Synapse POC playbook: Big data analytics with Apache Spark pool in Azure Synapse Analytics
This article presents a high-level methodology for preparing and running an effective Azure Synapse Analytics proof of concept (POC) project for Apache Spark pool.
Note
This article forms part of the Azure Synapse proof of concept playbook series of articles. For an overview of the series, see Azure Synapse proof of concept playbook.
Prepare for the POC
A POC project can help you make an informed business decision about implementing a big data and advanced analytics environment on a cloud-based platform that leverages Apache Spark pool in Azure Synapse.
A POC project will identify your key goals and business drivers that cloud-based big data and advance analytics platform must support. It will test key metrics and prove key behaviors that are critical to the success of your data engineering, machine learning model building, and training requirements. A POC isn't designed to be deployed to a production environment. Rather, it's a short-term project that focuses on key questions, and its result can be discarded.
Before you begin planning your Spark POC project:
- Identify any restrictions or guidelines your organization has about moving data to the cloud.
- Identify executive or business sponsors for a big data and advanced analytics platform project. Secure their support for migration to the cloud.
- Identify availability of technical experts and business users to support you during the POC execution.
Before you start preparing for the POC project, we recommend you first read the Apache Spark documentation.
Tip
If you're new to Spark pools, we recommend you work through the Perform data engineering with Azure Synapse Apache Spark Pools learning path.
By now you should have determined that there are no immediate blockers and then you can start preparing for your POC. If you are new to Apache Spark Pools in Azure Synapse Analytics you can refer to this documentation where you can get an overview of the Spark architecture and learn how it works in Azure Synapse.
Develop an understanding of these key concepts:
- Apache Spark and its distributed architecture.
- Spark concepts like Resilient Distributed Datasets (RDD) and partitions (in-memory and physical).
- Azure Synapse workspace, the different compute engines, pipeline, and monitoring.
- Separation of compute and storage in Spark pool.
- Authentication and authorization in Azure Synapse.
- Native connectors that integrate with Azure Synapse dedicated SQL pool, Azure Cosmos DB, and others.
Azure Synapse decouples compute resources from storage so that you can better manage your data processing needs and control costs. The serverless architecture of Spark pool allows you to spin up and down as well as grow and shrink your Spark cluster, independent of your storage. You can pause (or setup auto-pause) a Spark cluster entirely. That way, you pay for compute only when it's in use. When it's not in use, you only pay for storage. You can scale up your Spark cluster for heavy data processing needs or large loads and then scale it back down during less intense processing times (or shut it down completely). You can effectively scale and pause a cluster to reduce costs. Your Spark POC tests should include data ingestion and data processing at different scales (small, medium, and large) to compare price and performance at different scale. For more information, see Automatically scale Azure Synapse Analytics Apache Spark pools.
It's important to understand the difference between the different sets of Spark APIs so you can decide what works best for your scenario. You can choose the one that provides better performance or ease of use, taking advantage of your team's existing skill sets. For more information, see A Tale of Three Apache Spark APIs: RDDs, DataFrames, and Datasets.
Data and file partitioning work slightly differently in Spark. Understanding the differences will help you to optimize for performance. For more information, see Apache Spark documentation: Partition Discovery and Partition Configuration Options.
Set the goals
A successful POC project requires planning. Start by identify why you're doing a POC to fully understand the real motivations. Motivations could include modernization, cost saving, performance improvement, or integrated experience. Be sure to document clear goals for your POC and the criteria that will define its success. Ask yourself:
- What do you want as the outputs of your POC?
- What will you do with those outputs?
- Who will use the outputs?
- What will define a successful POC?
Keep in mind that a POC should be a short and focused effort to quickly prove a limited set of concepts and capabilities. These concepts and capabilities should be representative of the overall workload. If you have a long list of items to prove, you may want to plan more than one POC. In that case, define gates between the POCs to determine whether you need to continue with the next one. Given the different professional roles that may use Spark pools and notebooks in Azure Synapse, you may choose to execute multiple POCs. For example, one POC could focus on requirements for the data engineering role, such as ingestion and processing. Another POC could focus on machine learning (ML) model development.
As you consider your POC goals, ask yourself the following questions to help you shape the goals:
- Are you migrating from an existing big data and advanced analytics platform (on-premises or cloud)?
- Are you migrating but want to make as few changes as possible to existing ingestion and data processing? For example, a Spark to Spark migration, or a Hadoop/Hive to Spark migration.
- Are you migrating but want to do some extensive improvements along the way? For example, re-writing MapReduce jobs as Spark jobs, or converting legacy RDD-based code to DataFrame/Dataset-based code.
- Are you building an entirely new big data and advanced analytics platform (greenfield project)?
- What are your current pain points? For example, scalability, performance, or flexibility.
- What new business requirements do you need to support?
- What are the SLAs that you're required to meet?
- What will be the workloads? For example, ETL, batch processing, stream processing, machine learning model training, analytics, reporting queries, or interactive queries?
- What are the skills of the users who will own the project (should the POC be implemented)? For example, PySpark vs Scala skills, notebook vs IDE experience.
Here are some examples of POC goal setting:
- Why are we doing a POC?
- We need to know that the data ingestion and processing performance for our big data workload will meet our new SLAs.
- We need to know whether near real-time stream processing is possible and how much throughput it can support. (Will it support our business requirements?)
- We need to know if our existing data ingestion and transformation processes are a good fit and where improvements will need to be made.
- We need to know if we can shorten our data integration run times and by how much.
- We need to know if our data scientists can build and train machine learning models and leverage AI/ML libraries as needed in a Spark pool.
- Will the move to cloud-based Synapse Analytics meet our cost goals?
- At the conclusion of this POC:
- We will have the data to determine if our data processing performance requirements can be met for both batch and real-time streaming.
- We will have tested ingestion and processing of all our different data types (structured, semi and unstructured) that support our use cases.
- We will have tested some of our existing complex data processing and can identify the work that will need to be completed to migrate our portfolio of data integration to the new environment.
- We will have tested data ingestion and processing and will have the data points to estimate the effort required for the initial migration and load of historical data, as well as estimate the effort required to migrate our data ingestion (Azure Data Factory (ADF), Distcp, Databox, or others).
- We will have tested data ingestion and processing and can determine if our ETL/ELT processing requirements can be met.
- We will have gained insight to better estimate the effort required to complete the implementation project.
- We will have tested scale and scaling options and will have the data points to better configure our platform for better price-performance settings.
- We will have a list of items that may need more testing.
Plan the project
Use your goals to identify specific tests and to provide the outputs you identified. It's important to make sure that you have at least one test to support each goal and expected output. Also, identify specific data ingestion, batch or stream processing, and all other processes that will be executed so you can identify a very specific dataset and codebase. This specific dataset and codebase will define the scope of the POC.
Here's an example of the needed level of specificity in planning:
- Goal A: We need to know whether our requirement for data ingestion and processing of batch data can be met under our defined SLA.
- Output A: We will have the data to determine whether our batch data ingestion and processing can meet the data processing requirement and SLA.
- Test A1: Processing queries A, B, and C are identified as good performance tests as they are commonly executed by the data engineering team. Also, they represent overall data processing needs.
- Test A2: Processing queries X, Y, and Z are identified as good performance tests as they contain near real-time stream processing requirements. Also, they represent overall event-based stream processing needs.
- Test A3: Compare the performance of these queries at different scale of the Spark cluster (varying number of worker nodes, size of the worker nodes - like small, medium, and large - number and size of executors) with the benchmark obtained from the existing system. Keep the law of diminishing returns in mind; adding more resources (either by scaling up or scaling out) can help to achieve parallelism, however there's a certain limit that's unique to each scenario to achieve the parallelism. Discover the optimal configuration for each identified use case in your testing.
- Goal B: We need to know if our data scientists can build and train machine learning models on this platform.
- Output B: We will have tested some of our machine learning models by training them on data in a Spark pool or a SQL pool, leveraging different machine learning libraries. These tests will help to determine which machine learning models can be migrated to the new environment
- Test B1: Specific machine learning models will be tested.
- Test B2: Test base machine learning libraries that come with Spark (Spark MLLib) along with an additional library that can be installed on Spark (like scikit-learn) to meet the requirement.
- Goal C: We will have tested data ingestion and will have the data points to:
- Estimate the effort for our initial historical data migration to data lake and/or the Spark pool.
- Plan an approach to migrate historical data.
- Output C: We will have tested and determined the data ingestion rate achievable in our environment and can determine whether our data ingestion rate is sufficient to migrate historical data during the available time window.
- Test C1: Test different approaches of historical data migration. For more information, see Transfer data to and from Azure.
- Test C2: Identify allocated bandwidth of ExpressRoute and if there is any throttling setup by the infra team. For more information, see What is Azure ExpressRoute? (Bandwidth options).
- Test C3: Test data transfer rate for both online and offline data migration. For more information, see Copy activity performance and scalability guide.
- Test C4: Test data transfer from the data lake to the SQL pool by using either ADF, Polybase, or the COPY command. For more information, see Data loading strategies for dedicated SQL pool in Azure Synapse Analytics.
- Goal D: We will have tested the data ingestion rate of incremental data loading and will have the data points to estimate the data ingestion and processing time window to the data lake and/or the dedicated SQL pool.
- Output D: We will have tested the data ingestion rate and can determine whether our data ingestion and processing requirements can be met with the identified approach.
- Test D1: Test the daily update data ingestion and processing.
- Test D2: Test the processed data load to the dedicated SQL pool table from the Spark pool. For more information, see Azure Synapse Dedicated SQL Pool Connector for Apache Spark.
- Test D3: Execute the daily update load process concurrently while running end user queries.
Be sure to refine your tests by adding multiple testing scenarios. Azure Synapse makes it easy to test different scale (varying number of worker nodes, size of the worker nodes like small, medium, and large) to compare performance and behavior.
Here are some testing scenarios:
- Spark pool test A: We will execute data processing across multiple node types (small, medium, and large) as well as different numbers of worker nodes.
- Spark pool test B: We will load/retrieve processed data from the Spark pool to the dedicated SQL pool by using the connector.
- Spark pool test C: We will load/retrieve processed data from the Spark pool to Azure Cosmos DB via Azure Synapse Link.
Evaluate the POC dataset
Using the specific tests you identified, select a dataset to support the tests. Take time to review this dataset. You should verify that the dataset will adequately represent your future processing in terms of content, complexity, and scale. Don't use a dataset that's too small (less than 1TB) because it won't deliver representative performance. Conversely, don't use a dataset that's too large because the POC shouldn't become a full data migration. Be sure to obtain the appropriate benchmarks from existing systems so you can use them for performance comparisons.
Important
Make sure you check with business owners for any blockers before moving any data to the cloud. Identify any security or privacy concerns or any data obfuscation needs that should be done before moving data to the cloud.
Create a high-level architecture
Based upon the high-level architecture of your proposed future state architecture, identify the components that will form part of your POC. Your high-level future state architecture likely contains many data sources, numerous data consumers, big data components, and possibly machine learning and artificial intelligence (AI) data consumers. Your POC architecture should specifically identify components that will be part of the POC. Importantly, it should identify any components that won't form part of the POC testing.
If you're already using Azure, identify any resources you already have in place (Microsoft Entra ID, ExpressRoute, and others) that you can use during the POC. Also identify the Azure regions your organization uses. Now is a great time to identify the throughput of your ExpressRoute connection and to check with other business users that your POC can consume some of that throughput without adverse impact on production systems.
For more information, see Big data architectures.
Identify POC resources
Specifically identify the technical resources and time commitments required to support your POC. Your POC will need:
- A business representative to oversee requirements and results.
- An application data expert, to source the data for the POC and provide knowledge of the existing processes and logic.
- An Apache Spark and Spark pool expert.
- An expert advisor, to optimize the POC tests.
- Resources that will be required for specific components of your POC project, but not necessarily required for the duration of the POC. These resources could include network admins, Azure admins, Active Directory admins, Azure portal admins, and others.
- Ensure all the required Azure services resources are provisioned and the required level of access is granted, including access to storage accounts.
- Ensure you have an account that has required data access permissions to retrieve data from all data sources in the POC scope.
Tip
We recommend engaging an expert advisor to assist with your POC. Microsoft's partner community has global availability of expert consultants who can help you assess, evaluate, or implement Azure Synapse.
Set the timeline
Review your POC planning details and business needs to identify a time frame for your POC. Make realistic estimates of the time that will be required to complete the POC goals. The time to complete your POC will be influenced by the size of your POC dataset, the number and complexity of tests, and the number of interfaces to test. If you estimate that your POC will run longer than four weeks, consider reducing the POC scope to focus on the highest priority goals. Be sure to obtain approval and commitment from all the lead resources and sponsors before continuing.
Put the POC into practice
We recommend you execute your POC project with the discipline and rigor of any production project. Run the project according to plan and manage a change request process to prevent uncontrolled growth of the POC's scope.
Here are some examples of high-level tasks:
Create a Synapse workspace, Spark pools and dedicated SQL pools, storage accounts, and all Azure resources identified in the POC plan.
Load POC dataset:
- Make data available in Azure by extracting from the source or by creating sample data in Azure. For more information, see:
- Test the dedicated connector for the Spark pool and the dedicated SQL pool.
Migrate existing code to the Spark pool:
- If you're migrating from Spark, your migration effort is likely to be straightforward given that the Spark pool leverages the open-source Spark distribution. However, if you're using vendor specific features on top of core Spark features, you'll need to correctly map these features to the Spark pool features.
- If you're migrating from a non-Spark system, your migration effort will vary based on the complexity involved.
Execute the tests:
- Many tests can be executed in parallel across multiple Spark pool clusters.
- Record your results in a consumable and readily understandable format.
Monitor for troubleshooting and performance. For more information, see:
Monitor data skewness, time skewness and executor usage percentage by opening the Diagnostic tab of Spark's history server.
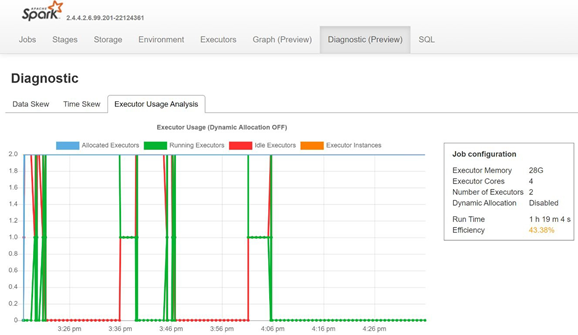
Interpret the POC results
When you complete all the POC tests, you evaluate the results. Begin by evaluating whether the POC goals were met and the desired outputs were collected. Determine whether more testing is necessary or any questions need addressing.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for