Object detection using Faster R-CNN
Table of Contents
Summary

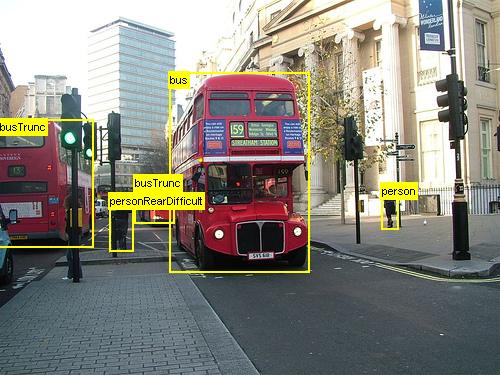
The above are examples images and object annotations for the Grocery data set (left) and the Pascal VOC data set (right) used in this tutorial.
Faster R-CNN is an object detection algorithm proposed by Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun in 2015. The research paper is titled 'Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks', and is archived at https://arxiv.org/abs/1506.01497. Faster R-CNN builds on previous work to efficiently classify object proposals using deep convolutional networks. Compared to previous work, Faster R-CNN employs a region proposal network and does not require an external method for candidate region proposals.
This tutorial is structured into three main sections. The first section provides a concise description of how to run Faster R-CNN in CNTK on the provided example data set. The second section provides details on all steps including setup and parameterization of Faster R-CNN. The final section discusses technical details of the algorithm and the region proposal network, reading and augmenting the input data as well as different training options for Faster R-CNN.
Quick start
This section assumes that you have your system set up to use the CNTK Python API. We further assume you're using Python 3.5 on Windows or 3.5/3.6 on Linux. For a detailed walk through please refer to the step by step instructions. To run Faster R-CNN please install the following additional packages in your cntk Python environment
pip install opencv-python easydict pyyaml
Run the toy example
We use a toy dataset of images captured from a refrigerator to demonstrate Faster R-CNN (the same as for the Fast R-CNN example). Both the dataset and the pre-trained AlexNet model can be downloaded by running the following Python command from the Examples/Image/Detection/FastRCNN folder:
python install_data_and_model.py
After running the script, the toy dataset will be installed under the Examples/Image/DataSets/Grocery folder. The AlexNet model will be downloaded to the PretrainedModels folder.
We recommend to keep the downloaded data in the respective folder as the configuration files assume that location by default.
To train and evaluate Faster R-CNN run
python run_faster_rcnn.py
The results for end-to-end training on Grocery using AlexNet as the base model should look similar to these:
AP for gerkin = 1.0000
AP for butter = 1.0000
AP for joghurt = 1.0000
AP for eggBox = 1.0000
AP for mustard = 1.0000
AP for champagne = 1.0000
AP for orange = 1.0000
AP for water = 0.5000
AP for avocado = 1.0000
AP for tomato = 1.0000
AP for pepper = 1.0000
AP for tabasco = 1.0000
AP for onion = 1.0000
AP for milk = 1.0000
AP for ketchup = 0.6667
AP for orangeJuice = 1.0000
Mean AP = 0.9479
To visualize the predicted bounding boxes and labels on the images open FasterRCNN_config.py from the FasterRCNN folder and set
__C.VISUALIZE_RESULTS = True
The images will be saved into the FasterRCNN/Output/Grocery/ folder if you run python run_faster_rcnn.py.
Step-by-step instructions
Setup
To run the code in this example, you need a CNTK Python environment (see here for setup help). Please install the following additional packages in your cntk Python environment
pip install opencv-python easydict pyyaml
Pre-compiled binaries for bounding box regression and non maximum suppression
The folder Examples\Image\Detection\utils\cython_modules contains pre-compiled binaries that are required for running Faster R-CNN. The versions that are currently contained in the repository are Python 3.5 for Windows and Python 3.5, 3.6 for Linux, all 64 bit. If you need a different version you can compile it following the steps described at
- Linux: https://github.com/rbgirshick/py-faster-rcnn
- Windows: https://github.com/MrGF/py-faster-rcnn-windows
Copy the generated cython_bbox and cpu_nms (and/or gpu_nms) binaries from $FRCN_ROOT/lib/utils to $CNTK_ROOT/Examples/Image/Detection/utils/cython_modules.
Example data and baseline model
We use a pre-trained AlexNet model as the basis for Faster-R-CNN training (for VGG or other base models see Using a different base model. Both the example dataset and the pre-trained AlexNet model can be downloaded by running the following Python command from the FastRCNN folder:
python install_data_and_model.py
- Learn how to use a different base model
- Learn how to run Faster R-CNN on Pascal VOC data
- Learn how to run Faster R-CNN on your own data
Configuration and Parameters
The parameters are grouped into three parts:
- Detector parameters (see
FasterRCNN/FasterRCNN_config.py) - Data set parameters (see for example
utils/configs/Grocery_config.py) - Base model parameters (see for example
utils/configs/AlexNet_config.py)
The three parts are loaded and merged in the get_configuration() method in run_faster_rcnn.py. In this section we'll cover the detector parameters. Data set parameters are described here, base model parameters here. In the following we go through the content of FasterRCNN_config.py from top to bottom. The configuration uses the EasyDict package that allows easy access to nested dictionaries.
# If set to 'True' training will be skipped if a trained model exists already
__C.CNTK.MAKE_MODE = False
# E2E or 4-stage training
__C.CNTK.TRAIN_E2E = True
# set to 'True' to use deterministic algorithms
__C.CNTK.FORCE_DETERMINISTIC = False
# set to 'True' to run only a single epoch
__C.CNTK.FAST_MODE = False
# Debug parameters
__C.CNTK.DEBUG_OUTPUT = False
__C.CNTK.GRAPH_TYPE = "png" # "png" or "pdf"
# Set to True if you want to store an eval model with native UDFs (e.g. for inference using C++ or C#)
__C.STORE_EVAL_MODEL_WITH_NATIVE_UDF = False
The first block of parameters contains higher level instructions regarding the training process. __C.CNTK.TRAIN_E2E allows to select either the end-to-end or 4-stage training scheme. Details about the two training schemes are described here. __C.CNTK.FAST_MODE = True runs only a single epoch; it is useful to test whether the setup is working and all parameters are correct. __C.CNTK.DEBUG_OUTPUT = True generates additional debug message in the console output. It also plots CNTK computation graphs for both the training and eval models (note the requirements for plotting CNTK graphs). The resulting graphs are stored in the FasterRCNN/Output folder. __C.STORE_EVAL_MODEL_WITH_NATIVE_UDF = True will store a second evaluation model that uses only native code (no Python layers). This model can be loaded and evaluated from C++ or C# for example.
# Learning parameters
__C.CNTK.L2_REG_WEIGHT = 0.0005
__C.CNTK.MOMENTUM_PER_MB = 0.9
# The learning rate multiplier for all bias weights
__C.CNTK.BIAS_LR_MULT = 2.0
# E2E learning parameters
__C.CNTK.E2E_MAX_EPOCHS = 20
__C.CNTK.E2E_LR_PER_SAMPLE = [0.001] * 10 + [0.0001] * 10 + [0.00001]
The second block contains the learning parameters. These are mostly regular CNTK learning parameters. The only exception is __C.CNTK.BIAS_LR_MULT, which is the learning rate multiplier that is used for all biases in the network. It essentially trains the biases with twice the current learning rate, which is also done in the original Faster R-CNN code. The number of epochs and learning rate per sample are specified separately for the two different learning schemes (4-stage parameters omitted above).
# Maximum number of ground truth annotations per image
__C.INPUT_ROIS_PER_IMAGE = 50
__C.IMAGE_WIDTH = 850
__C.IMAGE_HEIGHT = 850
# Sigma parameter for smooth L1 loss in the RPN and the detector (DET)
__C.SIGMA_RPN_L1 = 3.0
__C.SIGMA_DET_L1 = 1.0
# NMS threshold used to discard overlapping predicted bounding boxes
__C.RESULTS_NMS_THRESHOLD = 0.5
# all bounding boxes with a score lower than this threshold will be considered background
__C.RESULTS_NMS_CONF_THRESHOLD = 0.0
# Enable plotting of results generally / also plot background boxes / also plot unregressed boxes
__C.VISUALIZE_RESULTS = False
__C.DRAW_NEGATIVE_ROIS = False
__C.DRAW_UNREGRESSED_ROIS = False
# only for plotting results: boxes with a score lower than this threshold will be considered background
__C.RESULTS_BGR_PLOT_THRESHOLD = 0.1
__C.INPUT_ROIS_PER_IMAGE specifies the maximum number of ground truth annotations per image. CNTK currently requires to set a maximum number. If there are fewer annotations they will be padded internally. __C.IMAGE_WIDTH and __C.IMAGE_HEIGHT are the dimensions that are used to resize and pad the input images. __C.RESULTS_NMS_THRESHOLD is the NMS threshold used to discard overlapping predicted bounding boxes in evaluation. A lower threshold yields fewer removals and hence more predicted bounding boxes in the final output.
# Use horizontally-flipped images during training?
__C.TRAIN.USE_FLIPPED = True
# If set to 'True' conv layers weights from the base model will be trained, too
__C.TRAIN_CONV_LAYERS = True
# RPN parameters
# IOU >= thresh: positive example
__C.TRAIN.RPN_POSITIVE_OVERLAP = 0.7
# IOU < thresh: negative example
__C.TRAIN.RPN_NEGATIVE_OVERLAP = 0.3
# If an anchor statisfied by positive and negative conditions set to negative
__C.TRAIN.RPN_CLOBBER_POSITIVES = False
# Max number of foreground examples
__C.TRAIN.RPN_FG_FRACTION = 0.5
# Total number of examples
__C.TRAIN.RPN_BATCHSIZE = 256
# NMS threshold used on RPN proposals
__C.TRAIN.RPN_NMS_THRESH = 0.7
# Number of top scoring boxes to keep before apply NMS to RPN proposals
__C.TRAIN.RPN_PRE_NMS_TOP_N = 12000
# Number of top scoring boxes to keep after applying NMS to RPN proposals
__C.TRAIN.RPN_POST_NMS_TOP_N = 2000
# Proposal height and width both need to be greater than RPN_MIN_SIZE (at orig image scale)
__C.TRAIN.RPN_MIN_SIZE = 16
__C.TRAIN.USE_FLIPPED = True will augment the training data by flipping all images every other epoch, i.e. the first epoch has all regular images, the second has all images flipped, and so forth. __C.TRAIN_CONV_LAYERS determines whether the convolutional layers, from input to the convolutional feature map, will be trained or fixed. Fixing the conv layer weights means that the weights from the base model are taken and not modified during training. (You can also specify how many conv layers you want to train, see section Using a different base model). For the rpn parameters please refer to the comments next to their defintion or consult the original research paper for more details. Also for the following detector parameters:
# Detector parameters
# Minibatch size (number of regions of interest [ROIs]) -- was: __C.TRAIN.BATCH_SIZE = 128
__C.NUM_ROI_PROPOSALS = 128
# Fraction of minibatch that is labeled foreground (i.e. class > 0)
__C.TRAIN.FG_FRACTION = 0.25
# Overlap threshold for an ROI to be considered foreground (if >= FG_THRESH)
__C.TRAIN.FG_THRESH = 0.5
# Overlap threshold for an ROI to be considered background (class = 0 if
# overlap in [LO, HI))
__C.TRAIN.BG_THRESH_HI = 0.5
__C.TRAIN.BG_THRESH_LO = 0.0
# Normalize the targets using "precomputed" (or made up) means and stdevs
__C.BBOX_NORMALIZE_TARGETS = True
__C.BBOX_NORMALIZE_MEANS = (0.0, 0.0, 0.0, 0.0)
__C.BBOX_NORMALIZE_STDS = (0.1, 0.1, 0.2, 0.2)
Run Faster R-CNN on Pascal VOC
To download the Pascal data and create the annotation files for Pascal in CNTK format run the following scripts:
python Examples/Image/DataSets/Pascal/install_pascalvoc.py
python Examples/Image/DataSets/Pascal/mappings/create_mappings.py
Change the dataset_cfg in the get_configuration() method of run_faster_rcnn.py to
from utils.configs.Pascal_config import cfg as dataset_cfg
Now you're set to train on the Pascal VOC 2007 data using python run_faster_rcnn.py. Beware that training might take a while.
Run Faster R-CNN on your own data
Preparing your own data and annotating it with ground truth bounding boxes is described in Object detection using Fast R-CNN. After storing your images in the described folder structure and annotating them please run
python Examples/Image/Detection/utils/annotations/annotations_helper.py
after changing the folder in that script to your data folder. Finally, create a MyDataSet_config.py in the utils\configs folder following the existing examples, as in this code snippet:
...
# data set config
__C.DATA.DATASET = "YourDataSet"
__C.DATA.MAP_FILE_PATH = "../../DataSets/YourDataSet"
__C.DATA.CLASS_MAP_FILE = "class_map.txt"
__C.DATA.TRAIN_MAP_FILE = "train_img_file.txt"
__C.DATA.TRAIN_ROI_FILE = "train_roi_file.txt"
__C.DATA.TEST_MAP_FILE = "test_img_file.txt"
__C.DATA.TEST_ROI_FILE = "test_roi_file.txt"
__C.DATA.NUM_TRAIN_IMAGES = 500
__C.DATA.NUM_TEST_IMAGES = 200
__C.DATA.PROPOSAL_LAYER_SCALES = [8, 16, 32]
...
__C.CNTK.PROPOSAL_LAYER_SCALES is used in generate_anchors() (see utils/rpn/generate_anchors.py). Starting from a base size of 16 three anchors with aspect ratios 0.5, 1.0 and 2.0 are created resulting in (8 x 24, 16 x 16, 24 x 8). These are multiplied with each proposal layer scale resulting in nine anchors (64 x 192, ... , 768 x 256). These are absolute pixel coordinates w.r.t. the input image. All anchors are applied at each spatial position of the convolutional feature map to generate candidate regions of interest. Adapt these proposal layer scales according to the object sizes in your data set and the input image size you're using. For example, for the Grocery data set we're using __C.DATA.PROPOSAL_LAYER_SCALES = [4, 8, 12] and an input image size of 850 x 850 (see utils/configs/Grocery_config.py).
To train and evaluate Faster R-CNN on your data change the dataset_cfg in the get_configuration() method of run_faster_rcnn.py to
from utils.configs.MyDataSet_config import cfg as dataset_cfg
and run python run_faster_rcnn.py.
Technical Details
As most DNN based object detectors Faster R-CNN uses transfer learning. It starts from a base model which is a model trained for image classification. The base model is cut into two parts, the first one being all convolutional layers up to (and excluding) the last pooling layer and the second part is the remainder of the network from (and excluding) the last pooling layer up to (again excluding) the final prediction layer. The output of the first part is sometimes called the convolutional feature map. This is used as the input to the roi pooling layer, which performs a pooling operation on a part of the input map that corresponds to region proposals in the original image. The region proposals are a second input to the roi pooling layer. In Faster R-CNN these proposals are generated by a small sub-network called region proposal network (RPN, see next section).
The output of the roi pooling layer will always have the same fixed size, as it pools any input (convolutional feature map + region proposal) to the same output size. Note that the input size, i.e. the size of the convolutional featute map and hence also the input image size, can be arbitrary. For training the algorithm uses four loss functions, two for the RPN and two for the detector (see also next section). The following method is contained in FasterRCNN_train.py and shows the high level construction of the Faster R-CNN model. Please refer to FasterRCNN_train.py and utils/rpn/rpn_helpers.py for the full code.
def create_faster_rcnn_model(features, scaled_gt_boxes, dims_input, cfg):
# Load the pre-trained classification net and clone layers
base_model = load_model(cfg['BASE_MODEL_PATH'])
conv_layers = clone_conv_layers(base_model, cfg)
fc_layers = clone_model(base_model, [cfg["MODEL"].POOL_NODE_NAME], [cfg["MODEL"].LAST_HIDDEN_NODE_NAME], clone_method=CloneMethod.clone)
# Normalization and conv layers
feat_norm = features - Constant([[[v]] for v in cfg["MODEL"].IMG_PAD_COLOR])
conv_out = conv_layers(feat_norm)
# RPN and prediction targets
rpn_rois, rpn_losses = create_rpn(conv_out, scaled_gt_boxes, dims_input, cfg)
rois, label_targets, bbox_targets, bbox_inside_weights = \
create_proposal_target_layer(rpn_rois, scaled_gt_boxes, cfg)
# Fast RCNN and losses
cls_score, bbox_pred = create_fast_rcnn_predictor(conv_out, rois, fc_layers, cfg)
detection_losses = create_detection_losses(...)
loss = rpn_losses + detection_losses
pred_error = classification_error(cls_score, label_targets, axis=1)
return loss, pred_error
After training the network is converted into an evaluation model by removing all parts that are not required for evaluation, for example, the loss functions. The final evaluation model has three outputs (see create_faster_rcnn_eval_model() in FasterRCNN_train.py for more details):
rpn_rois- the absolute pixel coordinates of the candidate roiscls_pred- the class probabilities for each ROIbbox_regr- the regression coefficients per class for each ROI
To use the evaluation model from Python you can use the FasterRCNN_Evaluator from FasterRCNN_eval.py. You can load the model once and then evaluate single images as you go. The process_image() method of the evaluator takes a path to an image as its argument, evaluates the model on that image and applies the bounding box regression to the resulting ROIs. It returns the regressed ROIs and the corresponding class probabilities:
evaluator = FasterRCNN_Evaluator(model, cfg)
regressed_rois, cls_probs = evaluator.process_image(img_path)
Region proposal network
Faster R-CNN uses a so called region proposal netwrok (RPN) that generates candidate regions of interest (ROIs) based on the input image. This is opposed to Fast R-CNN which requires region proposals to be provided by an external source. The RPN is essentially build up by three convolution layers and a new layer called proposal layer. The new layers are realized as user defined function (UDF) in either Python or C++ (see details below). The Python code that creates the RPN in CNTK is in utils/rpn/rpn_helpers.py, the new layers such as the proposal layer are all in the utils/rpn folder.
The input to the RPN is the convolutional feature map, the same that is the input to the ROI pooling layer. This input is fed into the first convolution layer of the RPN and the result is propagated to the other two convolution layers. One of the latter predicts class scores for each candidate region, i.e. for each anchor at each spatial position (9 anchors x 2 scores x width x height). The two scores are converted (using a softmax node) into objectness scores per candidate which are interpreted as the probability of a candidate region to contain a foreground object or not. The other convolutional layer predicts regression coefficients for the actual position of the ROI, again for each candidate (9 anchors x 4 coefficients x width x height).
The regression coefficients and the objectness scores (foreground and background probabilities) are fed into the proposal layer. This layer first applies the regression coefficients to the generated anchors, clips the result to the image boundaries and filters out candidate regions that are too small. It then sorts the candidates by foreground probability, applies non-maximum suppression (NMS) to reduce the number of candidates and finally samples the desired number of ROIs for its output.
During training Faster R-CNN requires two additional new layers: the anchor target layer and the proposal target layer. The anchor target layer generates the target values for the objectness score and the RPN regression coefficients that are used in the loss functions of the RPN. Similarly, the proposal target layer generates the target class labels for the ROIs and the target regression coefficients per class for the final detector which are used in the loss functions of the detector.
During evaluation only the proposal layer is required (since no targets for loss functions are needed). The proposal layer in CNTK is available in Python as well as C++, the target layers are currently only available in Python. Therefore, training Faster R-CNN has currently to be done from the Python API. To store an evaluation model after training that uses the native proposal layer implementation set __C.STORE_EVAL_MODEL_WITH_NATIVE_UDF = True.
Reader and minibatch source
When we scale images or flip images for data augmentation we need to apply the same transformations to the ground truth annotations, too. (Flipping also has to be applied to cached proposals in 4-stage training, see next section.) Since these joined transformations of images and annotations are currently not supported by the built in CNTK readers we use a custom Python reader and a UserMinibatchSource for Faster R-CNN. These are contained in utils/od_reader.py and utils/od_mb_source.py respectively.
E2E and 4-stage training
The Faster R-CNN research paper describes two methods to train the network. End-to-end training trains the entire network in a single training using all four loss function (rpn regression loss, rpn objectness loss, detector regression loss, detector class loss). We use end-to-end training by default, you can chose between the two by setting __C.CNTK.TRAIN_E2E accordingly in FasterRCNN_config.py.
The 4-stage training scheme alternates between training only the region proposal network (keeping the detector fixed) and training only the detector (fixing the RPN weights). This training scheme is implemented in train_faster_rcnn_alternating() in FasterRCNN_train.py. It is slightly more elaborate and makes frequent use of cloning parts of the model to enable freezing and training weights selectively. Also, in 4-stage training the proposals from the RPN are buffered after stages one and three and used in the subsequent stage.
Using a different base model
To use a different base model you need to choose a different model configuration in the get_configuration() method of run_faster_rcnn.py. Two models are supported right away:
# for VGG16 base model use: from utils.configs.VGG16_config import cfg as network_cfg
# for AlexNet base model use: from utils.configs.AlexNet_config import cfg as network_cfg
To download the VGG16 model please use the download script in <cntkroot>/PretrainedModels:
python download_model.py VGG16_ImageNet_Caffe
If you want to use another different base model you need to copy, for example, the configuration file utils/configs/VGG16_config.py and modify it according to your base model:
# model config
__C.MODEL.BASE_MODEL = "VGG16"
__C.MODEL.BASE_MODEL_FILE = "VGG16_ImageNet_Caffe.model"
__C.MODEL.IMG_PAD_COLOR = [103, 116, 123]
__C.MODEL.FEATURE_NODE_NAME = "data"
__C.MODEL.LAST_CONV_NODE_NAME = "relu5_3"
__C.MODEL.START_TRAIN_CONV_NODE_NAME = "pool2" # __C.MODEL.FEATURE_NODE_NAME
__C.MODEL.POOL_NODE_NAME = "pool5"
__C.MODEL.LAST_HIDDEN_NODE_NAME = "drop7"
__C.MODEL.FEATURE_STRIDE = 16
__C.MODEL.RPN_NUM_CHANNELS = 512
__C.MODEL.ROI_DIM = 7
To investigate the node names of your base model you can use the plot() method from cntk.logging.graph. Please note that ResNet models are currently not supported since roi pooling in CNTK does not yet support roi average pooling.