Tutorial: Capture Event Hubs data in parquet format and analyze with Azure Synapse Analytics
This tutorial shows you how to use the Stream Analytics no code editor to create a job that captures Event Hubs data in to Azure Data Lake Storage Gen2 in the parquet format.
In this tutorial, you learn how to:
- Deploy an event generator that sends sample events to an event hub
- Create a Stream Analytics job using the no code editor
- Review input data and schema
- Configure Azure Data Lake Storage Gen2 to which event hub data will be captured
- Run the Stream Analytics job
- Use Azure Synapse Analytics to query the parquet files
Prerequisites
Before you start, make sure you've completed the following steps:
- If you don't have an Azure subscription, create a free account.
- Deploy the TollApp event generator app to Azure. Set the 'interval' parameter to 1, and use a new resource group for this step.
- Create an Azure Synapse Analytics workspace with a Data Lake Storage Gen2 account.
Use no code editor to create a Stream Analytics job
Locate the Resource Group in which the TollApp event generator was deployed.
Select the Azure Event Hubs namespace.
On the Event Hubs Namespace page, select Event Hubs under Entities on the left menu.
Select
entrystreaminstance.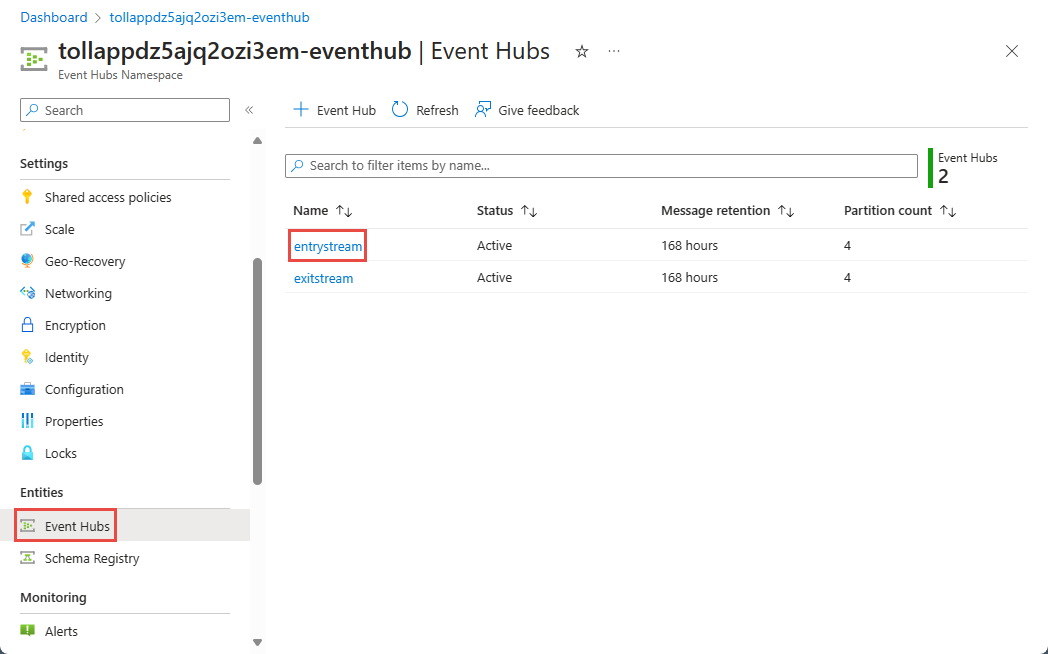
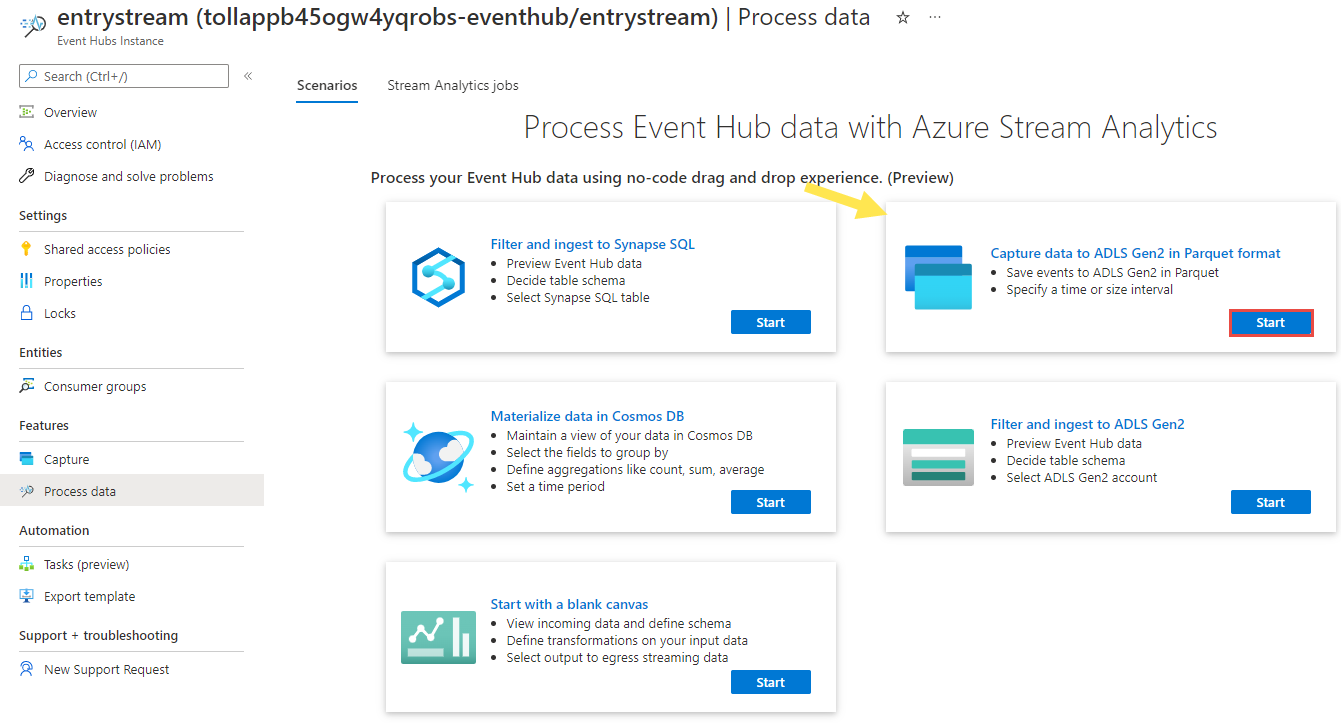
On the Event Hubs instance page, select Process data in the Features section on the left menu.
Select Start on the Capture data to ADLS Gen2 in Parquet format tile.
Name your job
parquetcaptureand select Create.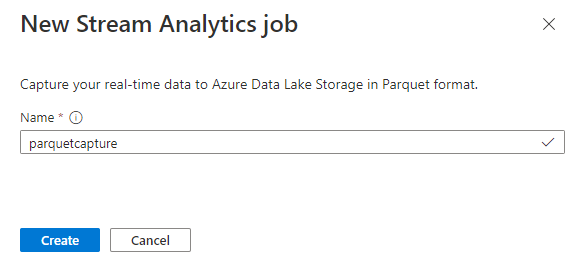
On the event hub configuration page, confirm the following settings, and then select Connect.
Consumer Group: Default
Serialization type of your input data: JSON
Authentication mode that the job will use to connect to your event hub: Connection string.
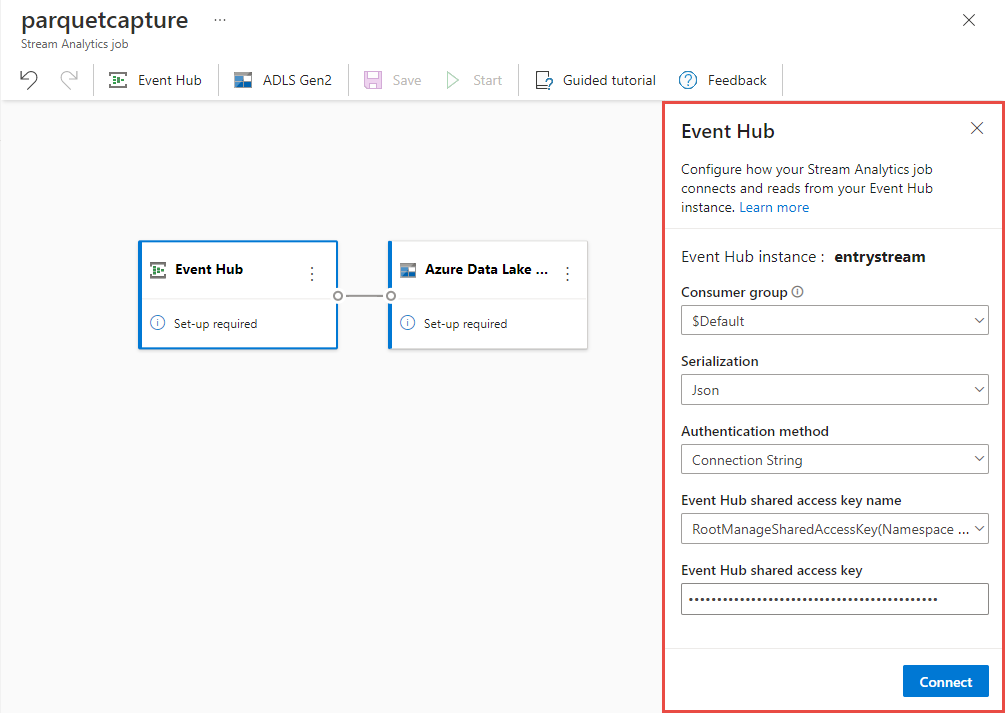
Within few seconds, you'll see sample input data and the schema. You can choose to drop fields, rename fields or change data type.
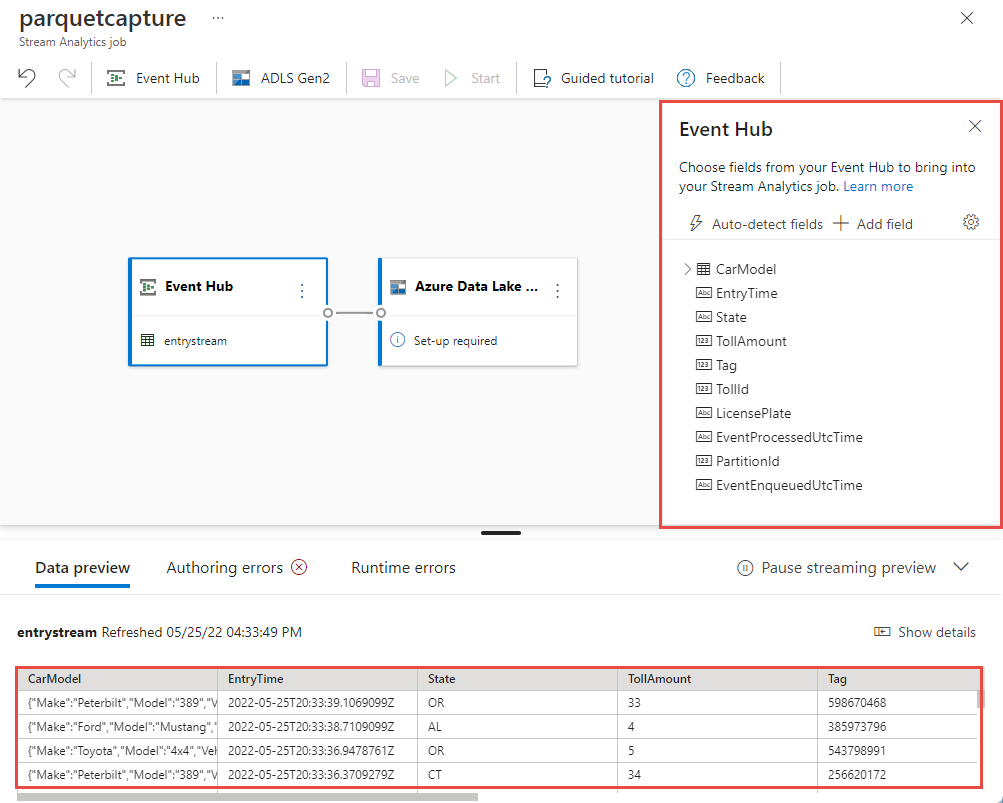
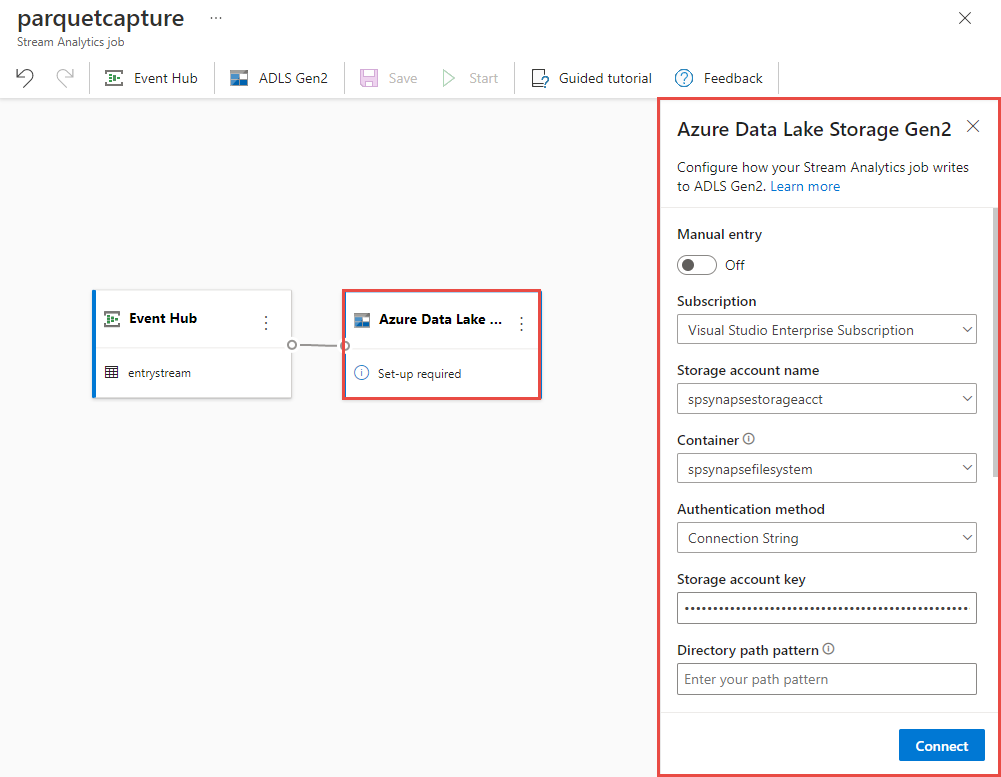
Select the Azure Data Lake Storage Gen2 tile on your canvas and configure it by specifying
- Subscription where your Azure Data Lake Gen2 account is located in
- Storage account name, which should be the same ADLS Gen2 account used with your Azure Synapse Analytics workspace done in the Prerequisites section.
- Container inside which the Parquet files will be created.
- Path pattern set to {date}/{time}
- Date and time pattern as the default yyyy-mm-dd and HH.
- Select Connect
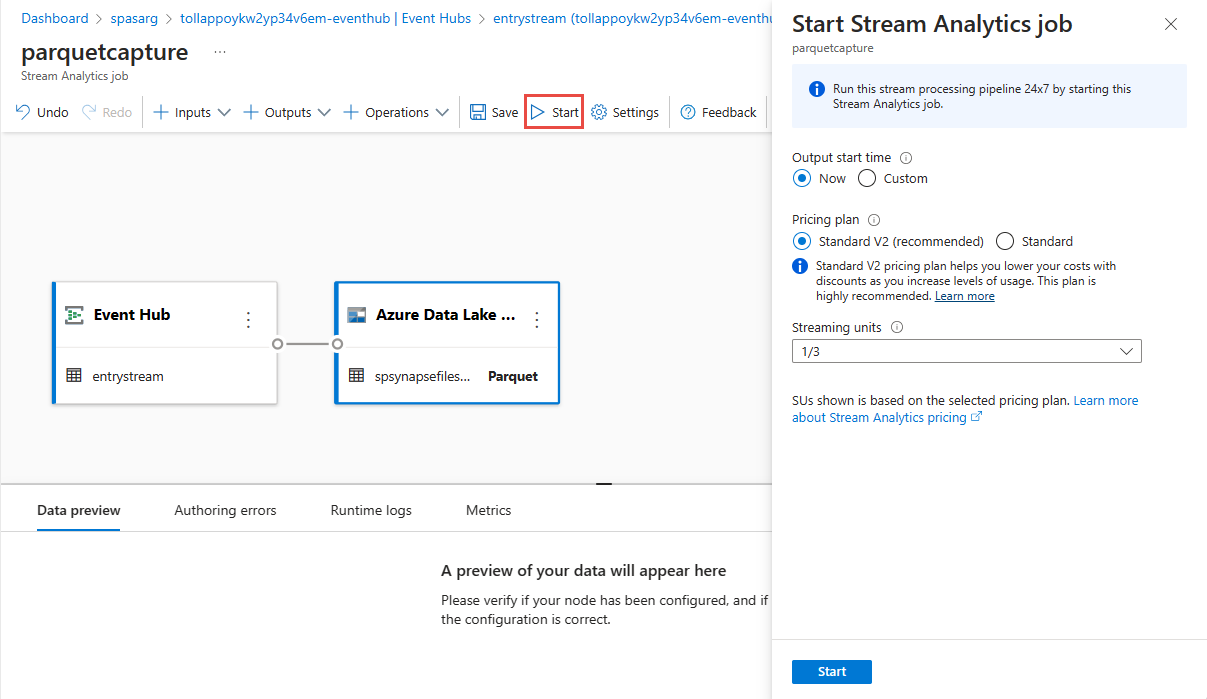
Select Save in the top ribbon to save your job, and then select Start to run your job. Once the job is started, select X in the right corner to close the Stream Analytics job page.
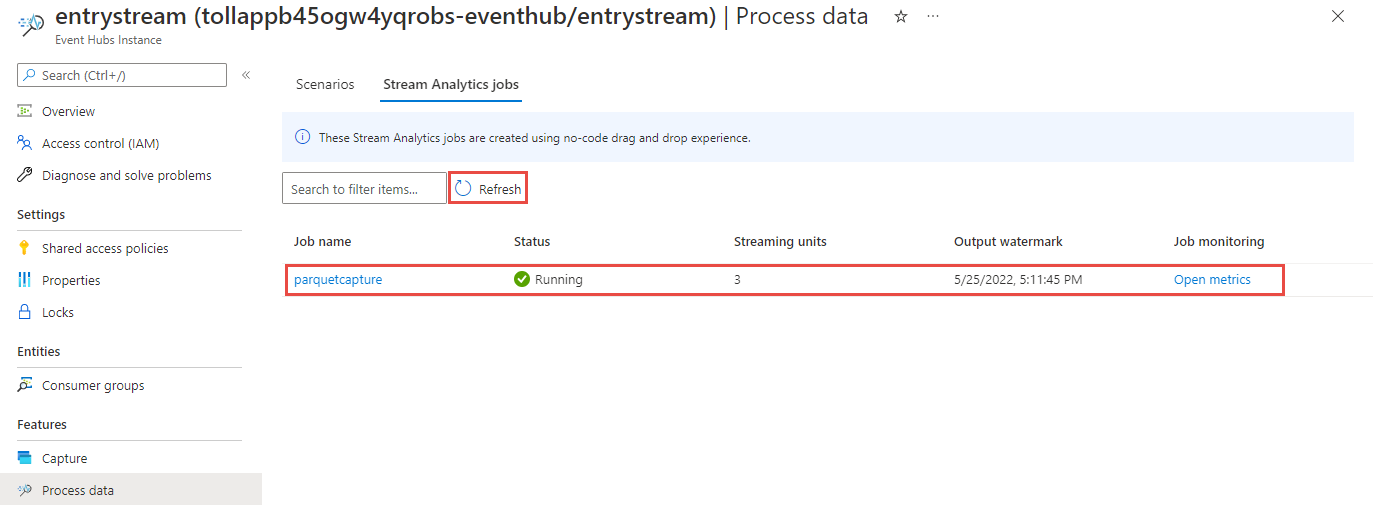
You'll then see a list of all Stream Analytics jobs created using the no code editor. And within two minutes, your job will go to a Running state. Select the Refresh button on the page to see the status changing from Created -> Starting -> Running.








View output in your Azure Data Lake Storage Gen 2 account
Locate the Azure Data Lake Storage Gen2 account you had used in the previous step.
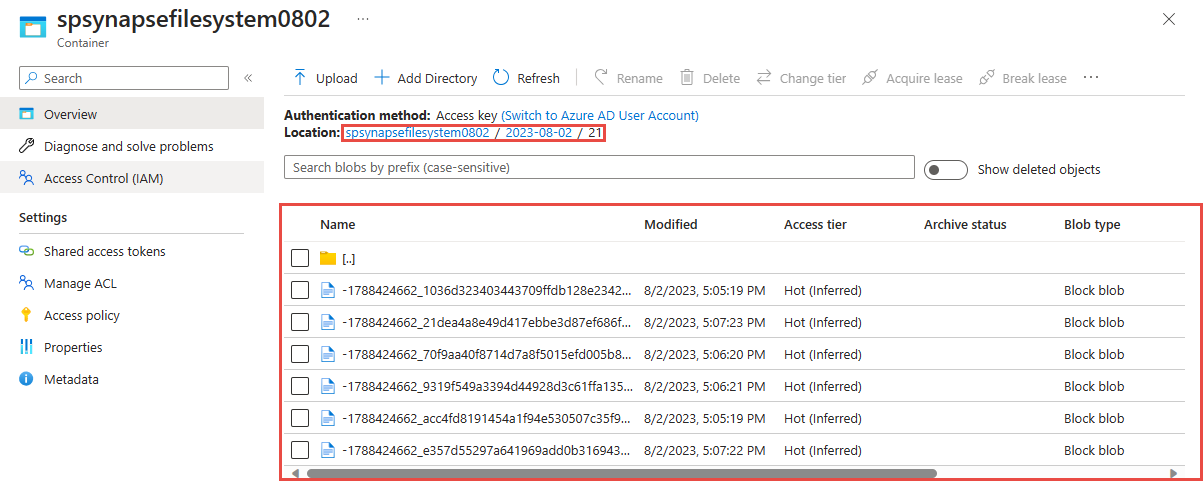
Select the container you had used in the previous step. You'll see parquet files created based on the {date}/{time} path pattern used in the previous step.
Query captured data in Parquet format with Azure Synapse Analytics
Query using Azure Synapse Spark
Locate your Azure Synapse Analytics workspace and open Synapse Studio.
Create a serverless Apache Spark pool in your workspace if one doesn't already exist.
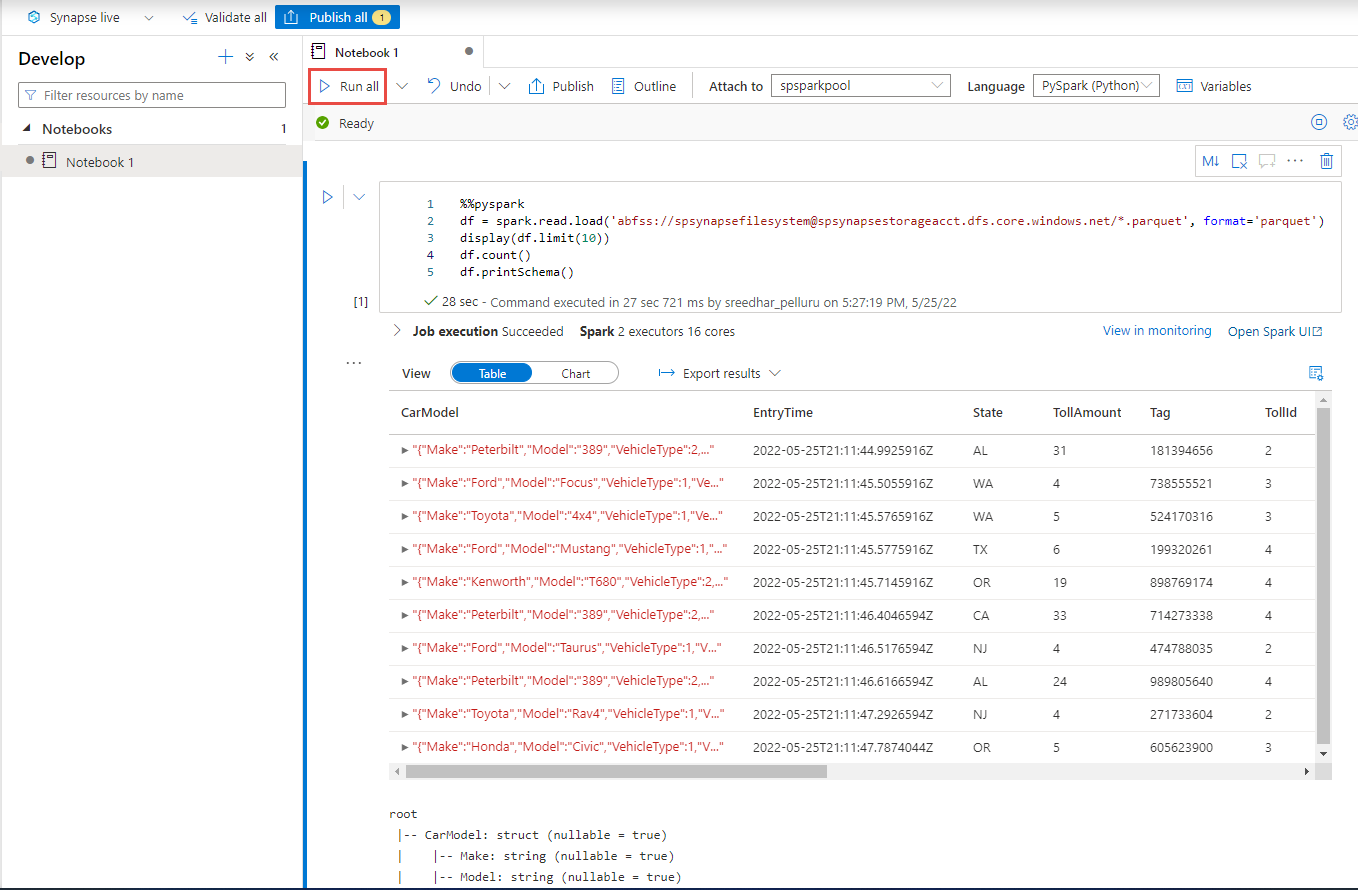
In the Synapse Studio, go to the Develop hub and create a new Notebook.
Create a new code cell and paste the following code in that cell. Replace container and adlsname with the name of the container and ADLS Gen2 account used in the previous step.
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()For Attach to on the toolbar, select your Spark pool from the dropdown list.
Select Run All to see the results

Query using Azure Synapse Serverless SQL
In the Develop hub, create a new SQL script.
Paste the following script and Run it using the Built-in serverless SQL endpoint. Replace container and adlsname with the name of the container and ADLS Gen2 account used in the previous step.
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*/*.parquet', FORMAT='PARQUET' ) AS [result]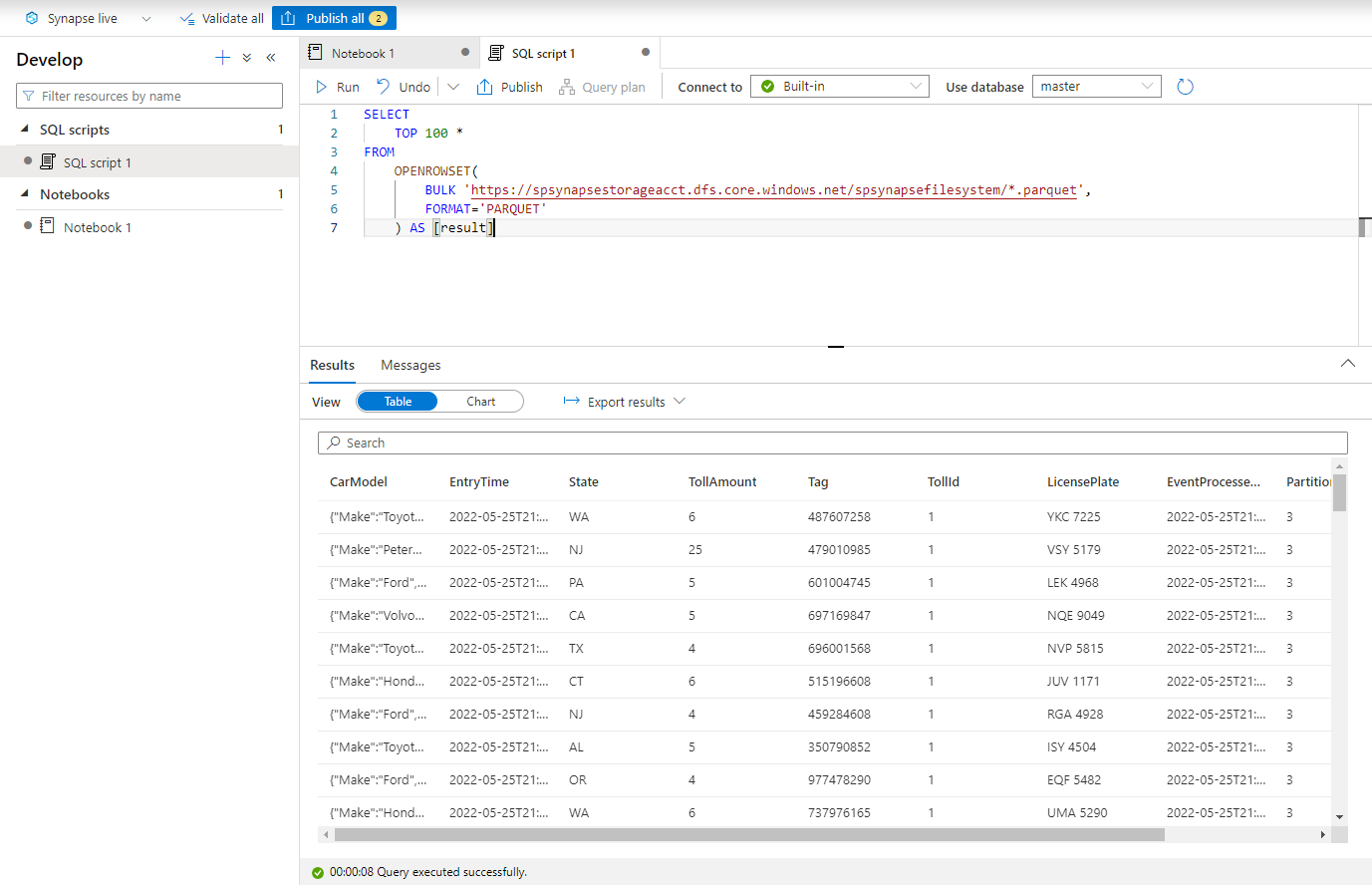

Clean up resources
- Locate your Event Hubs instance and see the list of Stream Analytics jobs under Process Data section. Stop any jobs that are running.
- Go to the resource group you used while deploying the TollApp event generator.
- Select Delete resource group. Type the name of the resource group to confirm deletion.
Next steps
In this tutorial, you learned how to create a Stream Analytics job using the no code editor to capture Event Hubs data streams in Parquet format. You then used Azure Synapse Analytics to query the parquet files using both Synapse Spark and Synapse SQL.