Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Microsoft Defender for Cloud Apps enables you to natively use the Microsoft Data Classification Service to classify the files in your cloud apps. Microsoft Data Classification Service provides a unified information protection experience across Microsoft 365, Microsoft Information Protection, and Microsoft Defender for Cloud Apps. The classification service allows you to extend your data classification efforts to the third-party cloud apps protected by Microsoft Defender for Cloud Apps, using the decisions you already made across an even greater number of apps.
Note
This feature is currently available in the US, Europe, Australia, India, Canada, Japan, and APAC.
Note
To enable the Data Classification Service option in File Policies, the "Microsoft 365" App Connector is required.
Enable content inspection with Data Classification Services
You can set the Inspection method to use the Microsoft Data Classification Service with no additional configuration required. This option is useful when creating a data leak prevention policy for your files in Microsoft Defender for Cloud Apps.
In the file policy page, under Inspection method, select Data Classification Service. You can also set the Inspection method in the session policy page with Control file download (with inspection) selected.
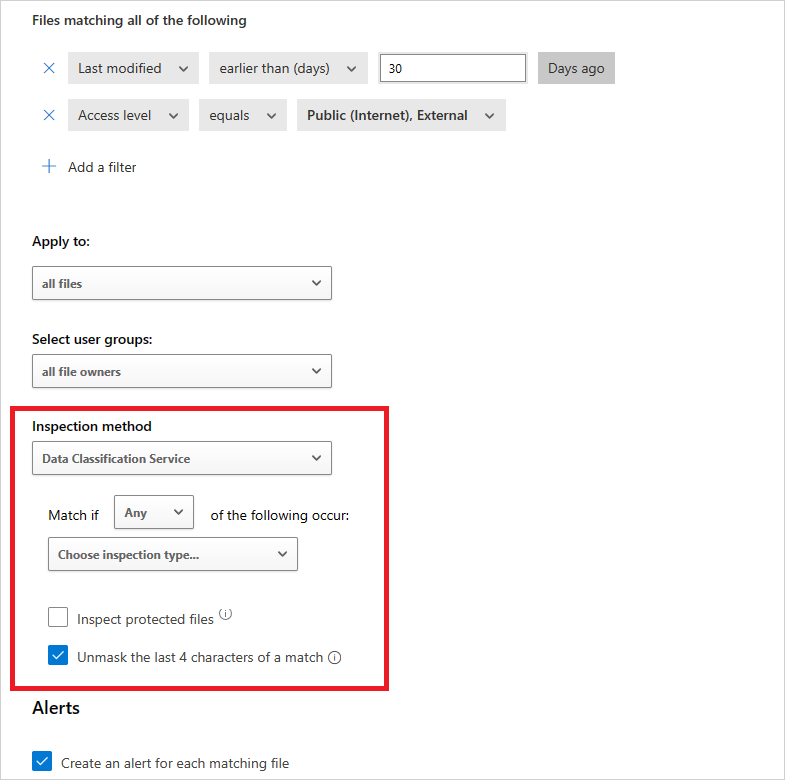
Select whether the policy should apply when any or all of the criteria are met.
Choose inspection type by selecting the Sensitive information types.
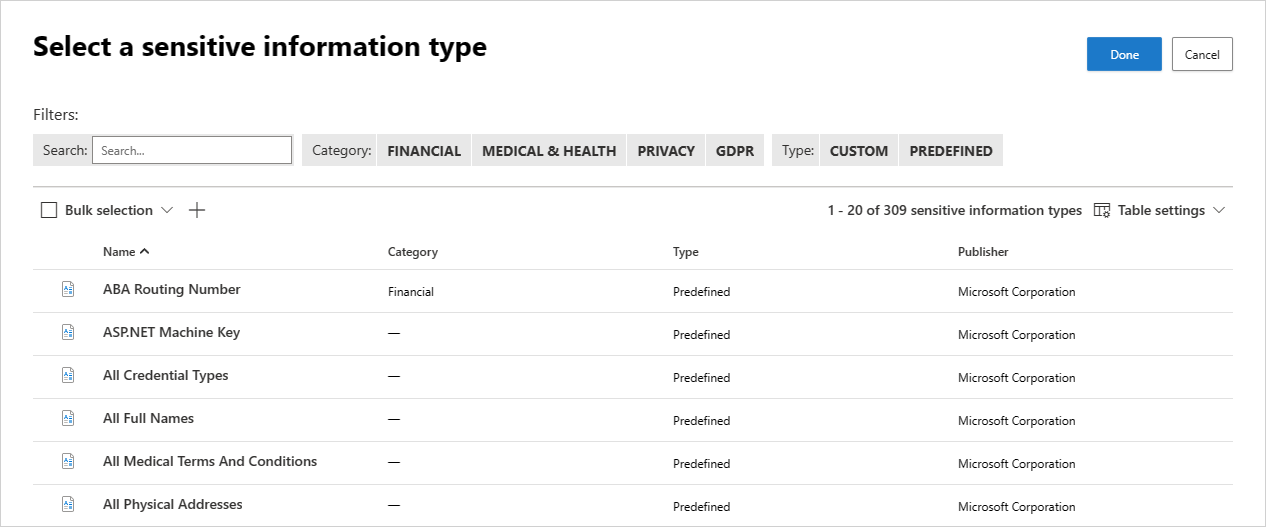
You can use the default sensitive information types to define what happens to files protected by Microsoft Defender for Cloud Apps. You can also reuse any of your Microsoft 365 custom sensitive information types.
Note
You can configure your policy to use advanced classification types such as Fingerprints, Exact Data Match, and trainable classifiers.
Optionally, you can unmask the last four characters of a match. By default, matches are masked and shown in their context, and include the 40 characters before and after the match. If you select this checkbox, it will unmask the last four characters of the match itself.
Leveraging file policies, you can also set alerts and governance actions for the policy. For more information, see file policies and governance actions. Leveraging session policies, you can also monitor and control actions in real-time when a file matches a DCS type. For more information, see session policy.
Setting these policies enables you to easily extend the strength of the Microsoft 365 DLP capabilities to all your other sanctioned cloud apps and protect the data stored in them with the full toolset provided to you by Microsoft Defender for Cloud Apps – such as the ability to automatically apply Microsoft Information Protection sensitivity labels and the ability to control sharing permissions.
Examine evidence (preview)
Defender for Cloud Apps already includes the ability to explore policy file matches that contain sensitive information types (SITs). Now Defender for Cloud Apps also allows you to differentiate between multiple SITs in the same file match. This feature, known as short evidence, lets Defender for Cloud Apps better manage and protect your organization's sensitive data.
The short evidence feature is relevant for file policies that contain content inspection using the DCS engine.
Configure a file policy and choose the relevant DCS classifiers. If you already use a file policy with DCS, this feature will work for all the feature's files.
On the Policies page, enter the relevant file policy and select the policy matches.
You can then analyze the different SITs with a clickable, color-coding distinguisher.

Next steps
If you run into any problems, we're here to help. To get assistance or support for your product issue, please open a support ticket.