What is Azure Synapse Data Explorer? (Preview)
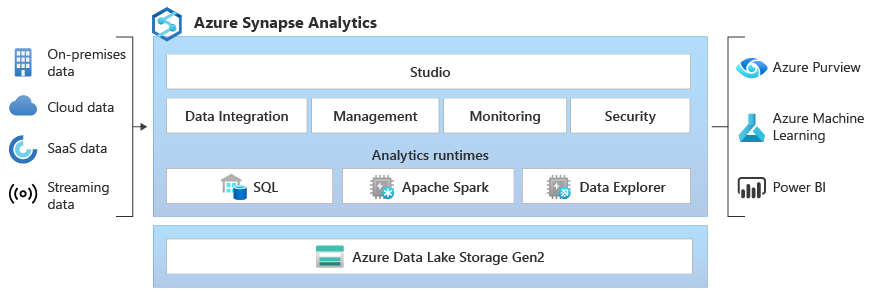
Azure Synapse Data Explorer provides customers with an interactive query experience to unlock insights from log and telemetry data. To complement existing SQL and Apache Spark analytics runtime engines, the Data Explorer analytics runtime is optimized for efficient log analytics using powerful indexing technology to automatically index free-text and semi-structured data commonly found in telemetry data.
To learn more, see the following video:
What makes Azure Synapse Data Explorer unique?
Easy ingestion - Data Explorer offers built-in integrations for no-code/low-code, high-throughput data ingestion, and caching data from real-time sources. Data can be ingested from sources such as Azure Event Hubs, Kafka, Azure Data Lake, open source agents such as Fluentd/Fluent Bit, and a wide variety of cloud and on-premises data sources.
No complex data modeling - With Data Explorer, there's no need to build complex data models and no need for complex scripting to transform data before it's consumed.
No index maintenance - There's no need for maintenance tasks to optimize data for query performance and no need for index maintenance. With Data Explorer, all raw data is available immediately, allowing you to run high-performance and high-concurrency queries on your streaming and persistent data. You can use these queries to build near real-time dashboards and alerts and connect operational analytics data with the rest of the data analytics platform.
Democratizing data analytics - Data Explorer democratizes self-service, big data analytics with the intuitive Kusto Query Language (KQL) that provides the expressiveness and power of SQL with the simplicity of Excel. KQL is highly optimized for exploring raw telemetry and time series data by leveraging Data Explorer's best-in-class text indexing technology for efficient free-text and regex search, and comprehensive parsing capabilities for querying traces\text data and JSON semi-structured data including arrays and nested structures. KQL offers advanced time series support for creating, manipulating, and analyzing multiple time series with in-engine Python execution support for model scoring.
Proven technology at petabyte scale - Data Explorer is a distributed system with compute resources and storage that can scale independently, enabling analytics on gigabytes or petabytes of data.
Integrated - Azure Synapse Analytics provides interoperability across data between Data Explorer, Apache Spark, and SQL engines empowering data engineers, data scientists, and data analysts to easily, and securely, access and collaborate on the same data in the data lake.
When to use Azure Synapse Data Explorer?
Use Data Explorer as a data platform for building near real-time log analytics and IoT analytics solutions to:
Consolidate and correlate your logs and events data across on-premises, cloud, and third-party data sources.
Accelerate your AI Ops journey (pattern recognition, anomaly detection, forecasting, and more).
Replace infrastructure-based log search solutions to save cost and increase productivity.
Build IoT analytics solutions for your IoT data.
Build analytics SaaS solutions to offer services to your internal and external customers.
Data Explorer pool architecture
Data Explorer pools implement a scale-out architecture by separating the compute and storage resources. This enables you to independently scale each resource and, for example, run multiple read-only computes on the same data. Data Explorer pools consist of a set of compute resources running the engine that is responsible for automatic indexing, compressing, caching, and serving distributed queries. They also have a second set of compute resources running the data management service responsible for background system jobs, and managed and queued data ingestion. All data is persisted on managed blob storage accounts using a compressed columnar format.
Data Explorer pools support a rich ecosystem for ingesting data using connectors, SDKs, REST APIs, and other managed capabilities. It offers various ways to consume data for ad hoc queries, reports, dashboards, alerts, REST APIs, and SDKs.
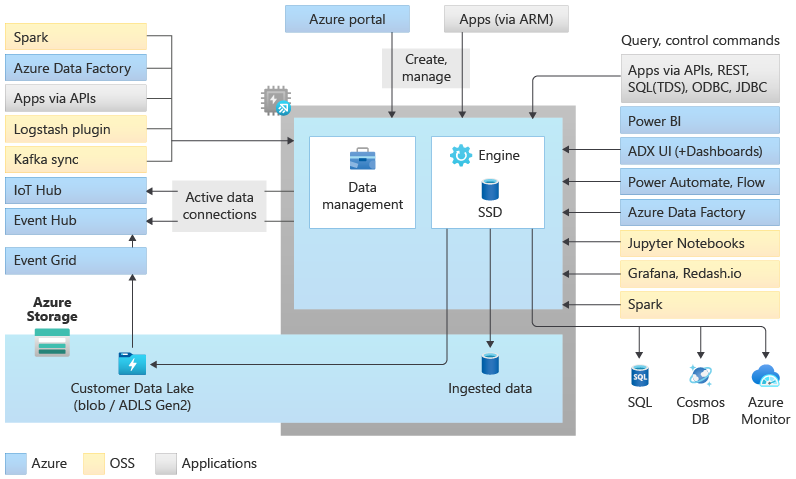
There are many unique capabilities that make Data Explore the best analytical engine for log and time series analytics on Azure.
The following sections highlight the key differentiators.
Free-text and semi-structured data indexing enables near real-time high-performance and high concurrent queries
Data Explorer indexes semi-structured data (JSON) and unstructured data (free text) which makes running queries perform well on this type of data. By default, every field is indexed during the data ingestion with the option to use a low-level encoding policy to fine-tune or disable the index for specific fields. The scope of the index is a single data shard.
The implementation of the index depends on the type of the field, as follows:
| Field type | Indexing implementation |
|---|---|
| String | The engine builds an inverted term index for string column values. Each string value is analyzed and split into normalized terms and an ordered list of logical positions, containing record ordinals, is recorded for each term. The resulting sorted list of terms and their associated positions is stored as an immutable B-tree. |
| Numeric DateTime TimeSpan |
The engine builds a simple range-based forward index. The index records the min/max values for each block, for a group of blocks and for the entire column within the data shard. |
| Dynamic | The ingestion process enumerates all "atomic" elements within the dynamic value, such as property names, values, and array elements, and forwards them to the index builder. Dynamic fields have the same inverted term index as string fields. |
These efficient indexing capabilities enable Data Explore to make the data available in near-real-time for high-performance and high-concurrency queries. The system automatically optimizes data shards to further boost performance.
Kusto Query Language
KQL has a large, growing community with the rapid adoption of Azure Monitor Log Analytics and Application Insights, Microsoft Sentinel, Azure Data Explorer, and other Microsoft offerings. The language is well designed with an easy-to-read syntax and provides a smooth transition from simple one-liner to complex data processing queries. This allows Data Explorer to provide rich Intellisense support and a rich set of language constructs and built-in capabilities for aggregations, time series, and user analytics that aren't available in SQL for rapid exploration of telemetry data.