Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Available in both the cloud and Azure IoT Edge, Azure Stream Analytics offers built-in machine learning based anomaly detection capabilities that you can use to monitor the two most commonly occurring anomalies: temporary and persistent. By using the AnomalyDetection_SpikeAndDip and AnomalyDetection_ChangePoint functions, you can perform anomaly detection directly in your Stream Analytics job.
The machine learning models assume a uniformly sampled time series. If the time series isn't uniform, insert an aggregation step with a tumbling window before calling anomaly detection.
The machine learning operations don't support seasonality trends or multivariate correlations at this time.
Anomaly detection using machine learning in Azure Stream Analytics
The following video demonstrates how to detect an anomaly in real time by using machine learning functions in Azure Stream Analytics.
Model behavior
Generally, the model's accuracy improves with more data in the sliding window. The data in the specified sliding window is treated as part of its normal range of values for that time frame. The model only considers event history over the sliding window to check if the current event is anomalous. As the sliding window moves, old values are evicted from the model's training.
The functions operate by establishing a certain normal based on what they've seen so far. Outliers are identified by comparing against the established normal, within the confidence level. The window size should be based on the minimum events required to train the model for normal behavior so that when an anomaly occurs, it would be able to recognize it.
The model's response time increases with history size because it needs to compare against a higher number of past events. For better performance, include only the necessary number of events.
Gaps in the time series can occur when the model doesn't receive events at certain points in time. Stream Analytics handles this situation by using imputation logic. The history size, and a time duration for the same sliding window, is used to calculate the average rate at which events are expected to arrive.
You can use an anomaly generator to feed an IoT Hub with data that contains different anomaly patterns. You can set up an Azure Stream Analytics job by using these anomaly detection functions to read from this IoT Hub and detect anomalies.
Spike and dip
Temporary anomalies in a time series event stream are known as spikes and dips. You can monitor spikes and dips by using the Machine Learning based operator, AnomalyDetection_SpikeAndDip.
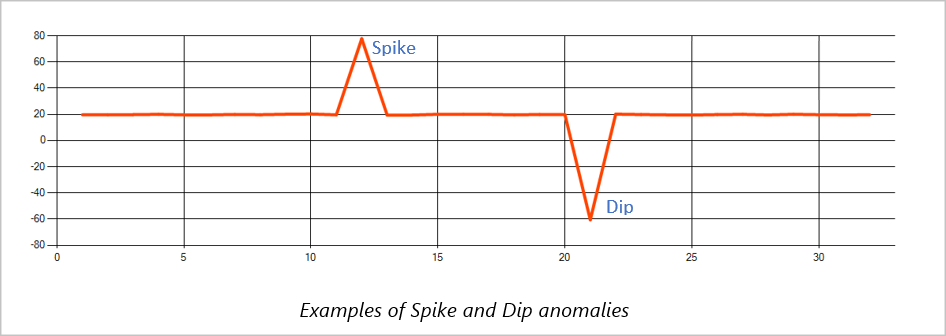
In the same sliding window, if a second spike is smaller than the first one, the computed score for the smaller spike might not be significant enough compared to the score for the first spike within the confidence level specified. You can try decreasing the model's confidence level to detect such anomalies. However, if you start to get too many alerts, use a higher confidence interval.
The following example query assumes a uniform input rate of one event per second in a 2-minute sliding window with a history of 120 events. The final SELECT statement extracts and outputs the score and anomaly status with a confidence level of 95%.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO output
FROM AnomalyDetectionStep
Change point
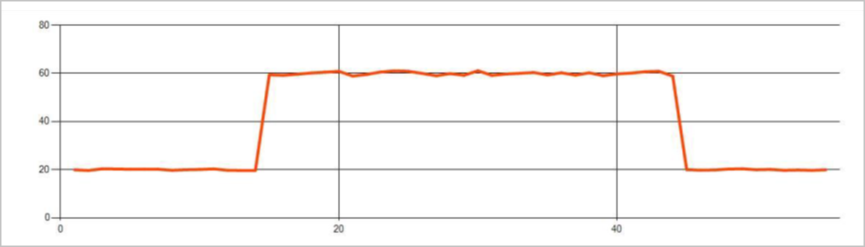
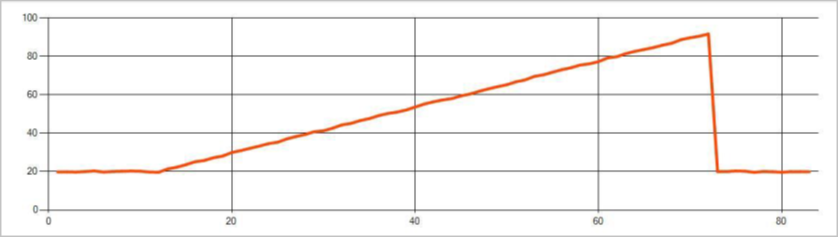
Persistent anomalies in a time series event stream are changes in the distribution of values in the event stream, like level changes and trends. In Stream Analytics, the Machine Learning based AnomalyDetection_ChangePoint operator detects these anomalies.
Persistent changes last much longer than spikes and dips and could indicate catastrophic events. Persistent changes aren't usually visible to the naked eye, but the AnomalyDetection_ChangePoint operator can detect them.
The following image is an example of a level change:
The following image is an example of a trend change:
The following example query assumes a uniform input rate of one event per second in a 20-minute sliding window with a history size of 1,200 events. The final SELECT statement extracts and outputs the score and anomaly status with a confidence level of 80%.
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_ChangePoint(CAST(temperature AS float), 80, 1200)
OVER(LIMIT DURATION(minute, 20)) AS ChangePointScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(ChangePointScores, 'Score') AS float) AS
ChangePointScore,
CAST(GetRecordPropertyValue(ChangePointScores, 'IsAnomaly') AS bigint) AS
IsChangePointAnomaly
INTO output
FROM AnomalyDetectionStep
Performance characteristics
The performance of these models depends on the history size, window duration, event load, and whether function level partitioning is used. This section discusses these configurations and provides samples for how to sustain ingestion rates of 1 K, 5 K, and 10 K events per second.
- History size - These models perform linearly with history size. The longer the history size, the longer the models take to score a new event. The models compare the new event with each of the past events in the history buffer.
- Window duration - The Window duration should reflect how long it takes to receive as many events as specified by the history size. Without that many events in the window, Azure Stream Analytics would impute missing values. Hence, CPU consumption is a function of the history size.
- Event load - The greater the event load, the more work the models perform, which impacts CPU consumption. You can scale out the job by making it embarrassingly parallel, assuming it makes sense for business logic to use more input partitions.
- Function level partitioning - Use
PARTITION BYwithin the anomaly detection function call to perform Function level partitioning. This type of partitioning adds an overhead, as the job needs to maintain state for multiple models at the same time. Use function level partitioning in scenarios like device level partitioning.
Relationship
The history size, window duration, and total event load are related in the following way:
windowDuration (in ms) = 1000 * historySize / (total input events per second / Input Partition Count)
When partitioning the function by deviceId, add "PARTITION BY deviceId" to the anomaly detection function call.
Observations
The following table shows the throughput observations for a single node (six SU) for the nonpartitioned case:
| History size (events) | Window duration (ms) | Total input events per second |
|---|---|---|
| 60 | 55 | 2,200 |
| 600 | 728 | 1,650 |
| 6,000 | 10,910 | 1,100 |
The following table shows the throughput observations for a single node (six SU) for the partitioned case:
| History size (events) | Window duration (ms) | Total input events per second | Device count |
|---|---|---|---|
| 60 | 1,091 | 1,100 | 10 |
| 600 | 10,910 | 1,100 | 10 |
| 6,000 | 218,182 | <550 | 10 |
| 60 | 21,819 | 550 | 100 |
| 600 | 218,182 | 550 | 100 |
| 6,000 | 2,181,819 | <550 | 100 |
You can find sample code to run the nonpartitioned configurations in the Streaming At Scale repo of Azure Samples. The code creates a Stream Analytics job with no function level partitioning, which uses Event Hubs as input and output. The test clients generate the input load. Each input event is a 1 KB JSON document. The events simulate an IoT device sending JSON data (for up to 1 K devices). The history size, window duration, and total event load vary over two input partitions.
Note
For a more accurate estimate, customize the samples to fit your scenario.
Identifying bottlenecks
To identify bottlenecks in your pipeline, use the Metrics pane in your Azure Stream Analytics job. Review Input/Output Events for throughput and "Watermark Delay" or Backlogged Events to see if the job keeps up with the input rate. For Event Hubs metrics, look for Throttled Requests and adjust the Threshold Units accordingly. For Azure Cosmos DB metrics, review Max consumed RU/s per partition key range under Throughput to ensure your partition key ranges are uniformly consumed. For Azure SQL DB, monitor Log IO and CPU.