Manage libraries for Apache Spark pools in Azure Synapse Analytics
Once you have identified the Scala, Java, R (Preview), or Python packages that you would like to use or update for your Spark application, you can install or remove them into a Spark pool. Pool-level libraries are available to all notebooks and jobs running on the pool.
There are two primary ways to install a library on a Spark pool:
- Install a workspace library that has been uploaded as a workspace package.
- For updating Python libraries, provide a requirements.txt or Conda environment.yml environment specification to install packages from repositories like PyPI, Conda-Forge, and more. Read the section about environment specification for further information.
After the changes are saved, a Spark job will run the installation and cache the resulting environment for later reuse. Once the job is complete, new Spark jobs or notebook sessions will use the updated pool libraries.
Important
- If the package you are installing is large or takes a long time to install, this affects the Spark instance start up time.
- Altering the PySpark, Python, Scala/Java, .NET, R, or Spark version is not supported.
- Installing packages from external repositories like PyPI, Conda-Forge, or the default Conda channels is not supported within data exfiltration protection enabled workspaces.
Manage packages from Synapse Studio or Azure portal
Spark pool libraries can be managed either from the Synapse Studio or Azure portal.
To update or add libraries to a Spark pool:
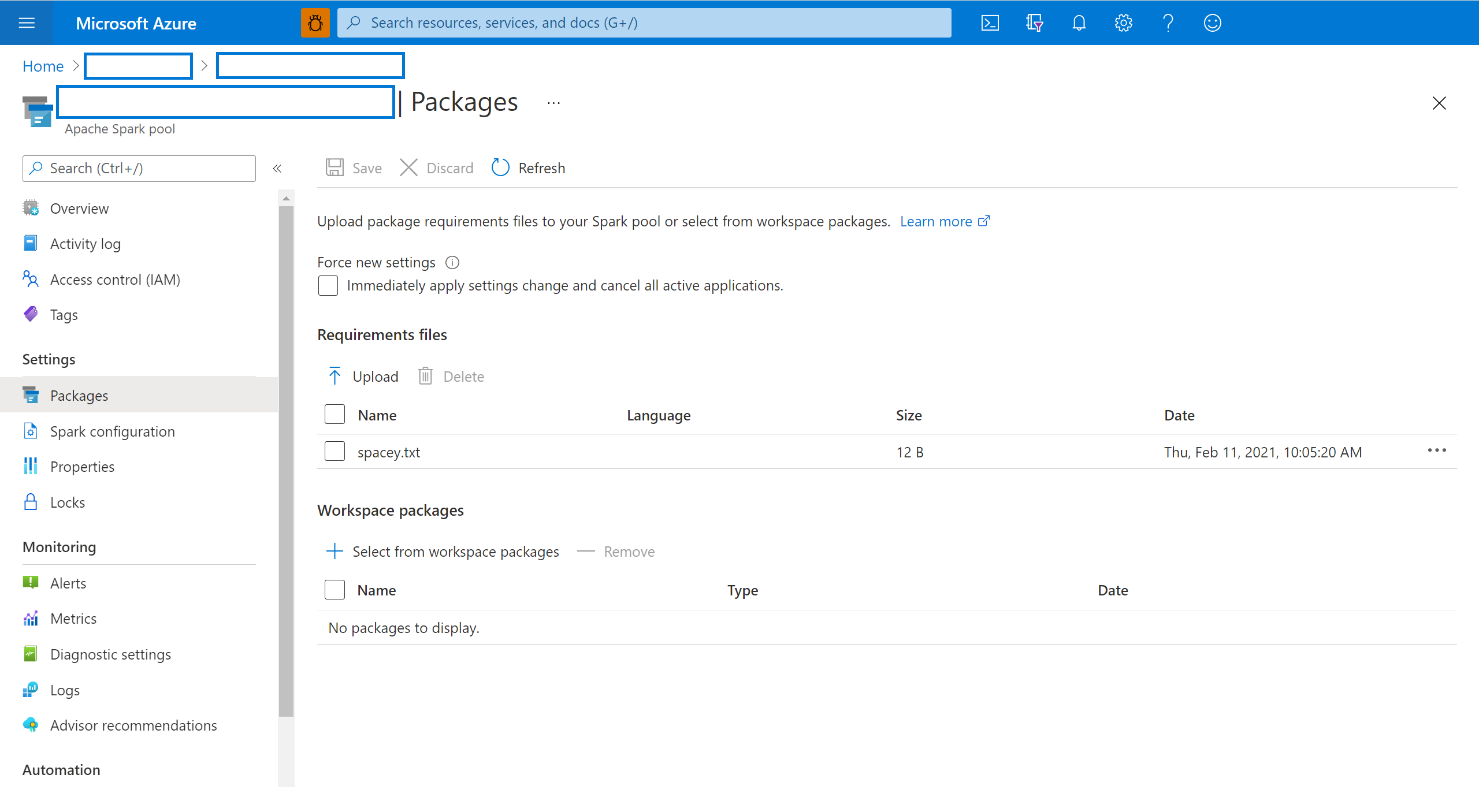
Navigate to your Azure Synapse Analytics workspace from the Azure portal.
If you are updating from the Azure portal:
Under the Synapse resources section, select the Apache Spark pools tab and select a Spark pool from the list.
Select the Packages from the Settings section of the Spark pool.
If you are updating from the Synapse Studio:
Select Manage from the main navigation panel and then select Apache Spark pools.
Select the Packages section for a specific Spark pool.
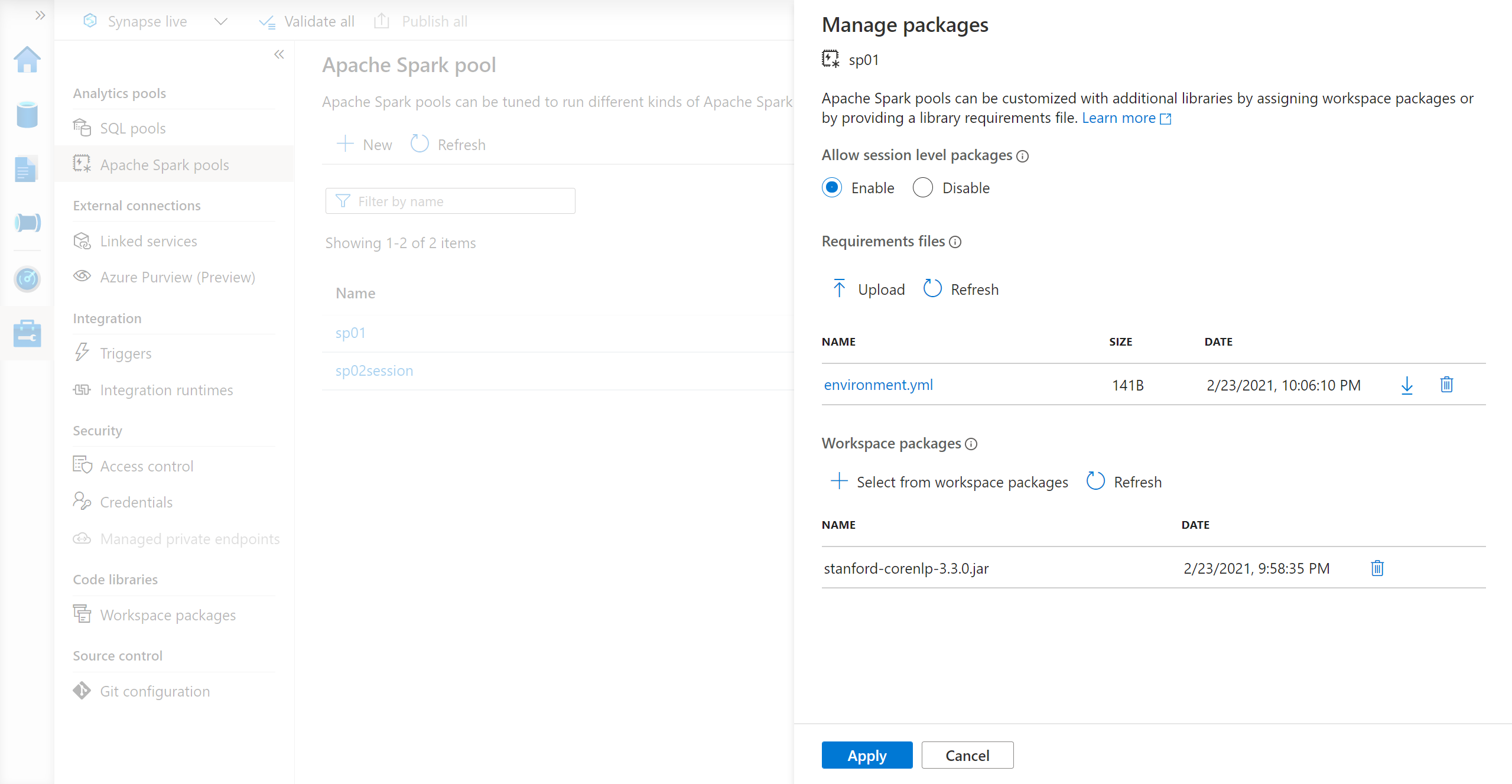
For Python feed libraries, upload the environment configuration file using the file selector in the Packages section of the page.
You can also select additional workspace packages to add Jar, Wheel, or Tar.gz files to your pool.
You can also remove the deprecated packages from Workspace packages section, your pool will no longer attach these packages.
Once you save your changes, a system job will be triggered to install and cache the specified libraries. This process helps reduce overall session startup time.
Once the job has successfully completed, all new sessions will pick up the updated pool libraries.


Important
By selecting the option to Force new settings, you will end the all current sessions for the selected Spark pool. Once the sessions are ended, you will have to wait for the pool to restart.
If this setting is unchecked, then you will have to wait for the current Spark session to end or stop it manually. Once the session has ended, you will need to let the pool restart.
Track installation progress
A system reserved Spark job is initiated each time a pool is updated with a new set of libraries. This Spark job helps monitor the status of the library installation. If the installation fails due to library conflicts or other issues, the Spark pool will revert to its previous or default state.
In addition, users can also inspect the installation logs to identify dependency conflicts or see which libraries were installed during the pool update.
To view these logs:
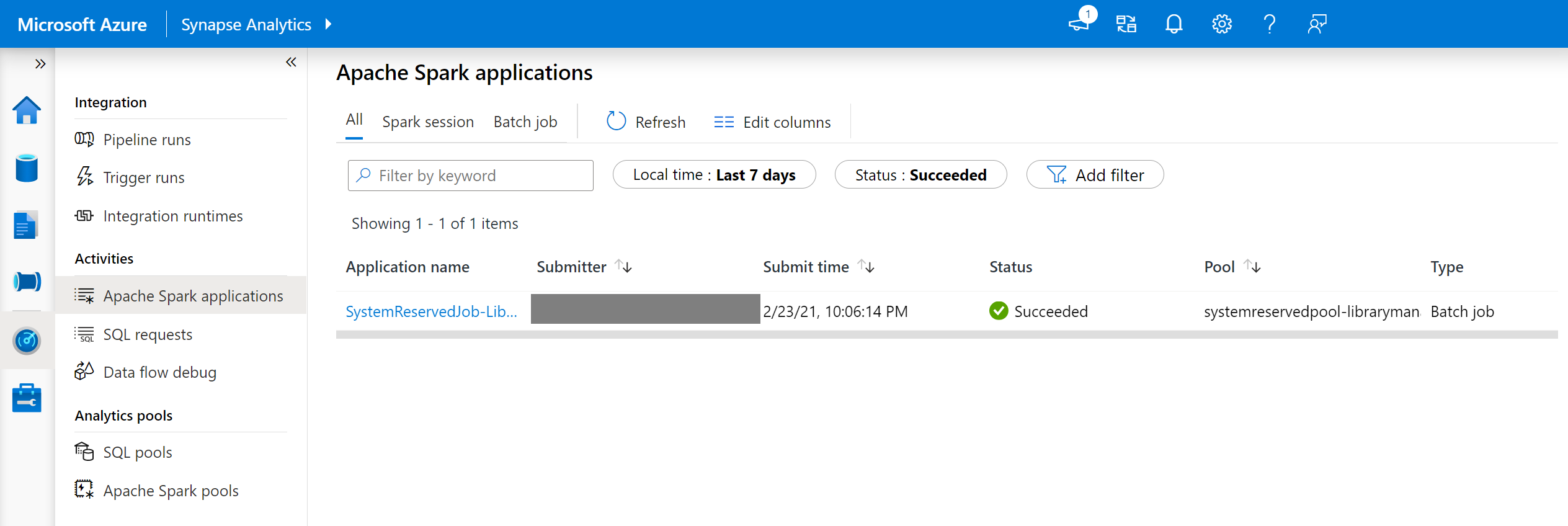
- Navigate to the Spark applications list in the Monitor tab.
- Select the system Spark application job that corresponds to your pool update. These system jobs run under the SystemReservedJob-LibraryManagement title.
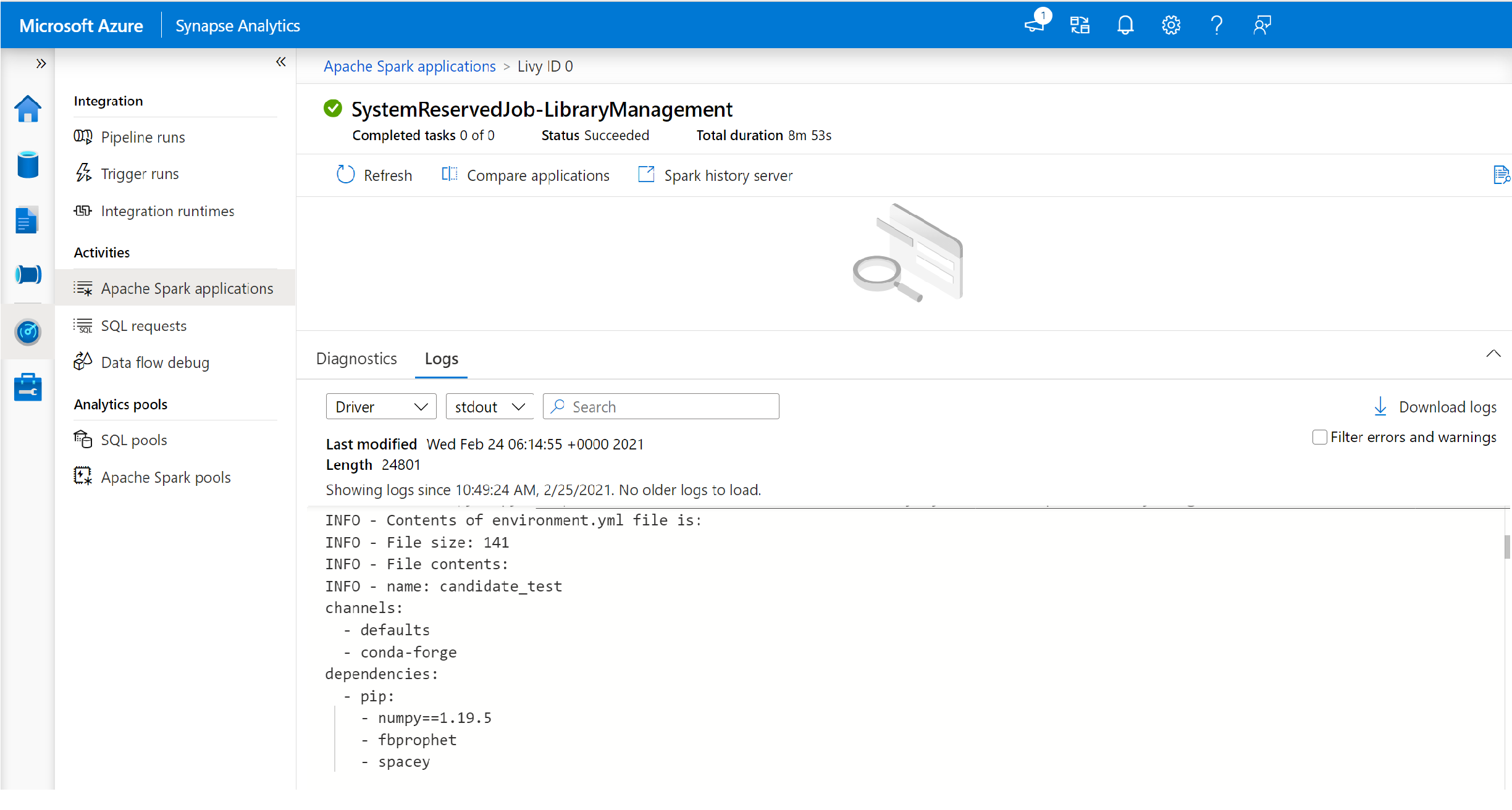
- Switch to view the driver and stdout logs.
- Within the results, you will see the logs related to the installation of your dependencies.


Environment specification formats
PIP requirements.txt
A requirements.txt file (output from the pip freeze command) can be used to upgrade the environment. When a pool is updated, the packages listed in this file are downloaded from PyPI. The full dependencies are then cached and saved for later reuse of the pool.
The following snippet shows the format for the requirements file. The PyPI package name is listed along with an exact version. This file follows the format described in the pip freeze reference documentation.
This example pins a specific version.
absl-py==0.7.0
adal==1.2.1
alabaster==0.7.10
YML format
In addition, you can also provide an environment.yml file to update the pool environment. The packages listed in this file are downloaded from the default Conda channels, Conda-Forge, and PyPI. You can specify other channels or remove the default channels by using the configuration options.
This example specifies the channels and Conda/PyPI dependencies.
name: stats2
channels:
- defaults
dependencies:
- bokeh
- numpy
- pip:
- matplotlib
- koalas==1.7.0
For details on creating an environment from this environment.yml file, see Creating an environment from an environment.yml file.
Next steps
- View the default libraries: Apache Spark version support
- Troubleshoot library installation errors: Troubleshoot library errors