't have permissions for. The backup switch depends on running the Robocopy command in an administrator elevated console or PowerShell window. If you use Robocopy for Azure Files, make sure you mount the Azure file share using the storage account access key vs. a domain identity. If you don't, the error messages might not intuitively lead you to a resolution of the problem. |
/MIR |
(Mirror source to target.) Allows Robocopy to copy only deltas between source and target. Empty subdirectories will be copied. Items (files or folders) that have changed or don't exist on the target will be copied. Items that exist on the target but not on the source will be purged (deleted) from the target. When you use this switch, match the source and target folder structures exactly. Matching means copying from the correct source and folder level to the matching folder level on the target. Only then can a "catch up" copy be successful. When source and target are mismatched, using /MIR will lead to large-scale deletions and recopies. |
/IT |
Ensures fidelity is preserved in certain mirror scenarios. For example, if a file experiences an ACL change and an attribute update between two Robocopy runs, it's marked hidden. Without /IT, the ACL change might be missed by Robocopy and not transferred to the target location. |
/COPY:[copyflags] |
The fidelity of the file copy. Default: /COPY:DAT. Copy flags: D= Data, A= Attributes, T= Timestamps, S= Security = NTFS ACLs, O= Owner information, U= Auditing information. Auditing information can't be stored in an Azure file share. |
/DCOPY:[copyflags] |
Fidelity for the copy of directories. Default: /DCOPY:DA. Copy flags: D= Data, A= Attributes, T= Timestamps. |
/NP |
Specifies that the progress of the copy for each file and folder won't be displayed. Displaying the progress significantly lowers copy performance. |
/NFL |
Specifies that file names aren't logged. Improves copy performance. |
/NDL |
Specifies that directory names aren't logged. Improves copy performance. |
/XD |
Specifies directories to be excluded. When running Robocopy on the root of a volume, consider excluding the hidden System Volume Information folder. If used as designed, all information in there is specific to the exact volume on this exact system and can be rebuilt on-demand. Copying this information won't be helpful in the cloud or when the data is ever copied back to another Windows volume. Leaving this content behind should not be considered data loss. |
/UNILOG:<file name> |
Writes status to the log file as Unicode. (Overwrites the existing log.) |
/L |
Only for a test run Files are to be listed only. They won't be copied, not deleted, and not time stamped. Often used with /TEE for console output. Flags from the sample script, like /NP, /NFL, and /NDL, might need to be removed to achieve you properly documented test results. |
/LFSM |
Only for targets with tiered storage. Not supported when the destination is a remote SMB share. Specifies that Robocopy operates in "low free space mode." This switch is useful only for targets with tiered storage that might run out of local capacity before Robocopy finishes. It was added specifically for use with a target enabled for Azure File Sync cloud tiering. It can be used independently of Azure File Sync. In this mode, Robocopy will pause whenever a file copy would cause the destination volume's free space to go below a "floor" value. This value can be specified by the /LFSM:n form of the flag. The parameter n is specified in base 2: nKB, nMB, or nGB. If /LFSM is specified with no explicit floor value, the floor is set to 10 percent of the destination volume's size. Low free space mode isn't compatible with /MT, /EFSRAW, or /ZB. Support for /B was added in Windows Server 2022. Please see section Windows Server 2022 and RoboCopy LFSM below for more information including detail about a related bug and workaround. |
/Z |
Use cautiously Copies files in restart mode. This switch is recommended only in an unstable network environment. It significantly reduces copy performance because of extra logging. |
/ZB |
Use cautiously Uses restart mode. If access is denied, this option uses backup mode. This option significantly reduces copy performance because of checkpointing. |
Important
We recommend using a Windows Server 2022. When using a Windows Server 2019, ensure at the latest patch level or at least OS update KB5005103 is installed. It contains important fixes for certain Robocopy scenarios.
When you run the RoboCopy command for the first time, your users and applications are still accessing the StorSimple files and folders and can potentially make changes. It's possible that RoboCopy has processed a directory, moved on to the next, and then a user on the source location (StorSimple) adds, changes, or deletes a file that now won't be processed in this current RoboCopy run. That's fine.
The first run is about moving the bulk of the data back to on-premises, over to your Windows Server, and back up into the cloud via Azure File Sync. This can take a long time, depending on:
- your download bandwidth
- the recall speed of the StorSimple cloud service
- the upload bandwidth
- the number of items (files and folders) that must be processed by either service
Once the initial run is complete, run the command again.
The second time it will finish faster, because it only needs to transport changes that happened since the last run. Those changes are likely local to the StorSimple already, because they are recent. That further reduces the time because the need for recall from the cloud is reduced. Still, new changes can accumulate during this second run.
Repeat this process until you're satisfied that the amount of time it takes to complete is an acceptable amount of downtime.
When you've consider the acceptable downtime and you're prepared to take the StorSimple location offline, then do so now. For example, remove the SMB share so that no user can access the folder, or take any other appropriate step that prevents content to change in this folder on StorSimple.
Run one last RoboCopy round. This will pick up any changes that might have been missed. How long this final step takes depends on the speed of the RoboCopy scan. You can estimate the time (which is equal to your downtime) by measuring how long the previous run took.
Create a share on the Windows Server folder and possibly adjust your DFS-N deployment to point to it. Be sure to set the same share-level permissions as on your StorSimple SMB share.
You've now finished migrating a share or group of shares into a common root or volume, depending on what you mapped previously.
You can try to run a few of these copies in parallel. We recommend processing the scope of one Azure file share at a time.
Warning
Once you've moved all the data from you StorSimple to the Windows Server and your migration is complete: Return to all sync groups in the Azure portal and adjust the cloud tiering volume free space percent value to something better suited for cache utilization, for example 20%.
The cloud tiering volume free space policy acts on a volume level with potentially multiple server endpoints syncing from it. If you forget to adjust the free space on even one server endpoint, sync will continue to apply the most restrictive rule and attempt to keep 99% free disk space, and the local cache won't perform as you might expect. Unless it's your goal to only have the namespace for a volume that only contains rarely accessed, archival data, you'll need to adjust the free space policy on every server endpoint.
Troubleshoot
The most likely issue you can run into is that the RoboCopy command fails with "Volume full" on the Windows Server side. If that happens, then your download speed is likely better than your upload speed. Cloud tiering acts once every hour to evacuate content from the local Windows Server disk that has synced.
Let sync progress and cloud tiering free up disk space. You can observe that in File Explorer on your Windows Server.
When your Windows Server has sufficient available capacity, rerunning the command will resolve the problem. Nothing breaks when you get into this situation, and you can move forward with confidence. The inconvenience of running the command again is the only consequence.
You might also run into other Azure File Sync issues. If that happens, see Azure File Sync troubleshooting guide.
Speed and success rate of a given RoboCopy run will depend on several factors:
- IOPS on the source and target storage
- the available network bandwidth between source and target
- the ability to quickly process files and folders in a namespace
- the number of changes between RoboCopy runs
- the size and number of files you need to copy
IOPS and bandwidth considerations
In this category, you need to consider abilities of the source storage, the target storage, and the network connecting them. The maximum possible throughput is determined by the slowest of these three components. Make sure your network infrastructure is configured to support optimal transfer speeds to its best abilities.
Caution
While copying as fast as possible is often most desireable, consider the utilization of your local network and NAS appliance for other, often business-critical tasks.
Copying as fast as possible might not be desirable when there's a risk that the migration could monopolize available resources.
- Consider when it's best in your environment to run migrations: during the day, off-hours, or during weekends.
- Also consider networking QoS on a Windows Server to throttle the RoboCopy speed.
- Avoid unnecessary work for the migration tools.
RoboCopy can insert inter-packet delays by specifying the /IPG:n switch where n is measured in milliseconds between RoboCopy packets. Using this switch can help avoid monopolization of resources on both IO constrained devices, and crowded network links.
/IPG:n can't be used for precise network throttling to a certain Mbps. Use Windows Server Network QoS instead. RoboCopy entirely relies on the SMB protocol for all networking needs. Using SMB is the reason why RoboCopy can't influence the network throughput itself, but it can slow down its use.
A similar line of thought applies to the IOPS observed on the NAS. The cluster size on the NAS volume, packet sizes, and an array of other factors influence the observed IOPS. Introducing inter-packet delay is often the easiest way to control the load on the NAS. Test multiple values, for instance from about 20 milliseconds (n=20) to multiples of that number. Once you introduce a delay, you can evaluate if your other apps can now work as expected. This optimization strategy will allow you to find the optimal RoboCopy speed in your environment.
Processing speed
RoboCopy will traverse the namespace it's pointed to and evaluate each file and folder for copy. Every file will be evaluated during an initial copy and during catch-up copies. For example, repeated runs of RoboCopy /MIR against the same source and target storage locations. These repeated runs are useful to minimize downtime for users and apps, and to improve the overall success rate of files migrated.
We often default to considering bandwidth as the most limiting factor in a migration - and that can be true. But the ability to enumerate a namespace can influence the total time to copy even more for larger namespaces with smaller files. Consider that copying 1 TiB of small files will take considerably longer than copying 1 TiB of fewer but larger files, assuming that all other variables remain the same. Therefore, you may experience slow transfer if you're migrating a large number of small files. This is an expected behavior.
The cause for this difference is the processing power needed to walk through a namespace. RoboCopy supports multi-threaded copies through the /MT:n parameter where n stands for the number of threads to be used. So when provisioning a machine specifically for RoboCopy, consider the number of processor cores and their relationship to the thread count they provide. Most common are two threads per core. The core and thread count of a machine is an important data point to decide what multi-thread values /MT:n you should specify. Also consider how many RoboCopy jobs you plan to run in parallel on a given machine.
More threads will copy our 1-TiB example of small files considerably faster than fewer threads. At the same time, the extra resource investment on our 1 TiB of larger files may not yield proportional benefits. A high thread count will attempt to copy more of the large files over the network simultaneously. This extra network activity increases the probability of getting constrained by throughput or storage IOPS.
During a first RoboCopy into an empty target or a differential run with lots of changed files, you are likely constrained by your network throughput. Start with a high thread count for an initial run. A high thread count, even beyond your currently available threads on the machine, helps saturate the available network bandwidth. Subsequent /MIR runs are progressively impacted by processing items. Fewer changes in a differential run mean less transport of data over the network. Your speed is now more dependent on your ability to process namespace items than to move them over the network link. For subsequent runs, match your thread count value to your processor core count and thread count per core. Consider if cores need to be reserved for other tasks a production server may have.
Tip
Rule of thumb: The first RoboCopy run, that will move a lot of data of a higher-latency network, benefits from over-provisioning the thread count (/MT:n). Subsequent runs will copy fewer differences and you are more likely to shift from network throughput constrained to compute constrained. Under these circumstances, it is often better to match the RoboCopy thread count to the actually available threads on the machine. Over-provisioning in that scenario can lead to more context shifts in the processor, possibly slowing down your copy.
Avoid unnecessary work
Avoid large-scale changes in your namespace. For example, moving files between directories, changing properties at a large scale, or changing permissions (NTFS ACLs). Especially ACL changes can have a high impact because they often have a cascading change effect on files lower in the folder hierarchy. Consequences can be:
- extended RoboCopy job run time because each file and folder affected by an ACL change needing to be updated
- reusing data moved earlier may need to be recopied. For instance, more data will need to be copied when folder structures change after files had already been copied earlier. A RoboCopy job can't "play back" a namespace change. The next job must purge the files previously transported to the old folder structure and upload the files in the new folder structure again.
Another important aspect is to use the RoboCopy tool effectively. With the recommended RoboCopy script, you'll create and save a log file for errors. Copy errors can occur - that is normal. These errors often make it necessary to run multiple rounds of a copy tool like RoboCopy. An initial run, say from a NAS to DataBox or a server to an Azure file share. And one or more extra runs with the /MIR switch to catch and retry files that didn't get copied.
You should be prepared to run multiple rounds of RoboCopy against a given namespace scope. Successive runs will finish faster as they have less to copy but are constrained increasingly by the speed of processing the namespace. When you run multiple rounds, you can speed up each round by not having RoboCopy try unreasonably hard to copy everything in a given run. These RoboCopy switches can make a significant difference:
/R:nn = how often you retry to copy a failed file and/W:nn = how many seconds to wait between retries
/R:5 /W:5 is a reasonable setting that you can adjust to your liking. In this example, a failed file will be retried five times, with five-second wait time between retries. If the file still fails to copy, the next RoboCopy job will try again. Often files that failed because they are in use or because of timeout issues might eventually be copied successfully this way.
Windows Server 2022 and RoboCopy LFSM
The RoboCopy switch /LFSM can be used to avoid a RoboCopy job failing with a volume full error. RoboCopy will pause whenever a file copy would cause the destination volume's free space to go below a "floor" value.
Use RoboCopy with Windows Server 2022. Only this version of RoboCopy contains important bug fixes and features that make the switch compatible with additional flags needed in most migrations. For example, compatibility with the /B flag.
/B runs RoboCopy in the same mode that a backup application would use. This switch allows RoboCopy to move files that the current user doesn't have permissions for.
Normally, RoboCopy can be run on the Source, Destination or a third machine.
Important
If you intend to use /LFSM, RoboCopy must be run on the Windows Server 2022 target Azure File Sync server.
Note also that with /LFSM you must also use a local path for the destination, not a UNC path. For example as a destination path you should use E:\Foldername rather than a UNC path like \\ServerName\FolderName.
Caution
The currently available version of RoboCopy on Windows Server 2022 has a bug that causes the pauses to count against the per file error count. Apply the following workaround.
The recommended /R:2 /W:1 flags increase the probability that a file is failed due to an /LFSM induced pause. In this example, a file that wasn't copied after 3 pauses because /LFSM caused the pause, will incorrectly make RoboCopy fail the file. The workaround for this is to use higher values for /R:n and /W:n. A good example is /R:10 /W:1800 (10 retries of 30 minutes each). This should give the Azure File Sync tiering algorithm time to create space on the destination volume.
This bug has been fixed but the fix is not yet publicly available. Check this paragraph for updates on the availability of the fix and how to deploy it.
Note
Still have questions or encountered any issues?
We're here to help:

Relevant links
Migration content:
Azure File Sync content:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for