Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Microsoft Fabric Data Engineering and Data Science experiences operate on a fully managed Spark compute platform. By default, all Spark jobs in a workspace share the same pool and resource settings, but different workloads often have different requirements. A lightweight data transformation doesn't need the same driver memory as a large-scale machine learning job.
Fabric environments let you tailor Spark compute configuration per workload, so each notebook or Spark job definition can run with the right runtime version, pool, and driver/executor sizing without changing workspace-wide defaults.
Configure workspace-level compute settings
Workspace admins control whether environment items can override the workspace default compute configuration. Keeping item-level customization disabled ensures consistent resource usage across the workspace. Enabling it gives members and contributors the flexibility to tune compute for individual workloads.
In your browser, go to your Fabric workspace in the Fabric portal.
Select Workspace settings.
Select Data Engineering/Science, and then select Spark settings.
Select the Pool tab.
Turn the Customize compute configurations for items toggle to On.
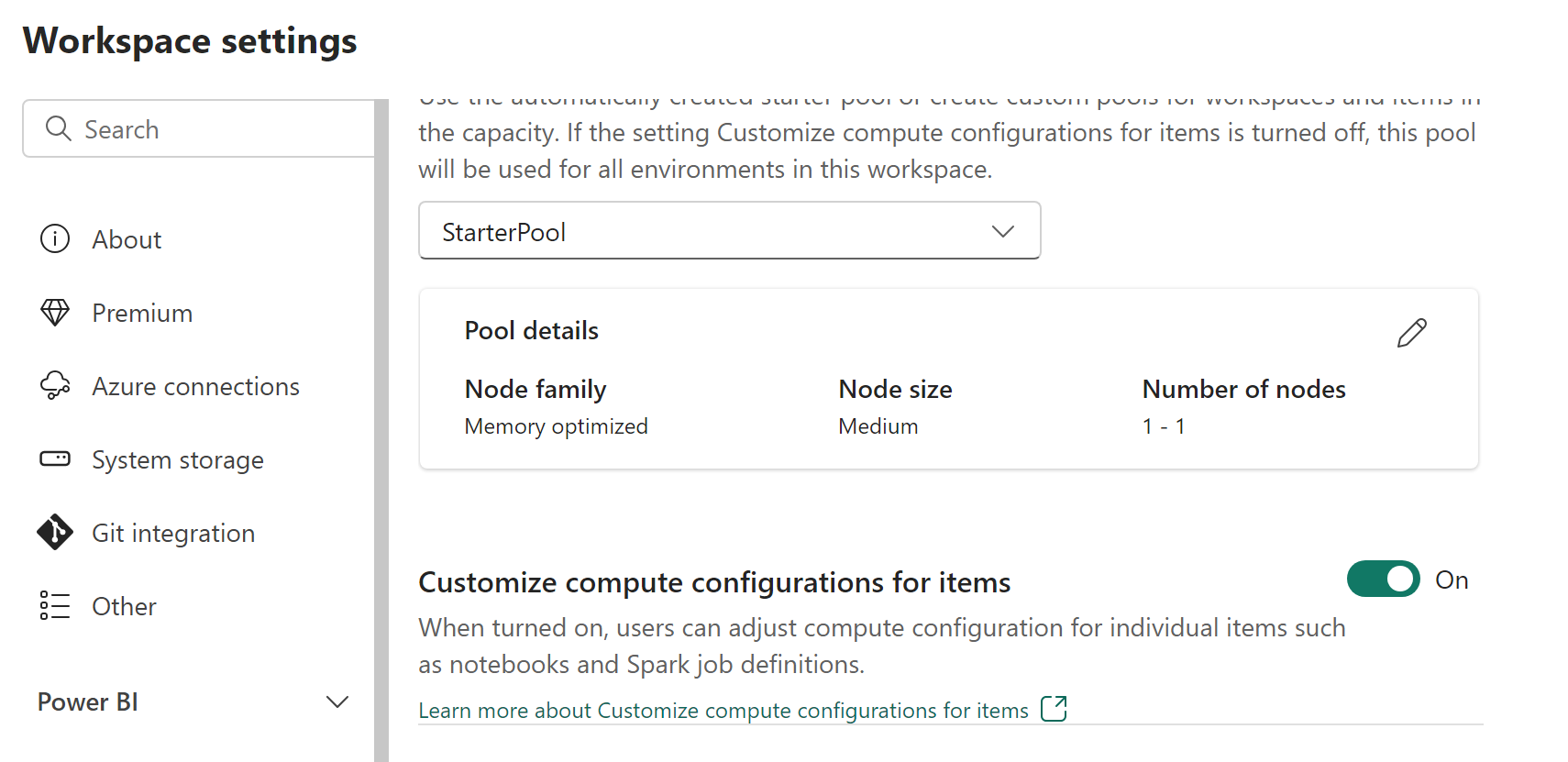
When this toggle is on, members and contributors can change session-level compute configurations in a Fabric environment. When it's off, the Compute section in environment items is disabled and all Spark jobs use the workspace default pool.
Select Save.

Configure compute in an environment
After a workspace admin enables item-level customization, you can configure compute settings inside an environment item. This includes choosing a Spark runtime, selecting a pool, and tuning driver and executor resources.
Select a Spark runtime
Open your environment item.
On the Home tab, select the Runtime dropdown and choose a runtime version.


Each Spark runtime has its own default settings and preinstalled packages.
Important
- Runtime changes don't take effect until you save and publish the environment.
- If existing libraries or compute settings aren't compatible with the selected runtime, publishing fails. Remove or update the incompatible settings, and then publish again.
- For step-by-step publish instructions, see Save and publish changes.
Select a pool and tune compute properties
Open the environment and go to the Compute section.
Under Environment pool, select the starter pool or a custom pool created by your workspace admin.
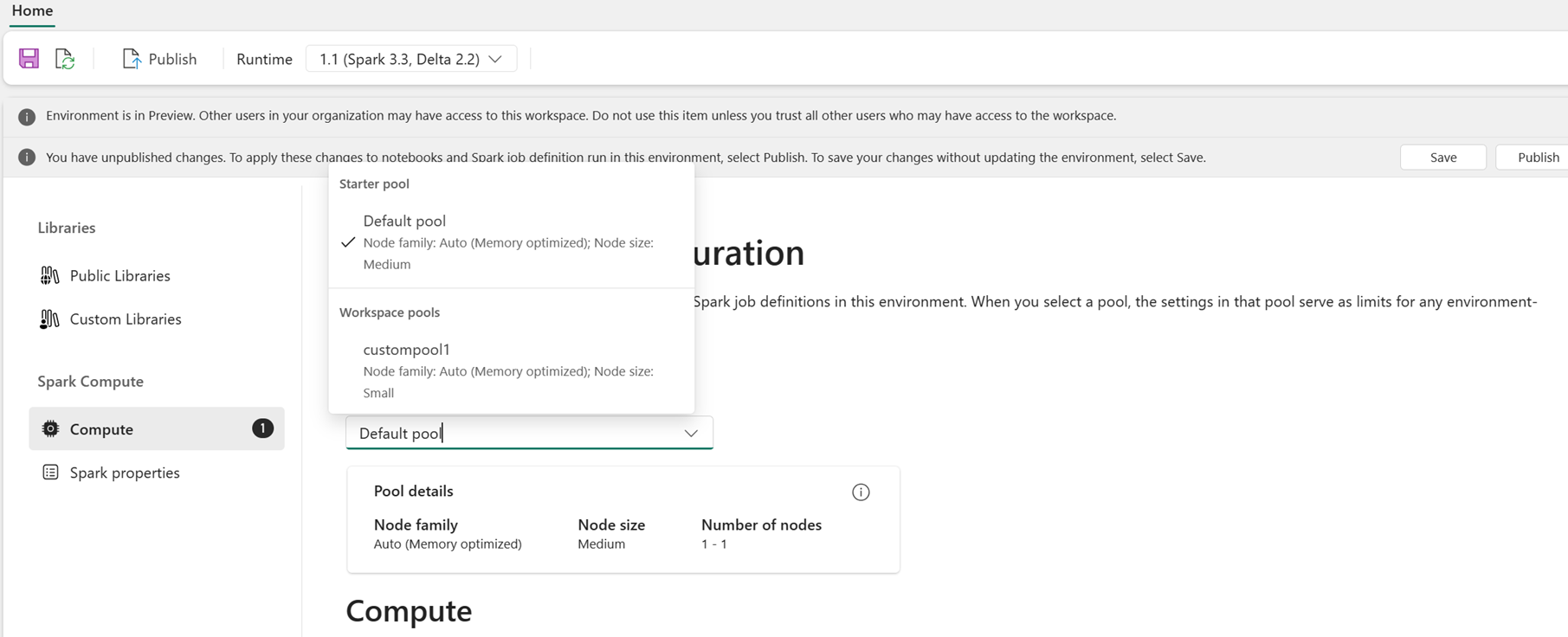
Use the dropdowns on the Compute page to configure session-level Spark properties for the selected pool. Available values depend on the node size of the pool.
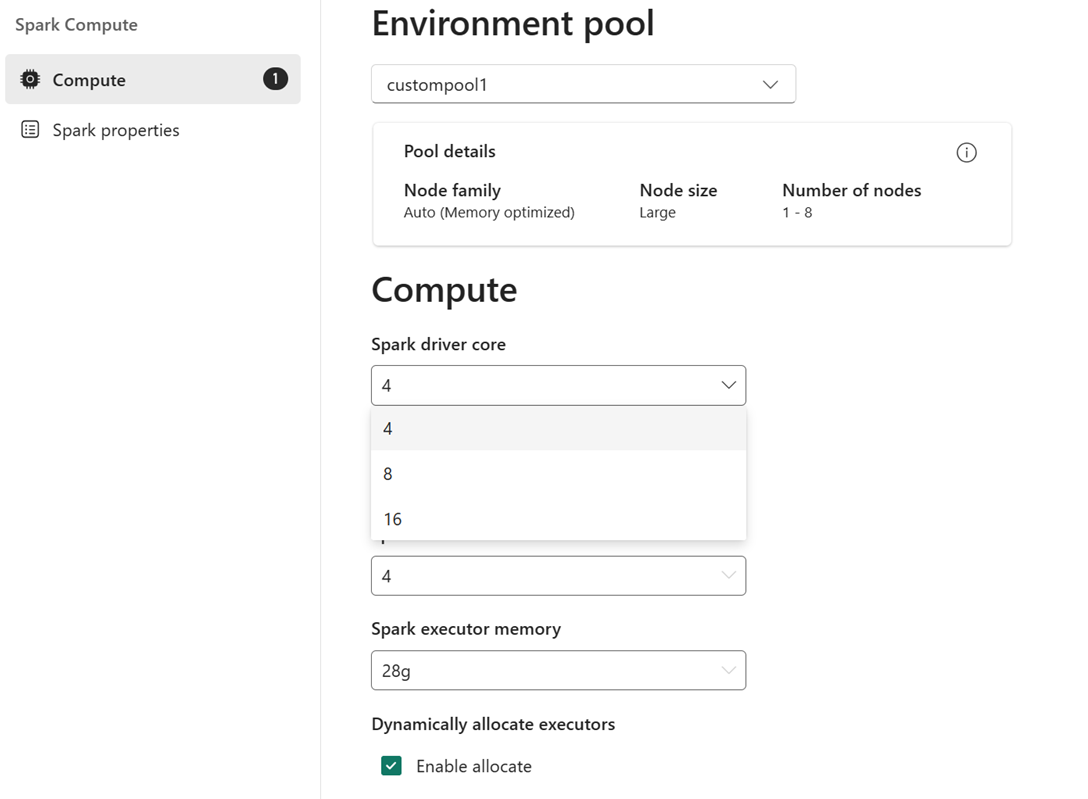
Properties include:
- Spark driver cores – Number of cores allocated to the Spark driver.
- Spark driver memory – Amount of memory allocated to the Spark driver.
- Spark executor cores – Number of cores allocated to each executor.
- Spark executor memory – Amount of memory allocated to each executor.


For details about available pool sizes and resource limits, see Spark compute in Fabric.
Note
Spark properties set through spark.conf.set control application-level parameters and aren't related to the environment compute settings described here.