Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Tip
Microsoft Fabric Data Warehouse is an enterprise scale relational warehouse on a data lake foundation, with a future-ready architecture, built-in AI, and new features. If you're new to data warehousing, start with Fabric Data Warehouse. Existing dedicated SQL pool workloads can upgrade to Fabric to access new capabilities across data science, real-time analytics, and reporting.
In this tutorial, you'll learn how to:
- Create demo database
- Create view used for report
- Connect Power BI Desktop to serverless SQL pool
- Create report based on view
Prerequisites
To complete this tutorial, you need the following prerequisites:
- Power BI Desktop - needed to visualize the data and create a report.
- Azure Synapse workspace - needed to create database, external data source, and view.
Optional:
- A SQL query tool, such as the MSSQL extension for Visual Studio Code, or SQL Server Management Studio (SSMS).
Values for the following parameters:
| Parameter | Description |
|---|---|
| Serverless SQL pool service endpoint address | Used as server name |
| Serverless SQL pool service endpoint region | Used to determine the storage used in the samples |
| Username and password for endpoint access | Used to access endpoint |
| Database you'll use to create views | The database used as starting point in the samples |
1 - Create database
For the demo environment, create your own demo database. You use this database to view metadata, not to store actual data.
Create the demo database (and drop an existing database if necessary) by running the following Transact-SQL (T-SQL) script:
-- Drop database if it exists
DROP DATABASE IF EXISTS Demo
GO
-- Create new database
CREATE DATABASE [Demo];
GO
2 - Create data source
A data source is necessary for the serverless SQL pool service to access files in storage. Create the data source for a storage account that is located in the same region as your endpoint. Although serverless SQL pool can access storage accounts from different regions, having the storage and endpoint in the same region provides better performance.
Create the data source by running the following Transact-SQL (T-SQL) script:
-- There is no credential in data source. We are using public storage account which doesn't need a secret.
CREATE EXTERNAL DATA SOURCE AzureOpenData
WITH ( LOCATION = 'https://azureopendatastorage.blob.core.windows.net/')
3 - Prepare view
Create the view based on the external demo data for Power BI to consume by running the following Transact-SQL (T-SQL) script:
Create the view usPopulationView inside the database Demo with the following query:
DROP VIEW IF EXISTS usPopulationView;
GO
CREATE VIEW usPopulationView AS
SELECT
*
FROM
OPENROWSET(
BULK 'censusdatacontainer/release/us_population_county/year=20*/*.parquet',
DATA_SOURCE = 'AzureOpenData',
FORMAT='PARQUET'
) AS uspv;
The demo data contains the following data sets:
US population by gender and race for each US county sourced from 2000 and 2010 Decennial Census in parquet format.
| Folder path | Description |
|---|---|
| /release/ | Parent folder for data in demo storage account |
| /release/us_population_county/ | US population data files in Parquet format, partitioned by year using Hive/Hadoop partitioning scheme. |
4 - Create Power BI report
Create the report for Power BI Desktop using the following steps:
Open the Power BI Desktop application and select Get data.
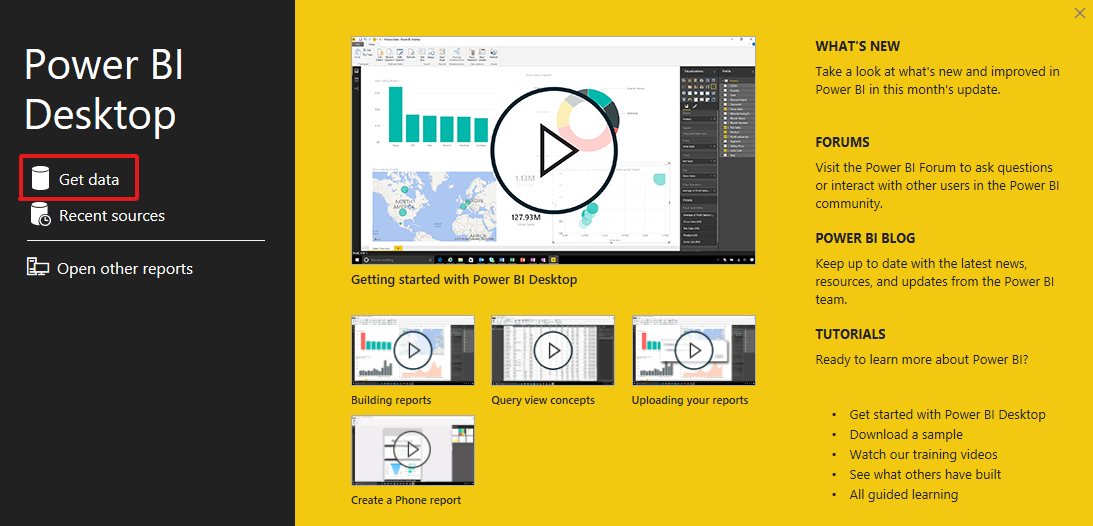
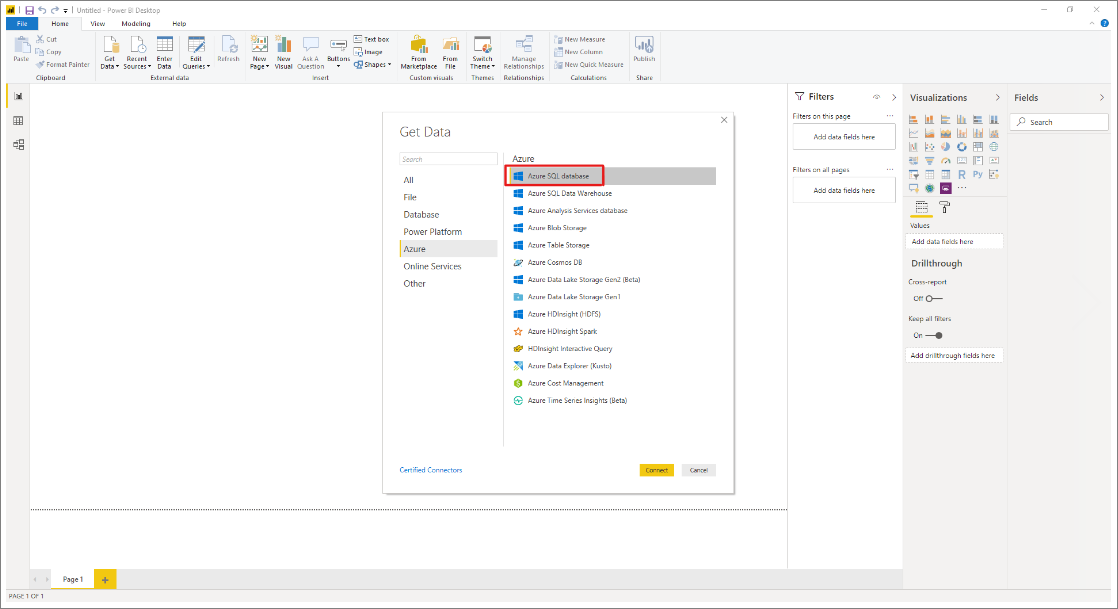
Select Azure > Azure SQL Database.
Type the name of the server where the database is located in the Server field, and then type
Demoin the database name. Select the Import option and then select OK.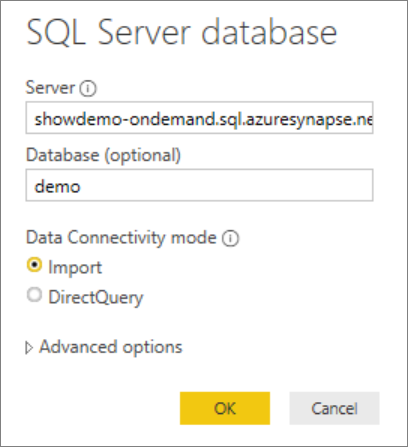
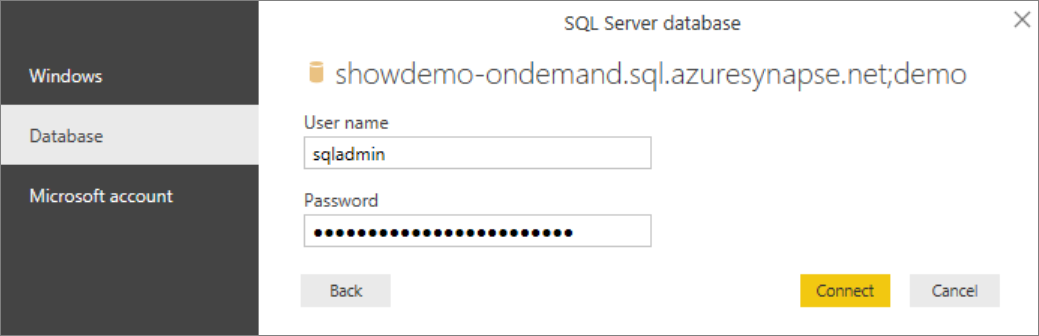
Select preferred authentication method:
Example for AAD
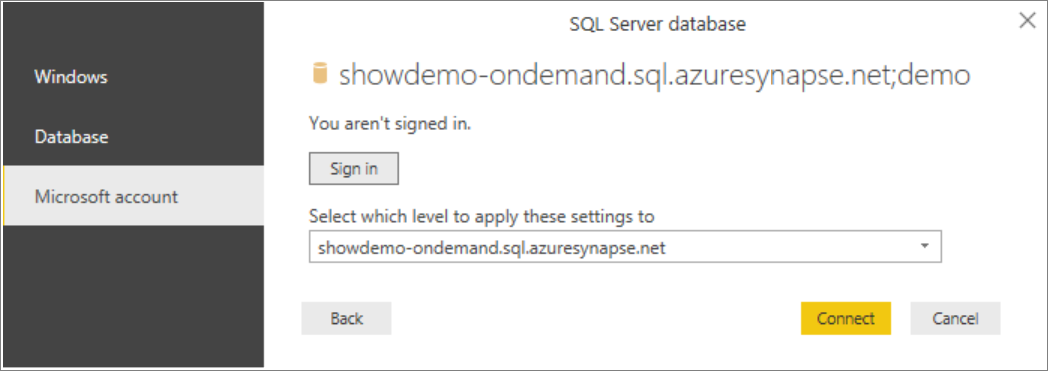
Example for SQL Login - Type your User name and password.
Select the view
usPopulationView, and then select Load.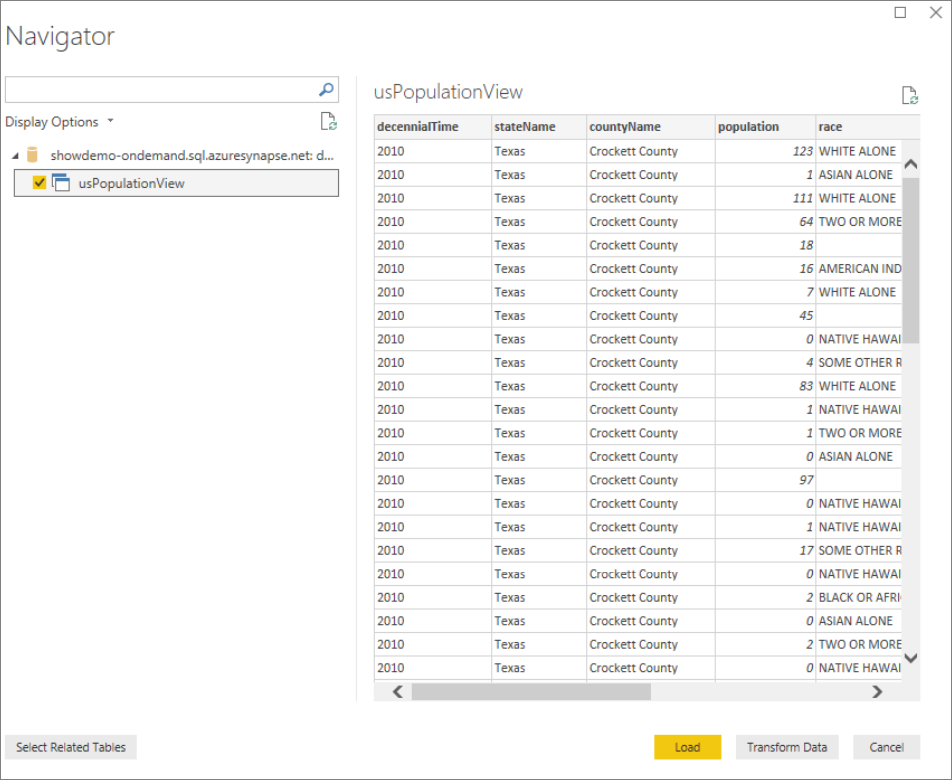
Wait for the operation to complete, and then a pop-up will appear stating
There are pending changes in your queries that haven't been applied. Select Apply changes.
Wait for the Apply query changes dialog box to disappear, which may take a few minutes.
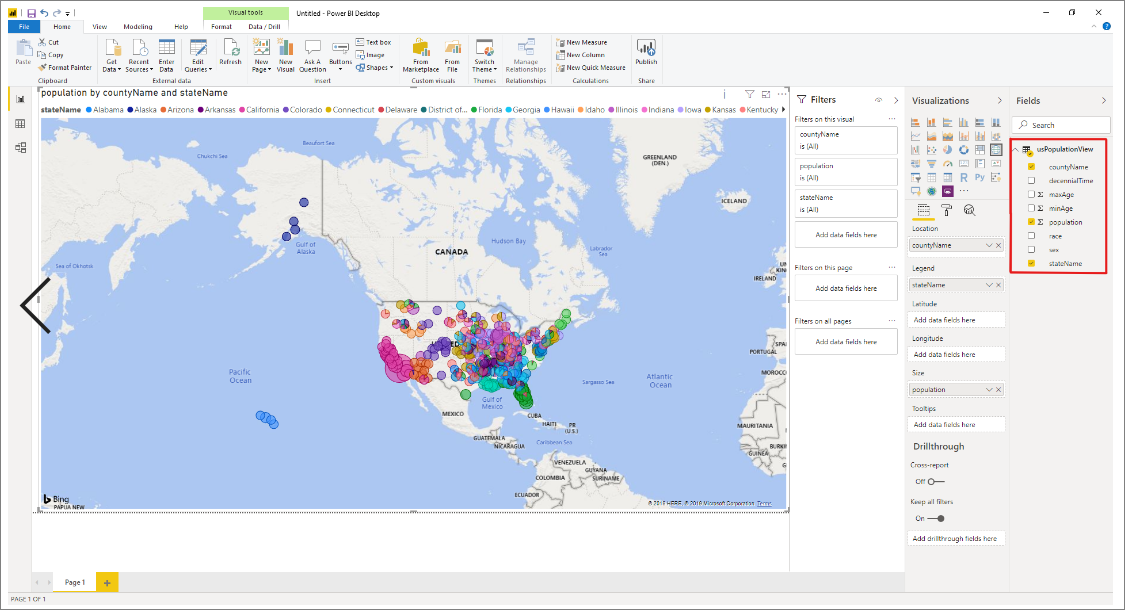
Once the load completes, select the following columns in this order to create the report:
- countyName
- population
- stateName
Clean up resources
Once you're done using this report, delete the resources with the following steps:
Delete the credential for the storage account
DROP EXTERNAL DATA SOURCE AzureOpenDataDelete the view
DROP VIEW usPopulationView;Drop the database
DROP DATABASE Demo;
Next steps
Advance to the Query storage files to learn how to query storage files using Synapse SQL.