Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
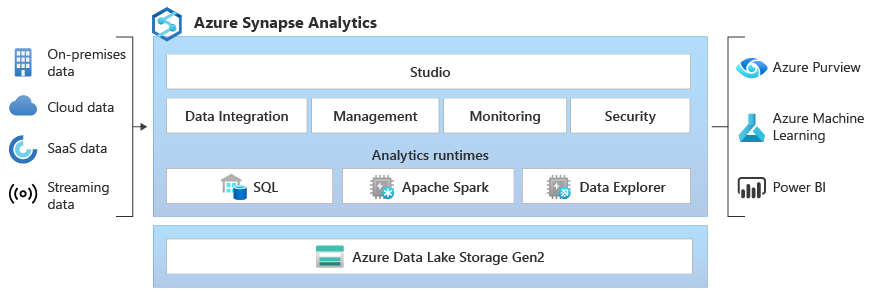
Azure Synapse is an enterprise analytics service that accelerates time to insight across data warehouses and big data systems. Azure Synapse brings together the best of SQL technologies used in enterprise data warehousing, Spark technologies used for big data, Data Explorer for log and time series analytics, Pipelines for data integration and ETL/ELT, and deep integration with other Azure services such as Power BI, CosmosDB, and AzureML.
Industry-leading SQL
Synapse SQL is a distributed query system for T-SQL that enables data warehousing and data virtualization scenarios and extends T-SQL to address streaming and machine learning scenarios.
- Synapse SQL offers both serverless and dedicated resource models. For predictable performance and cost, create dedicated SQL pools to reserve processing power for data stored in SQL tables. For unplanned or bursty workloads, use the always-available, serverless SQL endpoint.
- Use built-in streaming capabilities to land data from cloud data sources into SQL tables
- Integrate AI with SQL by using machine learning models to score data using the T-SQL PREDICT function
Industry-standard Apache Spark
Apache Spark for Azure Synapse deeply and seamlessly integrates Apache Spark--the most popular open source big data engine used for data preparation, data engineering, ETL, and machine learning.
- ML models with SparkML algorithms and Azure Machine Learning integration for Apache Spark 3.1 with built-in support for Linux Foundation Delta Lake.
- Simplified resource model that frees you from having to worry about managing clusters.
- Fast Spark start-up and aggressive autoscaling.
- Built-in support for .NET for Spark allowing you to reuse your C# expertise and existing .NET code within a Spark application.
Working with your Data Lake
Azure Synapse removes the traditional technology barriers between using SQL and Spark together. You can seamlessly mix and match based on your needs and expertise.
- Tables defined on files in the data lake are seamlessly consumed by either Spark or SQL.
- SQL and Spark can directly explore and analyze Parquet, CSV, TSV, and JSON files stored in the data lake.
- Fast, scalable data loading between SQL and Spark databases
Built-in data integration
Azure Synapse contains the same Data Integration engine and experiences as Azure Data Factory, allowing you to create rich at-scale ETL pipelines without leaving Azure Synapse Analytics.
- Ingest data from 90+ data sources
- Code-Free ETL with Data flow activities
- Orchestrate notebooks, Spark jobs, stored procedures, SQL scripts, and more
Data Explorer (Preview)
Azure Synapse Data Explorer provides customers with an interactive query experience to unlock insights from system-generated logs. To complement existing SQL and Apache Spark analytics runtime engines, Data Explorer analytics runtime is optimized for efficient log analytics using powerful indexing technology to automatically index free-text and semi-structured data commonly found in the system-generated logs.
Use Data Explorer as a data platform for building near real-time log analytics and IoT analytics solutions to:
- Consolidate and correlate your logs and events data across on-premises, cloud, and third-party data sources.
- Accelerate your AI Ops journey (pattern recognition, anomaly detection, forecasting, and more)
- Replace infrastructure-based log search solutions to save cost and increase productivity.
- Build IoT Analytics solution for your IoT data.
- Build Analytical SaaS solutions to offer services to your internal and external customers.
Unified experience
Synapse Studio provides a single way for enterprises to build solutions, maintain, and secure all in a single user experience
- Perform key tasks: ingest, explore, prepare, orchestrate, visualize
- Monitor resources, usage, and users across SQL, Spark, and Data Explorer
- Use Role-based access control to simplify access to analytics resources
- Write SQL, Spark, or KQL code and integrate with enterprise CI/CD processes
Engage with the Synapse community
- Microsoft Q&A: Ask technical questions.
- Stack Overflow: Ask development questions.