Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article discusses the application platform design area of an Azure VMware Solution workload. This area covers the specific tasks and responsibilities that are associated with deploying, configuring, and maintaining applications that you host in an Azure VMware Solution environment. An application owner is responsible for the applications in an Azure VMware Solution environment. This individual or team manages aspects that are related to the deployment, configuration, monitoring, and maintenance of the applications.
Key objectives of a well-architected application include:
- Designing for scale. Gracefully handle higher user demands and concurrent transactions without degradation or service interruption.
- Performance. Deliver fast, low-latency response times, and efficiently manage resource utilization.
- Reliability and resiliency. Design redundant, fault-tolerant patterns to help ensure that your application remains responsive and recovers quickly from failures.
This article aims to provide developers, architects, and application owners with best practices that are specific to Azure VMware Solution. These practices can help you build applications that remain robust, secure, scalable, and maintainable throughout their lifecycle.
Design for scalability and efficient resource distribution
Impact: Reliability, Performance efficiency, Security
This section covers the effective allocation and utilization of computing resources across virtual machines (VMs) and workloads within the Azure VMware Solution private cloud. These resources can include CPU, memory, storage, and network resources. This section also explores the implementation of responsive scaling techniques. You can use these techniques to dynamically adapt resource provisioning to accommodate fluctuations in demand. The primary objective is to achieve optimal resource utilization by mitigating underutilization and overprovisioning that can result in inefficiencies and escalated expenses.
Use fault domains
Fault domains in Azure VMware Solution represent logical groupings of resources within a stretched cluster. These resources share a common physical fault domain. Fault domains help improve availability in various failure scenarios. Organizing resources into fault domains helps ensure that critical components of an application are spread across multiple failure domains.
By placing VMs and other resources into separate fault domains, the application team helps ensure that an application remains available during a datacenter or infrastructure failure. For example, you might separate VMs into fault domains that are spread across geographically distributed datacenters. Then your application can remain operational if one datacenter experiences a complete failure.
Application teams should consider defining VM-VM affinity and anti-affinity rules that are based on fault domains. VM-VM affinity rules place critical VMs in the same fault domain to ensure that they aren't spread across multiple datacenters. Anti-affinity rules prevent related VMs from being placed together within the same fault domain. This practice helps ensure redundancy.
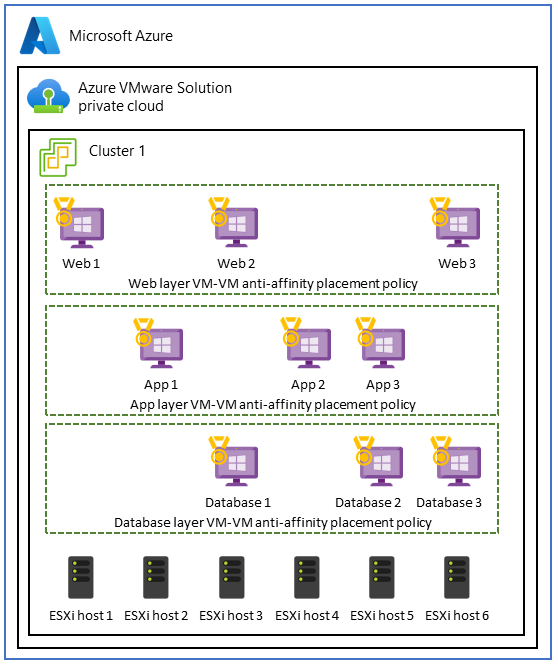
Use VM-VM anti-affinity policies in three-tier applications
In Azure VMware Solution, a use case for VM-VM anti-affinity policies involves a three-tier application. The goal is to enhance each application tier's high availability, fault tolerance, and resiliency. To achieve this goal, you can use anti-affinity policies to spread the tiers across different hosts within the Azure VMware Solution private cloud.
To implement this use case, create a distributed, fault-tolerant architecture by using VM-VM anti-affinity policies across three tiers. This setup improves the availability of the entire application and helps ensure that the failure of a single host doesn't disrupt the entire tier or the entire application.
For example, in the front-end web tier that serves user requests, you can apply VM-VM anti-affinity policies to spread the web servers across different physical hosts. This approach helps improve high availability and fault tolerance. Similarly, you can use anti-affinity measures to help safeguard the application servers in the business layer and to bolster data resiliency within the database layer.
Recommendations
- Create maps that show VM interdependencies, communication, and usage patterns to ensure that proximity is a requirement.
- Determine whether placement policy VM-VM affinity helps meet performance metrics or service-level agreements (SLAs).
- Design for high availability by implementing placement VM-VM anti-affinity policies to protect against host failures and distribute your application across multiple hosts.
- To avoid overprovisioning, distribute your workload across small VMs rather than a few large VMs.
- Regularly monitor, review, and fine-tune affinity policies to identify potential resource contention. Adapt these policies over time as needed.
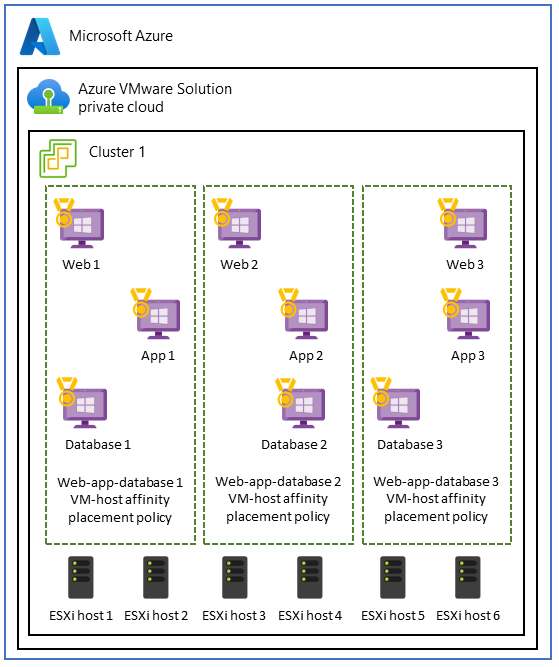
Use VM-host affinity policies for performance isolation
Some workloads that run VMs in different application tiers perform better when they're colocated. This use case often occurs when applications require:
- Performance isolation for resource-intensive, high-performance compute workloads.
- Compliance with licensing agreements. For instance, system specifications might require a mapping that associates a VM with a specific set of cores to maintain compliance with Windows or SQL Server licensing.
- Regulatory compliance and data integrity to ensure that VMs that belong to specific security domains or data classifications are confined to specific hosts or a subset of hosts within the cluster.
- A simplified network configuration that places VMs on the same host. In this case, the network configuration between tiers is simplified. The tiers share the same network connectivity and don't require extra network hops.
If it's essential to maintain the colocation of application tiers, you can opt for VM-host affinity policies to ensure that the tiers are deployed on the same host and within the same availability zone.
Note
The platform team is responsible for setting up VM placement, host affinity rules, and resource pooling. But the application team should understand each application's performance requirements to make sure that application needs are met.
Application teams must comprehensively evaluate VM placement and engage in meticulous planning. VM placement can present potential challenges like resource imbalances and uneven workload distribution. These situations can lead to adverse effects on performance and resource optimization. Also, placing all workloads in one availability zone can create a single point of failure in a disaster. Consider replicating your configuration across multiple availability zones to enhance datacenter resilience during a failure.
Recommendations
- Carefully plan how you use placement policy VM-host affinity policies. Consider alternative solutions when possible, such as load balancing, resource pools in VMware vSphere, distributed databases, containerization, and availability zones.
- Regularly monitor resource utilization and performance to identify any imbalances or issues.
- Opt for a VM placement strategy that's balanced and flexible. This approach helps you maximize resource utilization while maintaining high availability and ensuring compliance with licensing requirements.
- Test and validate your placement policy VM-host affinity configurations to ensure that they align with your application's specific requirements and that they don't negatively impact overall performance and resilience.
Distribute traffic by using an application or network load balancer
Besides the use of placement policies, load balancing is also a critical component of modern applications for helping to ensure:
- Efficient resource distribution.
- Increased application availability.
- Optimal application performance.
Load balancing meets these criteria while maintaining flexibility for workload scaling and management.
After you deploy applications on VMs, consider using a load balancing tool such as Azure Application Gateway to create back-end pools. Application Gateway is a managed web traffic load balancer and application delivery service that can manage and optimize incoming HTTP and HTTPS traffic to web applications. As an entry point for web traffic, Application Gateway offers various types of functionality. Examples include TLS/SSL termination, URL-based routing, session affinity, and web application firewall capabilities.
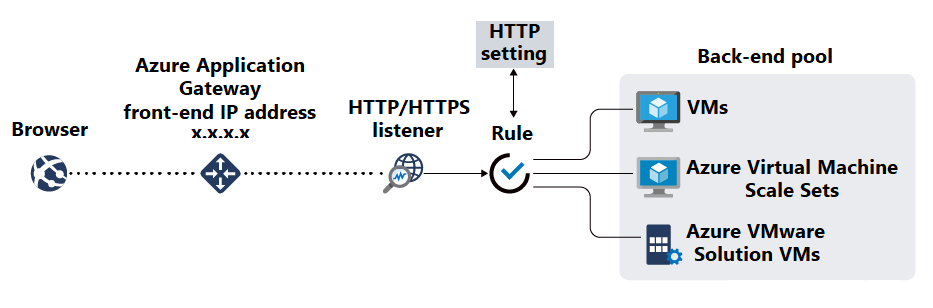
After the resources in your back-end pools are available, create listeners to specify ports and routing rules for incoming requests. Then you can create health probes to monitor the health of your VMs and to indicate when to remove unhealthy back-end resources from rotation.
Implement TLS/SSL termination and certificate management
TLS/SSL encryption needs to be enforced for all communication between your application and users' browsers. This encryption helps protect session data from eavesdropping and man-in-the-middle attacks. If your application requires TLS/SSL termination, configure the necessary TLS/SSL certificate in Application Gateway to offload TLS/SSL processing from your back-end VMs.
After you generate TLS/SSL certificates, place them in a service like Azure Key Vault that helps you store and access them securely. Use PowerShell, the Azure CLI, or tools such as Azure Automation to update and renew certificates.
Manage APIs
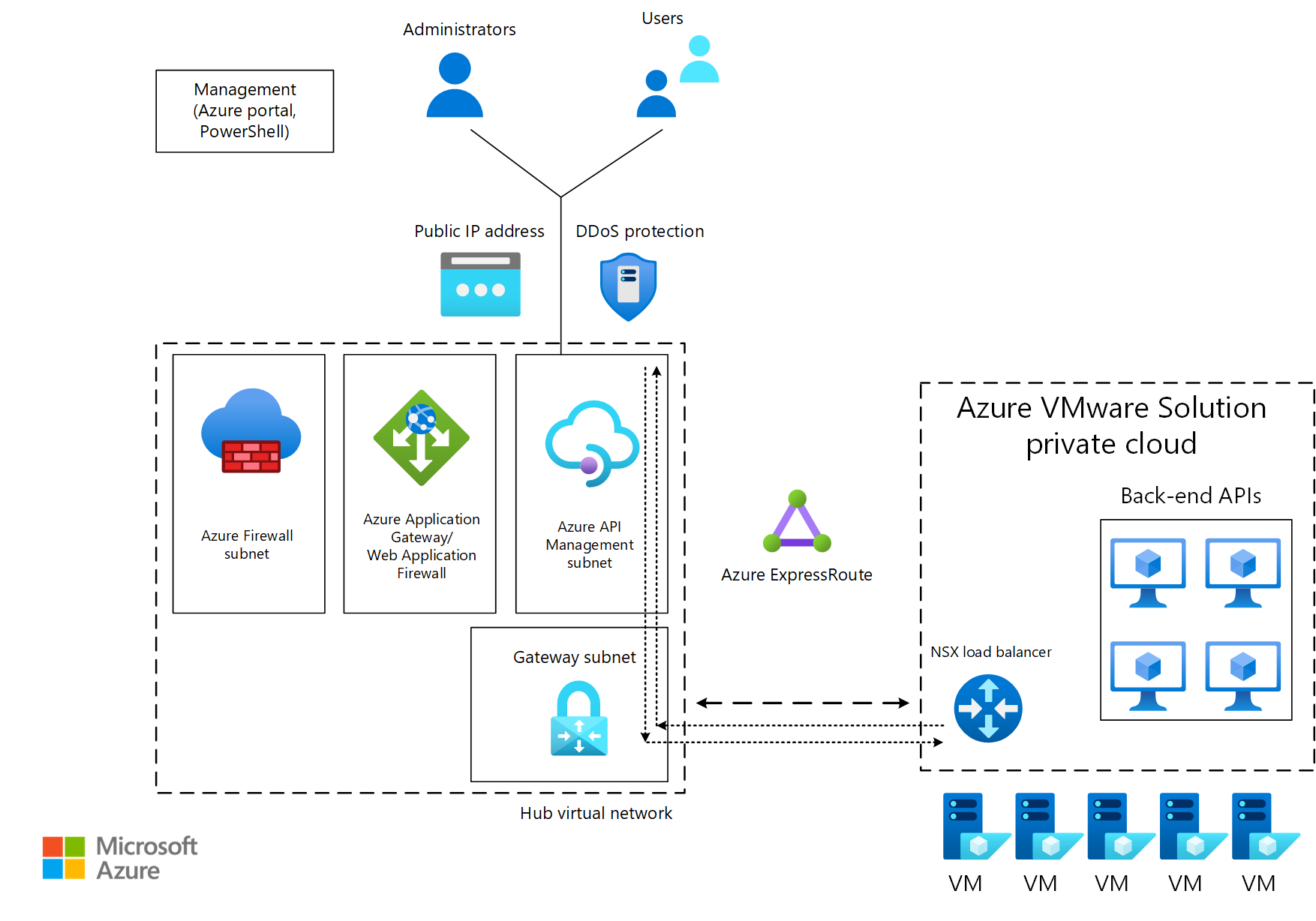
Azure API Management helps you securely publish internally and externally deployed API endpoints. An example of an endpoint is a back-end API that's in an Azure VMware Solution private cloud behind a load balancer or Application Gateway. API Management helps you manage the methods and behaviors of your API, such as by applying security policies to enforce authentication and authorization. API Management can also route API requests to your back-end services through Application Gateway.
In the following diagram, traffic from consumers travels to an API Management public endpoint. The traffic is then forwarded to back-end APIs that run on Azure VMware Solution.
Recommendations
- To enhance the security and performance of your Azure VMware Solution applications, use Application Gateway with Azure VMware Solution back ends to distribute traffic to your application endpoints.
- Ensure that there's connectivity between the back-end segments that host Azure VMware Solution and the subnet that contains Application Gateway or the load balancer.
- Configure health proves to monitor the health of your back-end instances.
- Offload TLS/SSL termination to Application Gateway to reduce processing overhead on the back-end VMs.
- Securely store TLS/SSL keys in vaults.
- Streamline processes by automating tasks such as certificate updates and renewals.
Optimize stretched clusters to strengthen business continuity and disaster recovery readiness
Impact: Reliability
Stretched clusters provide VMware clusters with high availability and disaster recovery capabilities across multiple geographically distributed datacenters.
The following setup supports active-active architectures. The virtual storage area network (vSAN) spans two datacenters. A third availability zone maps to a vSAN witness to serve as a quorum for split-brain scenarios.
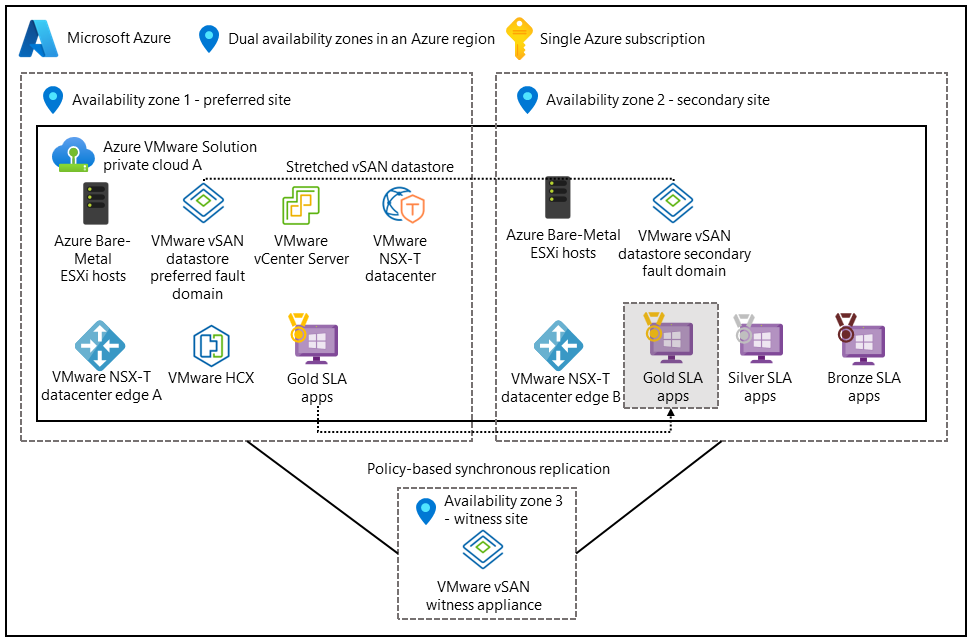
Distributing the application across multiple availability zones and regions helps to ensure continuous availability during datacenter failures. Deploy the application tiers and data tiers across both datacenters, and turn on synchronous replication.
Configure fault tolerance and failure to tolerate (FTT) policies
Your application's total usable capacity depends on several variables. Examples include your redundant array of independent disks (RAID) configuration, the value of your failures to tolerate attribute, and the failure to tolerate (FTT) policies that control the number of failures your storage system can tolerate. Application teams need to determine the level of redundancy that's needed for the application. It's also important to note that higher FTT values improve data resiliency but increase storage overhead.
Recommendations
- Deploy your application across shared storage so that the VM data remains consistent across the stretched cluster. Turn on synchronous replication.
- Configure fault domains to define how stretched clusters should respond in a failure scenario.
- Implement automatic failover and failback to minimize manual intervention during failover and recovery events.
Configure data synchronization and storage policies
Data synchronization methods are important when your application relies on stateful data and databases to ensure consistency and availability during a disaster. Data synchronization helps provide high availability and fault tolerance for critical VMs that run applications.
An application owner can define a storage policy to help ensure that:
- Critical VMs that run an application receive the required level of data redundancy and performance.
- The VMs are positioned to take advantage of the high availability capabilities of the stretched cluster in Azure VMware Solution.
Example policies can involve the following factors:
- The vSAN configuration. Use a VMware vSAN with a stretched cluster across availability zones.
- The number of failures to tolerate. Set the policy to tolerate at least one or more failures. For example, use a RAID-1 layout.
- Performance. Configure performance-related settings to optimize IOPS and latency for critical VMs.
- Affinity rules. Set up affinity rules to help ensure VMs or groups of VMs are placed in separate hosts or fault domains within the stretched cluster to maximize availability during datacenter failures.
- Backup and replication. Specify integration with backup and replication solutions to ensure that VM data is regularly backed up and replicated to a secondary location for extra data protection.
Recommendations
- Define data storage policies in the vSAN to specify the redundancy and performance that's required for various VM disks.
- Configure applications to run in an active-active or active-passive configuration so that critical application components can fail during datacenter failures.
- Understand each application's network requirements. Applications that run across availability zones can incur higher latency than applications with traffic within an availability zone. Design your application to tolerate this latency.
- Run performance tests on your placement policies to evaluate their impact on your application.
Next steps
Now that you've examined the application platform, see how to establish connectivity, create perimeters for your workload, and evenly distribute traffic to your application workloads.
Use the assessment tool to evaluate your design choices.