Troubleshooting autoscale with Virtual Machine Scale Sets
Problem – you’ve created an autoscaling infrastructure in Azure Resource Manager using Virtual Machine Scale Sets – for example, by deploying a template like this one: https://github.com/Azure/azure-quickstart-templates/blob/master/application-workloads/python/vmss-bottle-autoscale/azuredeploy.parameters.json – you have your scale rules defined and it works great, except no matter how much load you put on the VMs, it doesn't autoscale.
Troubleshooting steps
Some things to consider include:
How many vCPUs does each VM have, and are you loading each vCPU? The preceding sample Azure Quickstart template has a do_work.php script, which loads a single vCPU. If you're using a VM bigger than a single-vCPU VM size like Standard_A1 or D1, you'd need to run this load multiple times. Check how many vCPUs for your VMs by reviewing Sizes for Windows virtual machines in Azure
How many VMs in the Virtual Machine Scale Set, are you doing work on each one?
A scale-out event only takes place when the average CPU across all the VMs in a scale set exceeds the threshold value, over the time internal defined in the autoscale rules.
Did you miss any scale events?
Check the audit logs in the Azure portal for scale events. Maybe there was a scale up and a scale down that was missed. You can filter by "Scale".
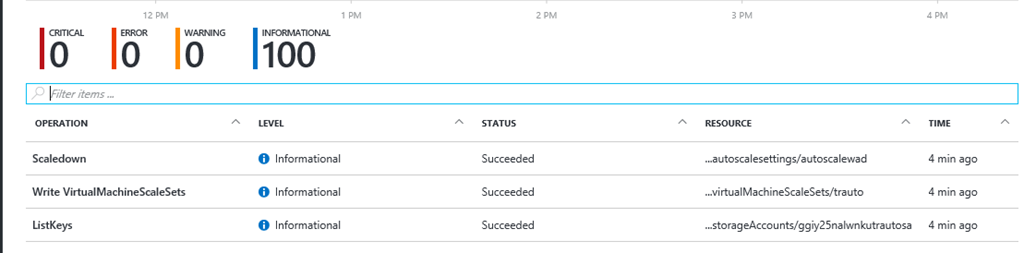
Are your scale-in and scale-out thresholds sufficiently different?
Suppose you set a rule to scale out when average CPU is greater than 50% over five minutes, and to scale in when average CPU is less than 50%. This setting would cause a "flapping" problem when CPU usage is close to the threshold, with scale actions constantly increasing and decreasing the size of the set. Because of this setting, the autoscale service tries to prevent "flapping", which can manifest as not scaling. Therefore, be sure your scale-out and scale-in thresholds are sufficiently different to allow some space in between scaling.
Did you write your own JSON template?
It is easy to make mistakes, so start with a template like the one above which is proven to work, and make small incremental changes.
Can you manually scale in or out?
Try redeploying the Virtual Machine Scale Set resource with a different "capacity" setting to change the number of VMs manually. An example template is here: https://github.com/Azure/azure-quickstart-templates/tree/master/quickstarts/microsoft.compute/vmss-scale-existing – you might need to edit the template to make sure it has the same machine size as your Scale Set uses. If you can successfully change the number of VMs manually, you then know the problem is isolated to autoscale.
Check your Microsoft.Compute/virtualMachineScaleSet, and Microsoft.Insights resources in the Azure Resource Explorer
The Azure Resource Explorer is an indispensable troubleshooting tool that shows you the state of your Azure Resource Manager resources. Click on your subscription and look at the Resource Group you are troubleshooting. Under the Compute resource provider, look at the Virtual Machine Scale Set you created and check the Instance View, which shows you the state of a deployment. Also, check the instance view of VMs in the Virtual Machine Scale Set. Then, go into the Microsoft.Insights resource provider and check that the autoscale rules look right.
Is the Diagnostic extension working and emitting performance data?
Update: Azure autoscale has been enhanced to use a host-based metrics pipeline, which no longer requires a diagnostics extension to be installed. The next few paragraphs no longer apply if you create an autoscaling application using the new pipeline. An example of Azure templates that have been converted to use the host pipeline is available here: https://github.com/Azure/azure-quickstart-templates/blob/master/application-workloads/python/vmss-bottle-autoscale/azuredeploy.parameters.json.
Using host-based metrics for autoscale is better for the following reasons:
Fewer moving parts as no diagnostics extensions need to be installed.
Simpler templates. Just add insights autoscale rules to an existing scale set template.
More reliable reporting and faster launching of new VMs.
The only reasons you might want to keep using a diagnostic extension is if you need memory diagnostics reporting/scaling. Host-based metrics don't report memory.
With that in mind, only follow the rest of this article if you're using diagnostic extensions for your autoscaling.
Autoscale in Azure Resource Manager can work (but no longer has to) by means of a VM extension called the Diagnostics Extension. It emits performance data to a storage account you define in the template. This data is then aggregated by the Azure Monitor service.
If the Insights service can't read data from the VMs, it is supposed to send you an email. For example, you get an email if the VMs are down. Be sure to check your email, at the email address you specified when you created your Azure account.
You can also look at the data yourself. Look at the Azure storage account using a cloud explorer. For example, using Visual Studio Cloud Explorer, log in and pick the Azure subscription you're using. Then, look at the Diagnostics storage account name referenced in the Diagnostics extension definition in your deployment template.
You see a bunch of tables where the data from each VM is being stored. Taking Linux and the CPU metric as an example, look at the most recent rows. Visual Studio Cloud Explorer supports a query language so you can run a query. For example, you can run a query for "Timestamp gt datetime'2016-02-02T21:20:00Z'" to make sure you get the most recent events. The timezone corresponds to UTC. Does the data you see in there correspond to the scale rules you set up? In the following example, the CPU for machine 20 started increasing to 100% over the last five minutes.
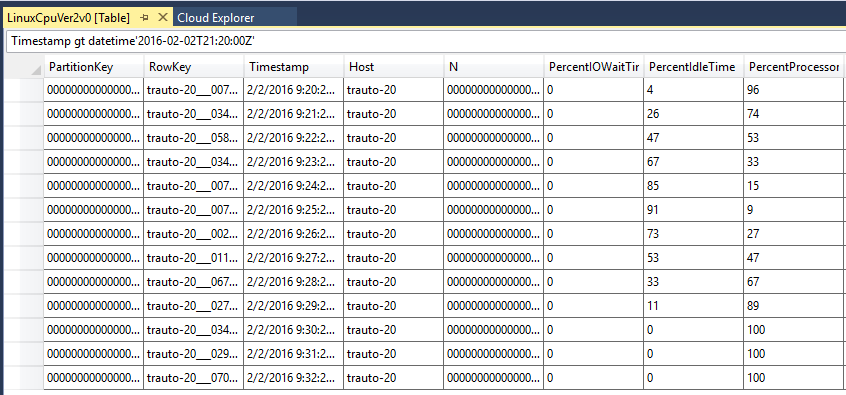
If the data is not there, it implies the problem is with the diagnostic extension running in the VMs. If the data is there, it implies there is either a problem with your scale rules, or with the Insights service. Check Azure Status.
Once you've been through these steps, if you're still having autoscale problems, you can try the following resources:
- Visit Troubleshooting common issue with VM Scale Sets page
- Read the forums on Microsoft Q&A question page, or Stack overflow
- Log a support call. Be prepared to share the template and a view of your performance data.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for