Azure Virtual Desktop disaster recovery concepts
Azure Virtual Desktop has grown tremendously as a remote and hybrid work solution in recent years. Because so many users now work remotely, organizations require solutions with high deployment speed and reduced costs. Users also need to have a remote work environment with guaranteed availability and resiliency that lets them access their virtual machines even during disasters. This document describes disaster recovery plans that we recommend for keeping your organization up and running.
To prevent system outages or downtime, every system and component in your Azure Virtual Desktop deployment must be fault-tolerant. Fault tolerance is when you have a duplicate configuration or system in another Azure region that takes over for the main configuration during an outage. This secondary configuration or system reduces the impact of a localized outage. There are many ways you can set up fault tolerance, but this article will focus on the methods currently available in Azure.
Azure Virtual Desktop infrastructure
In order to figure out which areas to make fault-tolerant, we first need to know who's responsible for maintaining each area. You can divide responsibility in the Azure Virtual Desktop service into two areas: Microsoft-managed and customer-managed. Metadata like the host pools, application groups, and workspaces is controlled by Microsoft. The metadata is always available and doesn't require extra setup by the customer to replicate host pool data or configurations. We've designed the gateway infrastructure that connects people to their session hosts to be a global, highly resilient service managed by Microsoft. Meanwhile, customer-managed areas involve the virtual machines (VMs) used in Azure Virtual Desktop and the settings and configurations unique to the customer's deployment. The following table gives a clearer idea of which areas are managed by which party.
| Managed by Microsoft | Managed by customer |
|---|---|
| Load balancer | Network |
| Session broker | Session hosts |
| Gateway | Storage |
| Diagnostics | User profile data |
| Cloud identity platform | Identity |
In this article, we're going to focus on customer-managed components, as these are settings you can configure yourself.
Disaster recovery basics
In this section, we'll discuss actions and design principles that can protect your data and prevent having huge data recovery efforts after small outages or full-blown disasters. For smaller outages, following certain smaller steps can help prevent them from becoming bigger disasters. Let's go over some basic terms that will help you when you start setting up your disaster recovery plan.
When you design a disaster recovery plan, you should keep the following three things in mind:
- High availability: distributing infrastructure so smaller, more localized outages don't interrupt your entire deployment. Designing with HA in mind can minimize outage impact and avoid the need for a full disaster recovery.
- Business continuity: how an organization can keep operating during outages of any size.
- Disaster recovery: the process of getting back to operation after a full outage.
Azure has many built-in, free-of-charge features that can deliver high availability at many levels. The first feature is availability sets, which distribute VMs across different fault and update domains within Azure. Next are availability zones, which are physically isolated and geographically distributed groups of data centers that can reduce the impact of an outage. Finally, distributing session hosts across multiple Azure regions provides even more geographical distribution, which further reduces outage impact. All three features provide a certain level of protection within Azure Virtual Desktop, and you should carefully consider them along with any cost implications.
Basically, the disaster recovery strategy we recommend for Azure Virtual Desktop is to deploy resources across multiple availability zones within a region. If you need more protection, you can also deploy resources across multiple paired Azure regions.
Active-passive and active-active deployments
Something else you should keep in mind is the difference between active-passive and active-active plans. Active-passive plans are when you have a region with one set of resources that's active and one that's turned off until it's needed (passive). If the active region is taken offline by an emergency, the organization can switch to the passive region by turning it on and moving all their users there.
Another option is an active-active deployment, where you use both sets of infrastructure at the same time. While some users may be affected by outages, the impact is limited to the users in the region that went down. Users in the other region that's still online won't be affected, and the recovery is limited to the users in the affected region reconnecting to the functioning active region. Active-active deployments can take many forms, including:
- Overprovisioning infrastructure in each region to accommodate affected users in the event one of the regions goes down. A potential drawback to this method is that maintaining the additional resources costs more.
- Have extra session hosts in both active regions, but deallocate them when they aren't needed, which reduces costs.
- Only provision new infrastructure during disaster recovery and allow affected users to connect to the newly provisioned session hosts. This method requires regular testing with infrastructure-as-code tools so you can deploy the new infrastructure as quickly as possible during a disaster.
Recommended disaster recovery methods
The disaster recovery methods we recommend are:
Configure and deploy Azure resources across multiple availability zones.
Configure and deploy Azure resources across multiple regions in either active-active or active-passive configurations. These configurations are typically found in shared host pools.
For personal host pools with dedicated VMs, replicate VMs using Azure Site Recovery to another region.
Configure a separate "disaster recovery" host pool in the secondary region. During a disaster, you can switch users over to the secondary region.
We'll go into more detail about the two main methods you can achieve these methods with for shared and personal host pools in the following sections.
Disaster recovery for shared host pools
In this section, we'll discuss shared (or "pooled") host pools using an active-passive approach. The active-passive approach is when you divide up existing resources into a primary and secondary region. Normally, your organization would do all its work in the primary (or "active") region, but during a disaster, all it takes to switch over to the secondary (or "passive") region is to turn off the resources in the primary region (if you can do so, depending on the outage's extent) and turn on the ones in the secondary one.
The following diagram shows an example of a deployment with redundant infrastructure in a secondary region. "Redundant" means that a copy of the original infrastructure exists in this other region, and is standard in deployments to provide resiliency for all components. Beneath a single Microsoft Entra ID, there are two regions: West US and East US. Each region has two session hosts running a multi-session operating system (OS), A server running Microsoft Entra Connect, an Active Directory Domain Controller, an Azure Files Premium File share for FSLogix profiles, a storage account, and a virtual network (VNET). In the primary region, West US, all resources are turned on. In the secondary region, East US, the session hosts in the host pool are either turned off or in drain mode, and the Microsoft Entra Connect server is in staging mode. The two VNETs in both regions are connected by peering.
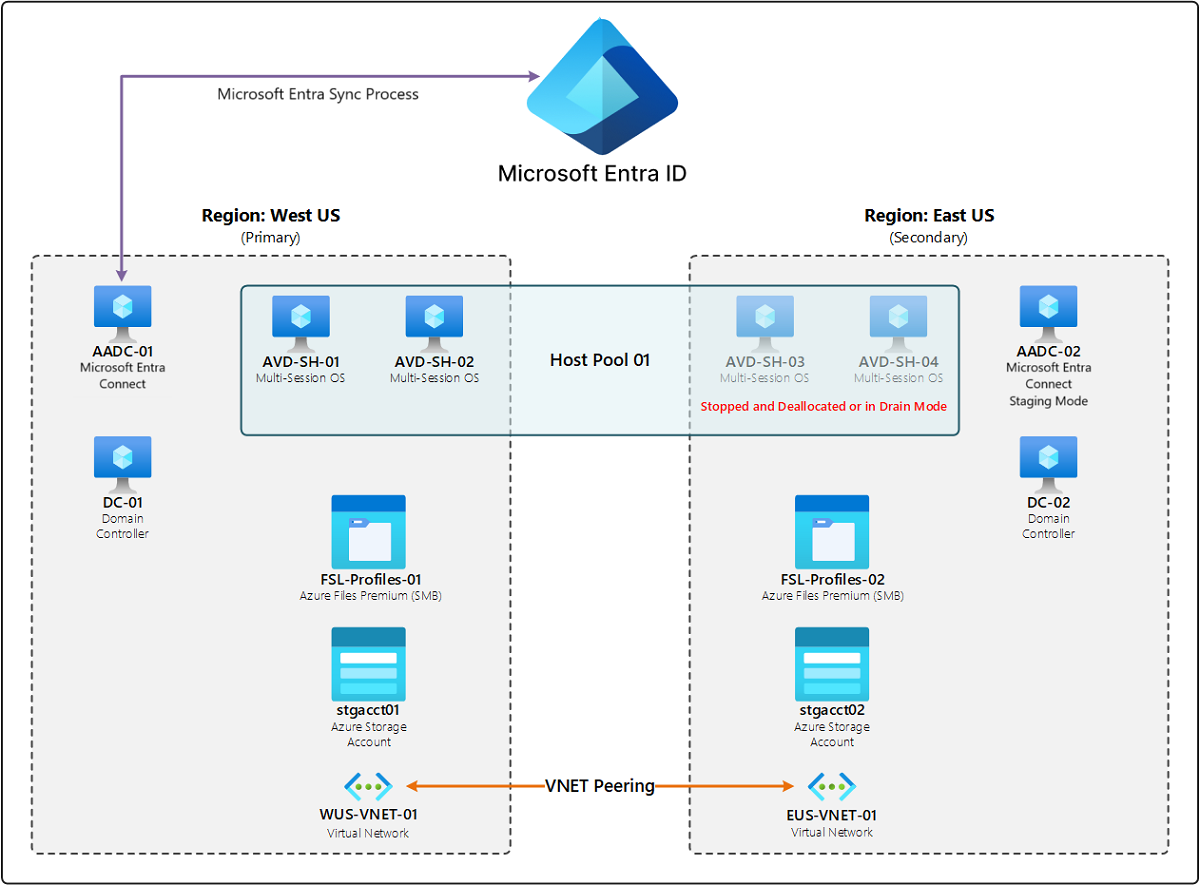
In most cases, if a component fails or the primary region isn't available, then the only action the customer needs to perform is to turn on the hosts or remove drain mode in the secondary region to enable end-user connections. This scenario focuses on reducing downtime. However, a redundancy-based disaster recovery plan may cost more due to having to maintain those extra components in the secondary region.
The potential benefits of this plan are as follows:
- Less time spent recovering from disasters. For example, you'll spend less time on provisioning, configuring, integrating, and validating newly deployed resources.
- There's no need to use complicated procedures.
- It's easy to test failover outside of disasters.
The potential drawbacks are as follows:
- May cost more due to having more infrastructure to maintain, such as storage accounts, hosts, and so on.
- You'll need to spend more time configuring your deployment to accommodate this plan.
- You need to maintain the extra infrastructure you set up even when you don't need it.
Important information for shared host pool recovery
When using this disaster recovery strategy, it's important to keep the following things in mind:
Having multiple session hosts online across many regions can impact user experience. The managed network load balancer doesn't account for geographic proximity, instead treating all hosts in a host pool equally.
During a disaster, users will be creating new profiles in the secondary region. You should store any business- or mission-critical data in OneDrive (using known folder redirection) or Sharepoint. Storing data here will give users quick access to their applications with minor disruption to the user experience.
Make sure that you configure your virtual machines (VMs) exactly the same way within your host pool. Also, make sure all VMs within your host pool are the same size. If your VMs aren't the same, the managed network load balancer will distribute user connections evenly across all available VMs. The smaller VMs may become resource-constrained earlier than expected compared to larger VMs, resulting in a negative user experience.
Region availability affects data or workspace monitoring. If a region isn't available, the service may lose all historical monitoring data during a disaster. We recommend using a custom export or dump of historical monitoring data.
We recommend you update your session hosts at least once every month. This recommendation applies to session hosts you keep turned off for extended periods of time.
Test your deployment by running a controlled failover at least once every six months. Part of the controlled failover could mean your secondary location becomes primary until the next controlled failover. Changing your secondary location to primary allows users to have nearly identical profiles during a real disaster.
The following table lists deployment recommendations for host pool disaster recovery strategies:
| Technology | Recommendations |
|---|---|
| Network | Create and deploy a secondary virtual network in another region and configure Azure Peering with your primary virtual network. |
| Session hosts | Create and deploy an Azure Virtual Desktop shared host pool with multi-session OS SKU and include VMs from other availability zones and another region. |
| Storage | Create storage accounts in multiple regions using premium-tier accounts. |
| User profile data | Create SMB storage locations in multiple regions. |
| Identity | Active Directory Domain Controllers from the same directory. |
Disaster recovery for personal host pools
For personal host pools, your disaster recovery strategy should involve replicating your resources to a secondary region using Azure Site Recovery Services Vault. If your primary region goes down during a disaster, Azure Site Recovery can fail over and turn on the resources in your secondary region.
For example, let's say we have a deployment with a primary region in the West US and a secondary region in the East US. The primary region has a personal host pool with two session hosts each. Each session host has their own local disk containing the user profile data and their own VNET that's not paired with anything. If there's a disaster, you can use Azure Site Recovery to fail over to the secondary region in East US (or to a different availability zone in the same region). Unlike the primary region, the secondary region doesn't have local machines or disks. During the failover, Azure Site Recovery takes the replicated data from the Azure Site Recovery Vault and uses it to create two new VMs that are copies of the original session hosts, including the local disk and user profile data. The secondary region has its own independent VNET, so the VNET going offline in the primary region won't affect functionality.
The following diagram shows the example deployment we just described.
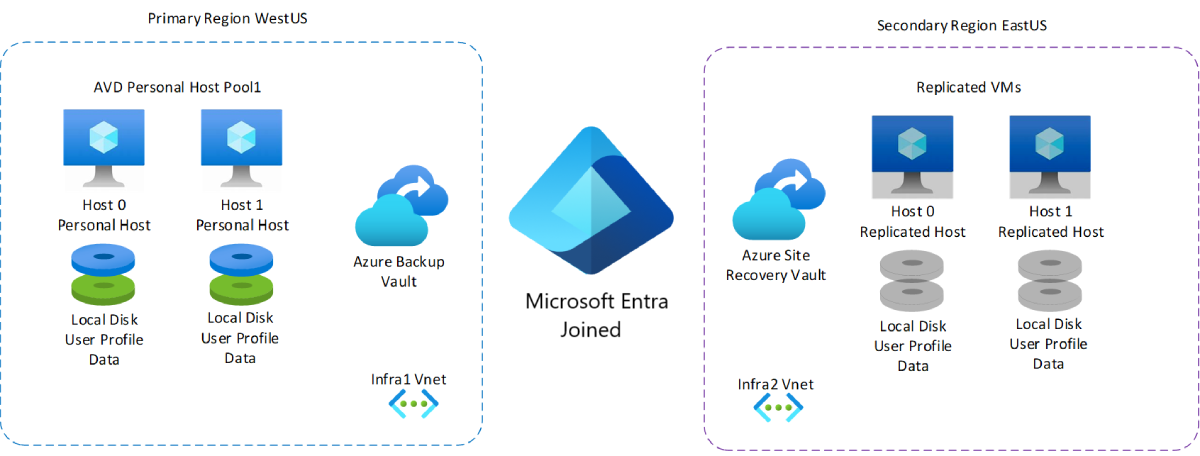
The benefits of this plan include a lower overall cost and not requiring maintenance to patch or update due to resources only being provisioned when you need them. However, a potential drawback is that you'll spend more time provisioning, integrating, and validating failover infrastructure than you would with a shared host pool disaster recovery setup.
Important information about personal host pool recovery
When using this disaster recovery strategy, it's important to keep the following things in mind:
There may be requirements that the host pool VMs need to function in the secondary site, such as virtual networks, subnets, network security, or VPNs to access a directory such as on-premises Active Directory.
Note
Using an Microsoft Entra joined VM fulfills some of these requirements automatically.
You may experience integration, performance, or contention issues for resources if a large-scale disaster affects multiple customers or tenants.
Personal host pools use VMs that are dedicated to one user, which means affinity load load-balancing rules direct all user sessions back to a specific VM. This one-to-one mapping between user and VM means that if a VM is down, the user won't be able to sign in until the VM comes back online or the VM is recovered after disaster recovery is finished.
VMs in a personal host pool store user profile on drive C, which means FSLogix isn't required.
Region availability affects data or workspace monitoring. If a region isn't available, the service may lose all historical monitoring data during a disaster. We recommend using a custom export or dump of historical monitoring data.
We recommend you avoid using FSLogix when using a personal host pool configuration.
Virtual machine provisioning isn't guaranteed in the failover region.
Run controlled failover and failback tests at least once every six months.
The following table lists deployment recommendations for host pool disaster recovery strategies:
| Technology | Recommendations |
|---|---|
| Network | Create and deploy a secondary virtual network in another region to follow custom naming conventions or security requirements outside of the Azure Site Recovery default naming scheme. |
| Session hosts | Enable and configure Azure Site Recovery for VMs. Optionally, you can pre-stage an image manually or use the Azure Image Builder service for ongoing provisioning. |
| Storage | Creating an Azure Storage account is optional to store profiles. |
| User profile data | User profile data is locally stored on drive C. |
| Identity | Active Directory Domain Controllers from the same directory across multiple regions. |
Next steps
For more in-depth information about disaster recovery in Azure, check out these articles:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for