Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Throttling is a design pattern that controls how much load your system can accept at a given time. In distributed systems, traffic spikes, retry storms, fan-out patterns, and shared downstream dependencies all create conditions where uncontrolled demand eventually exhausts capacity. When a component reaches capacity, the throttling mechanism helps reject or delay additional requests until the system is ready again. Otherwise, latency can increase, retries amplify load, and failures can spread through the system.
A common architectural approach is to apply throttling only at the gateway to protect ingress. An isolated throttling mechanism may protect one component while shifting overload to other parts of your application, increasing latency and degrading user experience.
In well-architected design, apply the pattern across the system rather than only at the edge. Consider where your service shares capacity across multiple callers, exposes resources that can be exhausted, or participates in a call chain where overload in one component can cascade to others. All those points are potentially good candidates for throttling. Effective throttling requires coordinated response across architecture components. You should treat overload as a normal operating condition: expect it, monitor it, and actively control how your system responds when capacity limits are reached.
Throttling buys time for reactive responses during events like scaling operations, on-call investigation, circuit breakers. Static limits calibrated last quarter may no longer reflect today's traffic patterns.

The intent of this article is to guide you through throttling best practices. It assumes that you understand the Throttling pattern.
Start with the throttling tenets, because every workload follows certain fundamental approaches. The tenets are presented in tabs, and you should review all of them before you tune limits in your design.
After you understand the tenets, evaluate where you are in your adoption journey by reviewing the Adoption phases. Use the lower levels to implement baseline implementation and optimize as your workload matures over time.
Remainder of the guide is a reference of throttling practices codified as TPs. Each TP is a discrete guidance unit and appears in numeric order.
Types of throttling
Each throttling type protects a different part of your architecture. Place each one at the boundary where it can directly control load.
The table maps the types to the architectural layers used in the practices below.
| Type | What it controls | Where it lives | Relevant practices |
|---|---|---|---|
| Ingress throttling | Request rate and volume entering your system | API gateway, public and private entry points | TP-1, TP-2 |
| Internal throttling | Traffic between your sub-components like databases, caches, queues, and shared services | Service-to-service calls inside your boundary | TP-6 |
| Egress throttling | Traffic your system sends to downstream dependencies | Client SDKs, fan-out points, outbound call paths | TP-7 |
| State-aware throttling | Limits that adjust based on real-time system health, operation cost, or queue depth | Throttle policy engine, admission control layer | TP-12, TP-13, TP-14 |
Risk: Throttling depends on cooperation between the server and its clients. To be effective, the server must enforce clear, predictable throttling policies and communicate them consistently. Clients, in turn, must understand and respect those limits by implementing appropriate retry, backoff, and rate-control mechanisms. Mitigate this risk by having well-defined contracts that reward good behavior and discourage abuse or excessive consumption.
Most workloads need all four types working together. If you only throttle ingress, you protect the front door but push overload deeper into your application. Internal and egress controls stop that spread. State-aware throttling lets your system adjust as conditions change instead of running with stale fixed limits.
Throttling tenets
No matter which throttling types your workload uses, you still need the same core fundamentals. If you're new to throttling, read these tenets in order so you understand why each practice exists before you implement how. If you're reviewing an existing design, use the design questions under each principle as a checklist to find gaps.
| Terminology | Description |
|---|---|
| Boundary | Boundary is the component group your throttling protects, usually represented by an entry point. |
| Dimension | Dimension is a name/value pair from request metadata that a throttling rule evaluates. |
| Upstream | Upstream is the caller that sends requests to your service. |
| Downstream | Downstream is the dependency your service calls. |
 Design for overload as a normal operating mode
Design for overload as a normal operating mode
In distributed systems, overload is expected, not exceptional. Throttling is the control loop that protects shared dependencies and preserves your SLOs under load. Design your system assuming traffic surges, retries, and cascading effects will happen.
Design considerations
Use these when reviewing an existing design or assessing where your system is exposed to overload risk.
- What saturates this system and impacts SLOs: requests, concurrency, CPU, I/O, queue depth, or downstream quotas?
- Where does load enter, amplify (fan-out), or cascade?
- For each entry point, what are the explicit boundaries of impact (gateway, shard, dependency)?
- What is the appropriate overload signaling mechanism between components?
- When (not if) overload happens, how will the system heal and recover?
Design recommendations
- Define throttling boundaries (where throttling occurs) and throttling dimensions (what limits are enforced) at design time, and ensure they align with saturation vectors.
- Enforce limits at every entry point, including low-priority and read-only APIs.
- Control concurrency at fan-out points.
- Ensure components in this system are ready to respect protocol-specific overload signals.
- Treat throttling as a lifecycle: measure → enforce → learn → adapt.
Caution
Throttling is not a substitute for DoS/DDoS protection. Continue investing in mechanisms to detect, mitigate, and block malicious traffic designed to overwhelm the system.
Relevant best practices
Adoption phases
| Maturity Level | Best Practices | Benefit |
|---|---|---|
| 1 | TP-1: Customize protections are your gateway TP-2: Implement Frontend throttling TP-3: Create Backpressure TP-4: Operational excellence (Part 1) |
Protect the service that you own; have operational response |
| 2 | TP-5: Respect backpressure TP-6: Internal controls TP-7: Egress bulkhead |
Protect a downstream dependency and your service |
| 3 | TP-8: Cache does not replace a throttle. TP-9: Keep Throttling out of critical path. TP-10: Protect Horizontal Infrastructure TP-11: Operational Excellence (Part 2) |
Your service avoids problematic architectural patterns; You have operational posture and discipline to withstand failures |
| 4 | TP-12: State-aware throttling TP-13: Honor transactional boundaries TP-14: Continuous validation via Random Early Drop |
Your service has granular control on QoS; Client and service auto-validate response readiness |
Important
In AI workloads, the primary saturation vector shifts from request rate to token throughput. Capacity becomes proportional to prompt and response size rather than request count. The Azure OpenAI tabs throughout this section apply the tenets above through that lens.
[TP-1] Customize protections at your gateway
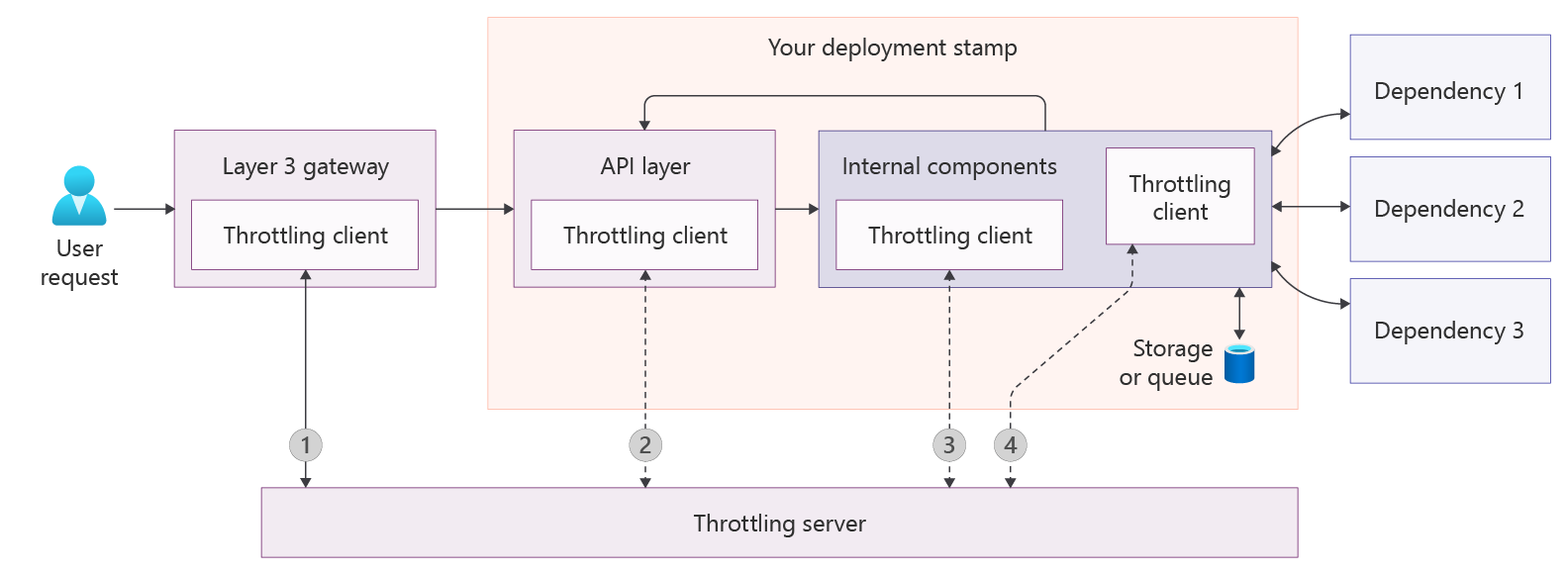
Start load control at the first Layer 3 gateway component you control (see item 1 in image showing throttling points in a system). Your gateway capabilities and position in the request path determine how sophisticated these controls can be. Even simple checks, such as source IP or DNS-based filtering, can protect backend services during traffic surges.
Gateways are also a good place for coarse-grained load blocking during unexpected traffic spikes. Blocking at this layer can reduce the number of backend systems destabilized during an event and help your system recover faster.
Keep gateway checks simple and inexpensive. Sophisticated controls at this point slow all requests. Choose gateway products that balance response speed with policy complexity. Also remember that these Layer 3 controls are coarse-grained. When they trigger, the blast radius is often wider than expected. Continue to TP-2 to implement more comprehensive controls.
[TP-2] Implement throttling at multiple points
Implement throttling at all points where Layer 7 load enters your system (see item 2 in image showing throttling points in a system), including private entry points used by internal services. This design ensures callers can't bypass system limits. As noted in TP-1, gateway throttling alone is usually not sufficient.
Design your limits
After you identify the entry points, design your limits to achieve the following goals:
- Protect users or workloads from each other (also known as noisy neighbors). These limits are User Limits.
- Protect the service and its infrastructure from all users. These limits are Service Limits.
For each API, define at least one user limit and one service limit. Ideally, user limits trigger before service limits when an individual caller sends too much traffic. However, service limits can trigger even when no single user limit is breached. This situation can happen during temporary events such as zone outages, when traffic shifts and overloads the remaining partitions.
The mental model is that each request carries a set of dimensions (region = X, identity = Y, and so on), and throttling policies define a series of admission gates (logical AND) across those dimensions.
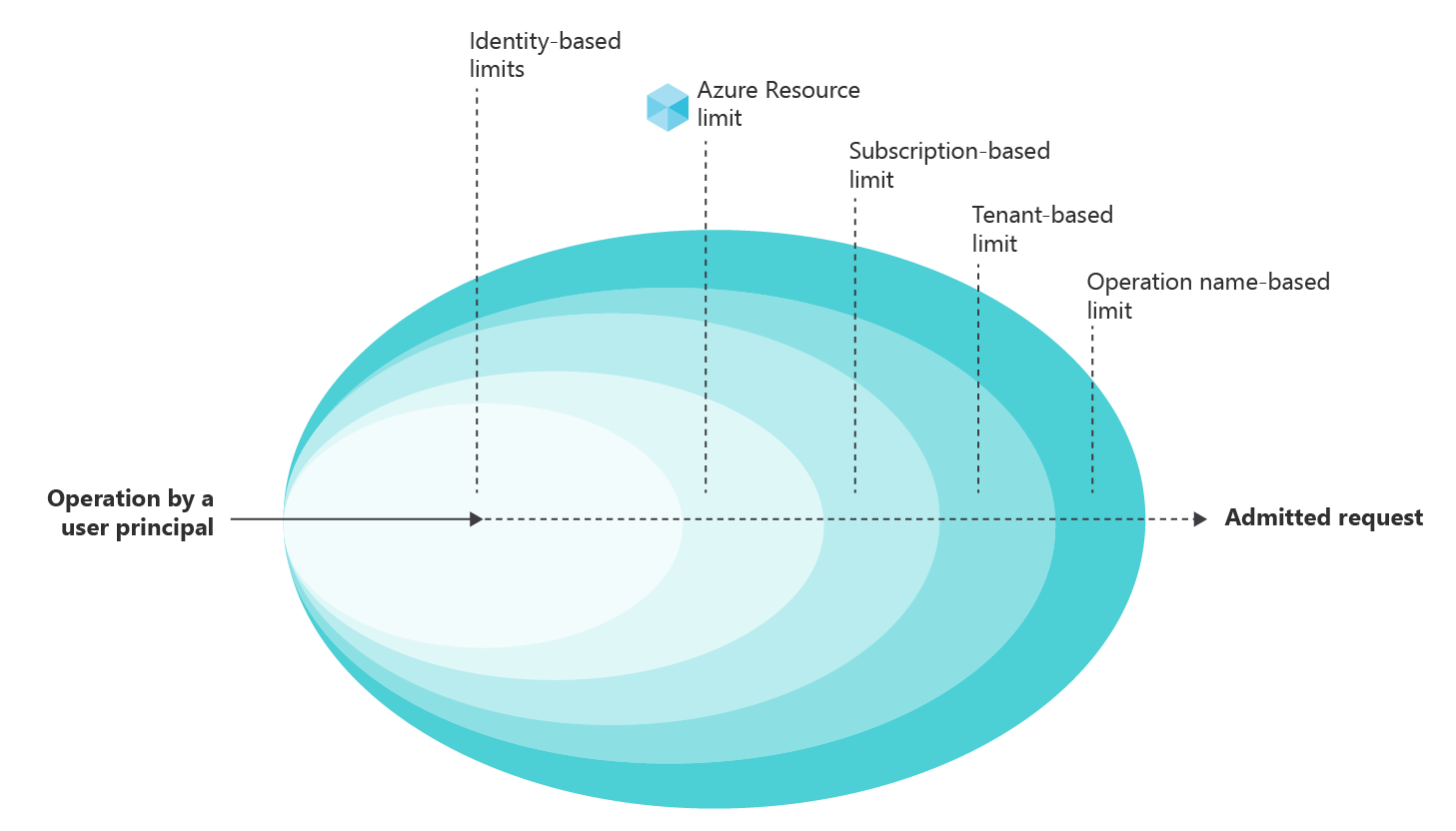
The following table shows a sample hierarchy of common request dimensions:
| Limit dimension | Type | Protects | Comment |
|---|---|---|---|
| Workload Identity | User | Noisy or overactive workloads from one another | Strongly recommended |
| Server-side Resource ID | User | A cohesive set of workloads that need the same resources, protected from each other | Usually results in desirable behavior. Resource groups can work well here. |
| Subscription | User | A bigger set of workloads from each other | Usually results in desirable behavior. |
| Tenant | User | A misbehaving set of users of your service from other users | Usually results in desirable behavior. |
| Operation Name | Service | An API that is under load from taking down other APIs of your service | Strongly recommended |
| Service/Global | Service | Your infrastructure from terminal overload | Not recommended. This type of limit has a very large blast radius and can cause unnecessary outages when they get stale. Use Operation Name based limits instead. |
| Service Node | Service | Protects the node from being overwhelmed | Not recommended. While very effective with uniform traffic distribution, these limits can create a perception of randomness when node-level traffic is "lumpy" or the node population is heterogeneous. Use Operation Name based limits instead. |
Tradeoff: Targeted throttling improves fairness and overall user experience by limiting only the users who exceed their agreed-upon usage contracts, rather than degrading service for the entire user population. However, this approach introduces additional complexity, requiring clear contract definitions, per-user usage tracking, and the ongoing management and enforcement of differentiated rate limits across users.
Architectural constructs that are internal to the service (that is, not visible to users, such as partitions or shards) aren't good dimensions for user limits. Because users can't predict or control these constructs, they have no sensible way to respond. Also, error messages can reveal internal structural details and create security concerns, so proceed carefully. Service limits on these constructs can still be valuable, but when those limits are exceeded, communicate the condition as HTTP 503 (Service Unavailable), or an equivalent, with clear retry semantics. For more discussion, see TP-3.
Blocking Traffic
Implement the ability to block specific users or API operations without requiring service deployments or restarts. For specific requirements, see TP-4.
Apply the limit hierarchy in the table above. Workload Identity and Operation Name are the minimum recommended dimensions.
[TP-3] Create backpressure
When a user or service limit is breached, the condition is typically temporary. Signal this condition to upstream callers by returning HTTP 429 (Too Many Requests) or HTTP 503 (Service Unavailable) so they can respond intelligently. Use 429 for user limits and 503 for service limits.
Note
Use HTTP 429 for user-limit enforcement and HTTP 503 for service-level constraints. Include retry guidance only when retry is safe and intended.
Without this signal, callers might retry immediately, increasing traffic and causing more throttling and failures. They might return HTTP 500 to their own callers or move long-running operations into a DLQ. These outcomes create unpredictable user experience and increase live site calls.
Signaling via 429
When a user limit is exceeded, signal upstream callers to slow down by returning HTTP 429. This code indicates that the caller exceeded its contract with your service.
At a minimum, include the following header with a 429 response:
| Header | Data Type | Discussion |
|---|---|---|
Retry-After |
Integer; time in seconds | The caller should wait at least this many seconds. Although RFC 9110 allows a timestamp in HTTP-date format, return a duration instead of a timestamp. In ISO 8601 terms, this duration can be thought of as PTnS. For n = 0, the client can retry immediately.Sub-second durations aren't supported because they don't have wide applicability in the kinds of systems discussed in this document. If you have a use case, contact the authors. |
In addition to the header above, return the following headers:
| Header | Data Type | Discussion |
|---|---|---|
RateLimit-Policy |
String | The set of policies that apply to this request. Example: RateLimit-Policy: "default";q=100;w=10. This header indicates a throttling policy named default that allocates 100 requests over a 10-second window. See the IETF Rate Limit Headers draft for the full specification. |
RateLimit |
String | The remaining capacity units and when capacity is expected to be available next. Example: RateLimit: "default";r=0;t=30. This header indicates the default policy has 0 units remaining and the server expects more units to be available in 30 seconds. See the IETF Rate Limit Headers draft for the full specification. |
x-ms-ratelimit-used |
Number; Count | Capacity units that will be used by this call. Will be included in the RateLimit header (WIP) |
Your throttling solution should return these values to your application when a limit is breached. Using standardized headers ensures compatibility with industry-standard client middleware.
Signaling via 503
When a service limit is exceeded, indicate this condition to upstream callers by returning HTTP 503. This code indicates the service is temporarily constrained, unrelated to the behavior of the recipient.
With 503, you can optionally include the headers described earlier, only if you want callers to retry. If you're permanently rejecting traffic and don't want retries, don't include retry guidance headers. Unlike 429, 503 can also be returned for reasons other than service limit violations.
Computing Retry-After
To create effective backpressure, compute the Retry-After interval returned to clients. If your throttling solution doesn't provide a precomputed value, compute it as follows:
Retry-After = Now + Throttling Window Length(W) + Randomized Jitter
Jitter should be randomized in the interval (-W, +small multiple of W) to prevent repeated waves of calls. Traffic priority, timeout lengths, the retry-attempt header (see TP-5), and typical API call durations can also influence jitter. The goal is to predict when capacity is likely to be available to service the request. Avoid returning an absolute time in Retry-After so clock skew and time-zone parsing differences don't create additional failures.
See TP-12, TP-13, and TP-14 for further discussion of advanced cases.
Return 429 for user limit breaches with Retry-After so callers back off and retry intelligently.
[TP-4] Build operations to handle load events
Throttling implementations fail for many reasons. Until software reaches a higher level of maturity, DRIs must be able to mitigate throttling events quickly by using an "observe, decide, act" loop.
Observability and DRI tooling are the two pillars of this best practice. Success is measured by how quickly DRIs can act with minimal blast radius. Your team must have the following capabilities:
- Observe: Current throttling limits and their saturation.
- Decide: Identify top-N traffic for each API, aligned to existing limits.
- Act: Block traffic with the lowest collateral damage.
- Safety: DRIs act quickly and safely.
- Prepare and Train: Do you have training for DRIs? Does operational review include load management as an area of focus?
DRI tooling must show current limit saturation and the top-N callers per API so you can act with minimal blast radius.
[TP-5] Respect backpressure
Because 429 signals a temporary condition, respecting backpressure by reducing downstream traffic improves overall stability. Although this state is temporary, it can last for a long time (that is, multiple request lifetimes). As a result, effective backpressure handling requires careful planning.
First, decide whether to fail the request and let your upstream caller retry, or retry it yourself. If you choose to retry it yourself, evaluate whether retriable work should be enqueued (durably or in memory). Keeping a thread active for the duration of a retry isn't recommended because in-flight retries can cause head-of-line blocking, where retried requests hold up requests that could be processed immediately. This also makes declaring bankruptcy (that is, resetting the retry queue) harder, because it might require a service restart and delay recovery.
Next, perform retries in an orderly fashion. Don't retry until the period in the retry header has elapsed. On each retry, annotate the request with a retry-attempt header that indicates how many times the request has been retried. Keep retry count low and pre-negotiated with your dependencies. Servers are free to return 425 (Too Early) and can escalate to 403 (Forbidden) if those expectations are violated. If a 429 response doesn't include retry headers, use exponential backoff; bounded retries for 429 are acceptable. But do not retry a 503 unless it includes retry headers.
Finally, use the circuit breaker pattern to fail fast. Don't send traffic to a dependency that already signaled ongoing throttling. When that dependency recovers, avoid draining enqueued work all at once, because it can create a sudden inrush of downstream traffic. Gradually reintroduce traffic so downstream systems can ramp up. During reintroduction, continue using the retry-attempt header as noted above. If the maximum retry count is reached, reject the request by sending an HTTP 503 upstream with appropriate headers and metadata. Ensure the libraries and SDKs you use to call dependencies support these mechanisms.
Respect the Retry-After header, enqueue rather than block threads for retries, and use circuit breakers to fail fast during sustained throttle windows.
[TP-6] Protect internal components
While entry-point throttling provides admission control, throttling traffic between subcomponents such as databases, caches, and queues is also essential (see item 3 in image showing throttling points in a system).
Throttling in this layer allows each subcomponent to protect itself. Assume breach from other subcomponents, and make no assumptions about their behavior under load. This approach creates logical "cells" inside the system that are relatively isolated from one another and protected from bugs in other components. In particular, focus on components that are shared across different types of work your service performs. Protecting these cells can significantly improve recovery time.
[TP-7] Implement egress bulkhead when calling dependencies
Egress bulkheads are necessary to limit the maximum number of concurrent in-flight calls (see item 4 in image showing throttling points in a system). While each dependency should protect itself, those protections might not always be in place.
Traffic to dependencies traverses Layers 3 and 4 systems (often shared, such as load balancers and switches) before reaching Layer 7, where throttling might occur. As a result, congestion can happen before application-level throttling kicks in.
At small timescales, requests don't arrive uniformly within the throttling aggregation window. A short surge might be acceptable for your system but can still overwhelm downstream infrastructure (queues fill, sockets exhaust, and downstream systems destabilize).
Egress bulkheads help by flattening traffic and reducing variance between your service and your dependencies, which increases overall stability. Ensure your client SDK supports egress bulkheads.
Watch out for fan-out points: places where one incoming unit-of-work turns into multiple requests (batch calls, queue processors, workflows, bulk DB updates). Bulkheads here require attention to call ordering, expiration, and recovery.
Egress bulkheads limit concurrent in-flight calls to dependencies. Apply them at fan-out points where one unit of work becomes many downstream requests.
[TP-8] Don't use caching to replace throttling
Some services implement a cache to improve resilience or latency, which can reduce steady-state load. This approach can appear to work, but it can fail when caller traffic creates cache misses and drives unplanned load from a capacity perspective.
Use caching when it helps, but keep throttling and bulkheads in place for worst-case miss scenarios. This approach also helps reduce the impact of cache-busting DoS attacks. Also account for cold-start cache hydration: restarting a partition can create temporary load on working partitions. Caches provide real benefits, but they also add architectural complexity.
Cache to improve latency and steady-state load, but set throttling limits that hold at worst-case cache miss rates, not average-case.
[TP-9] Keep throttling accounting out of critical path
Regardless of the throttling service you use, report usage and retrieve decisions asynchronously. This approach improves resilience because the system can still function if the throttling service fails. Consider dedicating a thread in your application to perform throttling accounting and maintain enforcement decisions that request-processing threads can read quickly. The application's critical paths can submit usage to this thread and synchronously check the decisions it provides.
Perform throttling accounting asynchronously so that a slow or unavailable throttle store doesn't block the request critical path.
[TP-10] Pay attention to cross-cutting infrastructure
Cross-cutting dependencies such as DNS zone updates, often group traffic for throttling differently than your service does. These dependencies often have little or no business logic and are assumed to be infinitely scalable, then forgotten. However, a single consumer can push this shared infrastructure into the red zone and cause throttling for many unrelated users. As a result, make sure that:
- Your service does not overwhelm such a service; apply TP-7 to avoid broader-than-necessary impact.
- You have a plan for when a cross-cutting dependency is unavailable. Caching "last known good" responses and using pre-decided brownouts can be effective techniques.
Be suspicious of dependencies that don't throttle at all. They might silently hit limits and return 500s to all users without warning.
[TP-11] Reassess, tune, and validate periodically
Periodically revisit configuration to ensure it reflects current usage patterns across your system. Ideally, do this as part of a weekly live-site review, using a dedicated dashboard that shows current limits and both real-time and historical utilization (high and low watermarks). Use automation. Ensure incident reviews include this usage-pattern analysis.
Validation techniques: Run periodic testing by setting low limits in throttling policies or using Chaos Studio to ensure 429 handling behavior and DRI triage capability haven't regressed. Other testing includes:
- Recreate the last N outages (N decided by the service owner).
- Load test least-used APIs
- Load test most expensive APIs
At a minimum, strongly consider coupling at least two of these tests with zonal outage drills.
Creating replica environments with mocked dependencies and AI-driven traffic generators can validate non-functional goals (performance and resiliency) and is recommended as a long-term investment.
Periodically review limits against current usage patterns. Static limits decay as traffic evolves. Validate through controlled low-limit testing.
[TP-12] Implement state-aware throttling
Throttling that reacts to system state reallocates scarce capacity in alignment with business goals. Techniques include:
- Dynamic throttling: Modulate nominal cost based on operation type (read vs. write) or current state (queue length, memory).
- Bankruptcy: For asynchronous systems, re-evaluate queued work when cost or state changes. Be able to drop enqueued work (declare bankruptcy). Deadlines and LIFO prioritization can help.
- Brownouts: Pre-decided degraded modes when health metrics exceed thresholds (disable low-priority operations, return shorter results, and so on).
- Bursting and borrowing: Allow short-term consumption above baseline. Borrowing uses spare capacity from others. Both require careful fairness controls.
Throttling that reacts to real-time system state, rather than fixed limits, allocates scarce capacity in alignment with business priorities.
[TP-13] Honor transactional boundaries
For service APIs with transactional semantics, ensure throttling can prioritize in-flight transactions over starting new ones. Throttling sub-operations of a transactional API can cause transaction failure or rollback, which wastes resources and degrades user experience. You can implement this behavior through special transaction identifiers passed with the API call, although more natural identifiers might exist in your use case. This approach requires careful design and application changes.
Prioritize completing in-flight transactional operations over admitting new ones to avoid wasting partially consumed resources.
[TP-14] Implement random early drop
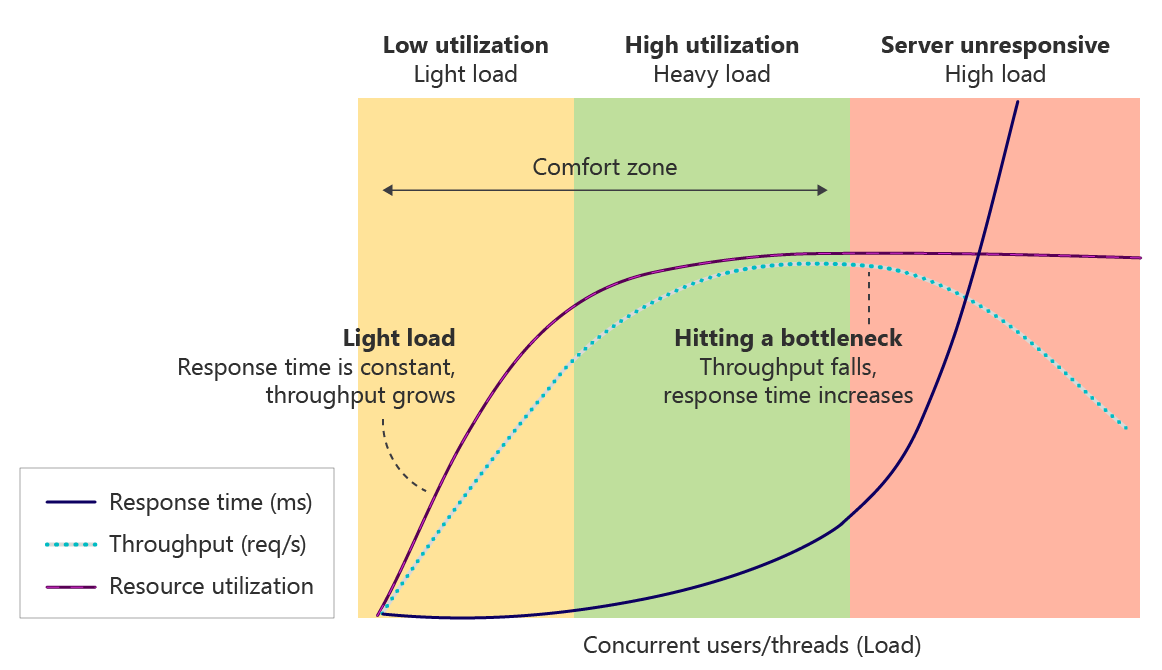
As aggregate usage approaches high utilization limits (see Image showing resource utilization change with load), start rejecting a carefully chosen fraction of traffic. A positive value for remaining tokens in the RateLimit header signals to callers that their traffic is in this category and that the system is nearing limits. Benefits: (1) prevent the system from reaching the red zone, and (2) validate that upstream partners remain ready to respect constraints.
{kind=link}
Start shedding a fraction of traffic early as aggregate usage approaches limits, before hitting the hard ceiling.