Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Tip
This content is an excerpt from the eBook, Architecting Cloud Native .NET Applications for Azure, available on .NET Docs or as a free downloadable PDF that can be read offline.

The benefits of caching are well understood. The technique works by temporarily copying frequently accessed data from a backend data store to fast storage that's located closer to the application. Caching is often implemented where...
- Data remains relatively static.
- Data access is slow, especially compared to the speed of the cache.
- Data is subject to high levels of contention.
Why?
As discussed in the Microsoft caching guidance, caching can increase performance, scalability, and availability for individual microservices and the system as a whole. It reduces the latency and contention of handling large volumes of concurrent requests to a data store. As data volume and the number of users increase, the greater the benefits of caching become.
Caching is most effective when a client repeatedly reads data that is immutable or that changes infrequently. Examples include reference information such as product and pricing information, or shared static resources that are costly to construct.
While microservices should be stateless, a distributed cache can support concurrent access to session state data when absolutely required.
Also consider caching to avoid repetitive computations. If an operation transforms data or performs a complicated calculation, cache the result for subsequent requests.
Caching architecture
Cloud native applications typically implement a distributed caching architecture. The cache is hosted as a cloud-based backing service, separate from the microservices. Figure 5-15 shows the architecture.
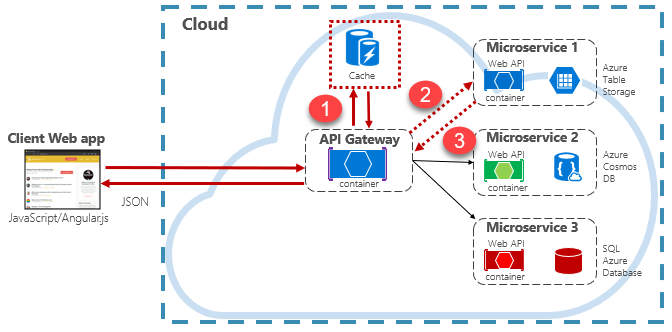
Figure 5-15: Caching in a cloud native app
In the previous figure, note how the cache is independent of and shared by the microservices. In this scenario, the cache is invoked by the API Gateway. As discussed in chapter 4, the gateway serves as a front end for all incoming requests. The distributed cache increases system responsiveness by returning cached data whenever possible. Additionally, separating the cache from the services allows the cache to scale up or out independently to meet increased traffic demands.
The previous figure presents a common caching pattern known as the cache-aside pattern. For an incoming request, you first query the cache (step #1) for a response. If found, the data is returned immediately. If the data doesn't exist in the cache (known as a cache miss), it's retrieved from a local database in a downstream service (step #2). It's then written to the cache for future requests (step #3), and returned to the caller. Care must be taken to periodically evict cached data so that the system remains timely and consistent.
As a shared cache grows, it might prove beneficial to partition its data across multiple nodes. Doing so can help minimize contention and improve scalability. Many Caching services support the ability to dynamically add and remove nodes and rebalance data across partitions. This approach typically involves clustering. Clustering exposes a collection of federated nodes as a seamless, single cache. Internally, however, the data is dispersed across the nodes following a predefined distribution strategy that balances the load evenly.
Azure Cache for Redis
Azure Cache for Redis is a secure data caching and messaging broker service, fully managed by Microsoft. Consumed as a Platform as a Service (PaaS) offering, it provides high throughput and low-latency access to data. The service is accessible to any application within or outside of Azure.
The Azure Cache for Redis service manages access to open-source Redis servers hosted across Azure data centers. The service acts as a facade providing management, access control, and security. The service natively supports a rich set of data structures, including strings, hashes, lists, and sets. If your application already uses Redis, it will work as-is with Azure Cache for Redis.
Azure Cache for Redis is more than a simple cache server. It can support a number of scenarios to enhance a microservices architecture:
- An in-memory data store
- A distributed non-relational database
- A message broker
- A configuration or discovery server
For advanced scenarios, a copy of the cached data can be persisted to disk. If a catastrophic event disables both the primary and replica caches, the cache is reconstructed from the most recent snapshot.
Azure Redis Cache is available across a number of predefined configurations and pricing tiers. The Premium tier features many enterprise-level features such as clustering, data persistence, geo-replication, and virtual-network isolation.
Collaborate with us on GitHub
The source for this content can be found on GitHub, where you can also create and review issues and pull requests. For more information, see our contributor guide.