Health modeling for workloads
Cloud applications generate high volumes of operational data, which makes it challenging to pinpoint and resolve problems quickly. A common reason for this challenge is the absence of a health baseline that's customized to the workload's functionality and the inability to detect drift from that baseline.
Health modeling is an observability exercise that combines business context with raw monitoring data to quantify the overall health of a workload. It helps set a baseline that you can monitor the workload against. You should consider data like telemetry from infrastructure and application components. Health modeling might also incorporate other information that's necessary to achieve the workload's quality targets.
Performance problems or operational degradation can cause drift from the expected operational state. By modeling the health of a workload, you can identify drift and make informed operational decisions that consider business impact.
Health modeling bridges the gap between tribal operational knowledge and actionable insights. It helps you manage critical issues effectively. The concept is essential to maximize reliability and operational effectiveness.
This guide offers practical guidance about health modeling, including how to build a model that assesses the runtime health of a workload and all of its subsystems.
| Terminology | Definition |
|---|---|
| Health modeling | An observability exercise that uses business context to interpret monitoring data as health states. |
| Health model | A graphical representation of logical entities and their relationships for a given scope. Each node has a health state definition to rationalize monitoring data across the model. |
| Health entity | A logical component that represents an individual unit of a system, a logical combination of multiple related entities, or the overall system. |
| Health state | A defined and measurable status that provides meaningful operational insights about the health of an entity. |
| Health signal | Individual data streams that provide insights into the operational behavior of an entity. |
| Model of models | An aggregated modeling scope in which entities represent distinct health models for component systems. |
We recommend that you watch this video to get a high-level understanding of health modeling.
What is health, health modeling, and a health model?
The term health refers to the operational status of an entity and its dependencies. That entity can be an individual unit of a system, a logical combination of multiple related entities, or the overall system.
We recommend that you represent health in one of three states:
Healthy: Operates optimally and meets quality expectations
Degraded: Exhibits less than healthy behavior, which indicates potential problems
Unhealthy: In a critical state and requires immediate attention
Note
You can represent health with a score instead of states to provide more data granularity.
Health states are derived by combining monitoring data with domain information. Each state must be defined and must be measurable. Health states are calculated by using health signals, which are individual data streams that provide insights into an entity's operational behavior. Signals can include metrics, logs, traces, or other quality characteristics. For example, a health signal for a virtual machine (VM) entity might track the CPU utilization metric. Other signals for this entity can include memory usage, network latency, or error rates.
As you define health signals, factor in the nonfunctional requirements for the workload. In the example of CPU utilization, include the expected thresholds for each health state. If utilization exceeds the tolerated threshold in accordance with the workload requirements, the system transitions from Healthy to Degraded or Unhealthy. These state changes trigger the appropriate alerts or actions.
Health modeling requires entities to have well-defined states that are derived from multiple health signals and are contextualized for the workload. For example, the health definition for a VM might be:
Healthy: Key nonfunctional requirements and targets, such as response time, resource utilization, and overall system performance, are fully satisfied. For example, 95% of requests are processed within 500 milliseconds. The workload uses VM resources like CPU, memory, and storage optimally and maintains a balance between workload demands and available capacity. User experience is at expected levels.
Degraded: Resources aren't performing optimally but are still operational. For example, the storage disk is experiencing throttling problems. Users might experience slow responses.
Unhealthy: Degradation is beyond the tolerated limits. Resources are no longer responsive or available, and the system is no longer meeting acceptable performance levels. User experience is severely affected.
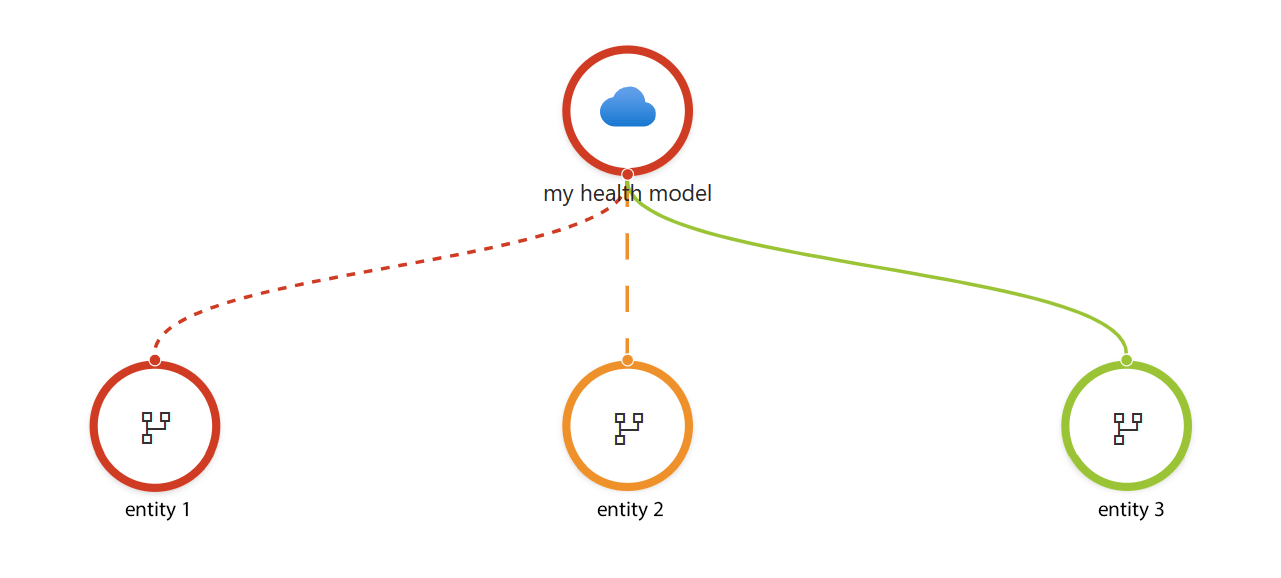
The outcome of health modeling is a model or a graphical representation of logical entities and their relationships for a workload architecture. Each node has a health state definition.
Important
Health modeling is an abstract concept that you can implement and apply at different scopes if you have a good understanding of the business scenarios.

In the image:
Entities are logical components of the workload that represent aspects of the system. They can be infrastructure components, like servers, databases, and networks. They can also be specific application modules, pods, services, or microservices. Or, entities can capture user interactions and system flows within the workload.
Note
User and system flows summarize nonfunctional requirements across business scenarios that involve application and infrastructure components. This summary reflects business value for the application.
Relationships between entities mirror the dependency chains within the system. For example, an application module might call specific infrastructure components that form a relationship.
Consider a scenario in which an e-commerce workload experiences a spike in failed messages on an Azure Service Bus queue, which is causing payments to fail. This problem is critical for the organization due to the implied revenue loss. Although an application developer might understand the effect of this metric spike on payments, this tribal knowledge isn't often shared across the operations team.
A health model can give operators immediate visibility into the problem and its effects. The payment flow depends on Service Bus, which is one of the workload components. The visual representation reveals the degraded state of the Service Bus instance and its effect on the payment flow. Operators can understand the importance of the issue and focus their remediation efforts on that specific component.
Health modeling was important in the preceding scenario in the following ways:
It improved the time to detect (TTD) and time to mitigate (TTM) by enabling faster problem isolation, which led to quicker detection of problems and potential fixes.
Operators received alerts based on health states, which reduced unnecessary noise. Operators received notifications that provided specific context about the business impact on payments.
Dependency chains helped operators fully understand the extent of operational issues. This knowledge accelerated impact assessments and led to prioritized responses. Operators also easily identified cascading or correlated issues.
Operators conducted post-incident activities with accuracy because the health model provided insights into the root causes of anomalies and the specific health signals that were involved.
It made the monitoring data meaningful for all team members. It bridged the gap between tribal knowledge and shared insights.
The organization used the health model as a baseline for future investments in AI-driven operations to derive intelligent insights.
Health model schema
Health models provide a distinct data schema optimized for observability use cases. This schema takes health modeling from an abstract concept to a measurable solution. By modeling your specific requirements, objectives, and architectural context, you can tailor health data to your unique scenario.

Health is a relative data concept. Each model represents health data that's unique and prioritized for its contextual scope, even if it uses the same set of entities. What constitutes healthy in a specific scenario might differ significantly in other contexts.
For example, consider Azure resources of the same type within your workload.
- VM A runs a CPU-sensitive application.
- VM B handles a memory-intensive service.
The health definitions for these machines are different. CPU utilization metrics likely influence VM A's health status, and VM B might prioritize memory-related metrics.
Important
A health model shouldn't treat all failures the same. It should clearly distinguish between expected or transient but recoverable failures and a true disaster state.
Build a health model
The first step to build a health model is a logical design exercise, which typically involves the activities that are described in the following sections.

Evaluate your workload design
Begin this logical design exercise by evaluating the following components of your workload design.
Infrastructure components like compute clusters and databases
Application components that run on compute and their relevant components
Logical or physical dependencies between components
For example, the health model for an e-commerce application should represent the current state of critical processes like user sign-in, checkout, and payments.
Contextualize using business requirements
Evaluate the relative importance and overall impact of each flow on your organization. Consider factors like user experience, security, and operational efficiency. For example, in most scenarios, the failure of a payment process is likely more significant than the failure of a reporting process.
Identify escalation paths for handling problems related to each flow. For more information, see Optimize workload design using flows.
Note
You realize the value of health modeling only when you incorporate your business scenarios and context. Then you can rationalize the business impact from operational issues.
Map to reliability metrics
Look for relevant reliability metrics across the application design.
Consider defining service-level indicators (SLIs) and service-level objectives (SLOs) for the entire application and its individual business processes. These SLIs and SLOs should align with the specific health signals considered for your health model. By doing so, you create a comprehensive definition of health that accurately reflects the achievement of an acceptable service level for the application.
Important
SLIs and SLOs are critical health signals. They create a meaningful definition of health that reflects the level of service that you want along with other quality attributes. You can also define service health objectives (SHOs) to capture the health that you want to attain over an aggregated time range.
Identify health signals
To build a comprehensive health model, correlate various types of monitoring data, including metrics, logs, and traces. By doing so, you ensure that the concept of health accurately reflects the runtime state of a specific entity or the entire workload.
Use platform metrics and logs
In the context of health modeling, it's essential to gather platform-level metrics and logs from underlying Azure resources. These metrics include CPU percentage, network in and network out, and disk operations per second. You can use this data in your health model to detect and predict potential problems while maintaining a reliable environment.
Furthermore, this approach helps you differentiate between transient faults, or temporary disruptions, and nontransient faults, or persistent problems.
Note
As a best practice, you should configure all application resources to direct diagnostic logs and metrics to the chosen log aggregation technology. Build guardrails by using Azure Policy to ensure consistent diagnostic settings across the application and enforce the chosen configuration for each Azure service.
Add application logs
Application logs are an important source of diagnostics data for your health model. Here are some best practices for application logging:
Use semantic or structured logging. Structured logs facilitate automated consumption and analysis of log data at scale.
Consider storing Azure resource metrics and diagnostics data in an Azure Monitor Logs workspace instead of a storage account. By using this method, you can create health signals by using Kusto queries for efficient evaluation.
Log data in the production environment. Capture comprehensive data while the application operates in the production environment. Sufficient information is essential for health assessment and to diagnose any detected production problems.
Log events at service boundaries. Include a correlation ID that traverses service boundaries. If a transaction involves multiple services and one of them fails, the correlation ID helps you track requests throughout your application and pinpoint the cause of failure.
Use asynchronous logging. Avoid synchronous logging operations that might block application code. Asynchronous logging ensures availability by preventing request backlogs during log writes.
Separate application logging from auditing. Maintain audit logs separately from diagnostic logs. Although audit records serve compliance or regulatory requirements, keeping them distinct prevents dropped transactions.
Implement distributed tracing
Implement distributed tracing by correlating telemetry across critical system flows. Correlated telemetry provides insights into end-to-end transactions and is essential for effective root cause analysis (RCA) when failures occur.
Use health probes
Implement and run health probes outside of the application to explicitly check the health and responsiveness of your application. Use probe responses as signals within your health model.
You can implement health probes by measuring the response time from the application as a whole or from its individual components. Probes can run processes to measure latency and check availability or to extract information from the application. For more information, see Health Endpoint Monitoring pattern.
Most load balancers support running health probes that ping application endpoints at configured intervals. Alternatively, you can use an external watchdog service. A watchdog service aggregates health checks from across multiple components in the workload. Watchdogs can also host code that does immediate remediation for known health conditions.
Adopt structural and functional monitoring techniques
Structural monitoring involves equipping the application with semantic logs and metrics. The application directly collects these metrics, which include current memory consumption, request latency, and other relevant application-level data.
Strengthen your monitoring processes by using functional monitoring. This approach focuses on measuring platform services and their effect on the overall user experience. Unlike structural monitoring, functional monitoring doesn't require detailed knowledge of the system. It tests the externally visible behavior of the application. This approach is useful for assessing SLOs and SLIs.
Model the design
Represent the identified application design as entities and relationships. Map health signals to specific components to quantify health states at an entity level. Consider the criticality of components to determine how health states should propagate through the model. For example, reporting components might not be as critical as other components, which results in different effects on overall workload health.
Set actionable alerts
Use the evaluated health states to trigger alerts and automated action. Health should be integrated within existing operational runbooks as a core observability data tenet.
Typically, there's a one-to-one mapping between monitoring data and alert rules, which can lead to undesirable outcomes, like alert storms and ambient alert noise. For example, in a compute cluster, high volumes of VM-level alerts based on CPU utilization and error count can overwhelm operators during failures and cause delays in resolution. Similarly, when there's a high number of configured alerts, ambient alert noise often results in alerts that are overlooked or ignored.
A health model introduces separation between monitoring data and alert rules. A health definition aggregates many signals into a single health state, which decreases the number of alerts so that operators can focus solely on high-value alerts that are critical for the organization. Consider the e-commerce scenario. You can set up an alert to send notifications about changes in the process payments flow health instead of changes in underlying resources like the Service Bus queue.
Note
The ability to alert across all layers of the health model provides flexibility for the different workload personas. Application owners and product managers can be alerted to health state changes in key business scenarios or in the entire workload. Operators can be alerted based on the health of infrastructure or application components.
Visualize the model
Create visual representations, such as tables or graphs, to effectively convey the current state and history of the health model. Ensure that the visualization aligns with the business context and provides actionable insights.
When you visualize your health model, consider adopting a traffic light approach to make health states immediately insightful across dependency chains.
Assign green for healthy, amber for degraded, and red for unhealthy. By quickly identifying the color-coded states, you can efficiently locate the root cause of any application degradation.
Note
We recommend that you consider accessibility requirements for people who have a vision disability when you create a dashboard for your health model. For diagramming best practices, see Architecture design diagrams.
Adopt your health model
After you build a health model, consider the following use cases to drive detection and interpretation of failures or operational problems.
Applicability to various roles
Health modeling can provide information that's specific to job functions or to roles within the same context of the workload. For example, a DevOps role might need operational health information. A security officer might be more concerned about intrusion signals and security exposure. A database administrator is likely only interested in a subset of the application model through the database resources.
Tailor health insights for different stakeholders. Consider creating separate models from overlapping data sets.
Continuous validation
Use your health model to optimize testing and validation processes, such as load testing and chaos testing. You can validate the runtime operational state during testing and assess your model's effectiveness in scale and failure scenarios by incorporating health models into your engineering lifecycle.
Organizational health
Although health modeling is commonly associated with quantifying health states for individual applications, its applicability extends beyond that scope.
At an individual workload level, health models provide a foundation for application observability and operational insights. Each application can have its own health model that captures what each health state means within its context.
You can combine multiple health models into a high-level construct by building a model of models. For example, you can build the observability footprint of a business unit or an entire cloud estate by using health models as components within a larger model. Health models represent workloads within the estate as nodes within the top-level graph. Use the relationships in this model to capture inter-application dependencies, including data flows, service interactions, and shared infrastructure.
Consider a retail company that has various applications for e-commerce, payments, and order processing. You can define each of these applications as an independent health model to quantify what health means for that workload. You can then use a parent model to map all of these component health models as entities and capture inter-application operational impact through dependency chains. For example, if the e-commerce application becomes unhealthy, it has a cascading effect on the payment application.
Health trends and AI for IT operations
Health modeling provides a quantified operational baseline that's tuned to a specific business context. AI for IT operations (AIOps) is a popular way to enhance operational efficiency. Health data is a foundational input for machine learning models to analyze health trends. For example, machine learning models can:
Extract more insights from state changes and recommend actions.
Analyze health trends over time to drive issue prediction and model refinement.
Maintain your health model
Maintaining a heath model is a continuous engineering activity that aligns with your application's development and operations. As your application evolves, make sure that your health model evolves in parallel.
Also, treat health models like workload artifacts that should be integrated into your development lifecycle. Adopt infrastructure as code (IaC) for consistent, version-controlled management of your health model. Use automation so that the model stays up to date as you add or remove infrastructure and application components from the workload.
Health data gradually diminishes in value over time. To optimize operational efficiency and minimize costs, avoid retaining health data beyond 30 days. If necessary, you can archive data to satisfy audit requirements or in scenarios that involve long-term pattern analysis in AI for IT operations.
Note
When you archive health data, make sure you couple it with the configuration state of the model. Interpreting state changes can be challenging without this context.
Related links
- For implementing health probes in ASP.NET, see Health checks in ASP.NET Core.
- For information on monitoring metrics, see Azure Monitor Metrics overview.
- For information on using Application Insights, see Application Insights.
- For design considerations and recommendations that pertain to mission-critical workloads, see Health modeling and observability for mission-critical workloads on Azure.
- For a hands-on experience, see Design a health model for your mission critical workload.