Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
After you've cleaned and prepared your data with Dataflow Gen2, you want to land your data in a destination. You can do this using the data destination capabilities in Dataflow Gen2. With this capability, you can pick from different destinations, like Azure SQL, Fabric Lakehouse, and many more. Dataflow Gen2 then writes your data to the destination, and from there you can use your data for further analysis and reporting.
The following list contains the supported data destinations.
- Azure SQL databases
- Azure Data Explorer (Kusto)
- Fabric Lakehouse
- Fabric Warehouse
- Fabric KQL database
- Fabric SQL database
- SharePoint Files (preview)
Entry points
Every data query in your Dataflow Gen2 can have a data destination. Functions and lists aren't supported; you can only apply it to tabular queries. You can specify the data destination for every query individually, and you can use multiple different destinations within the dataflow.
There are three main entry-points to specify the data destination:
Through the top ribbon.
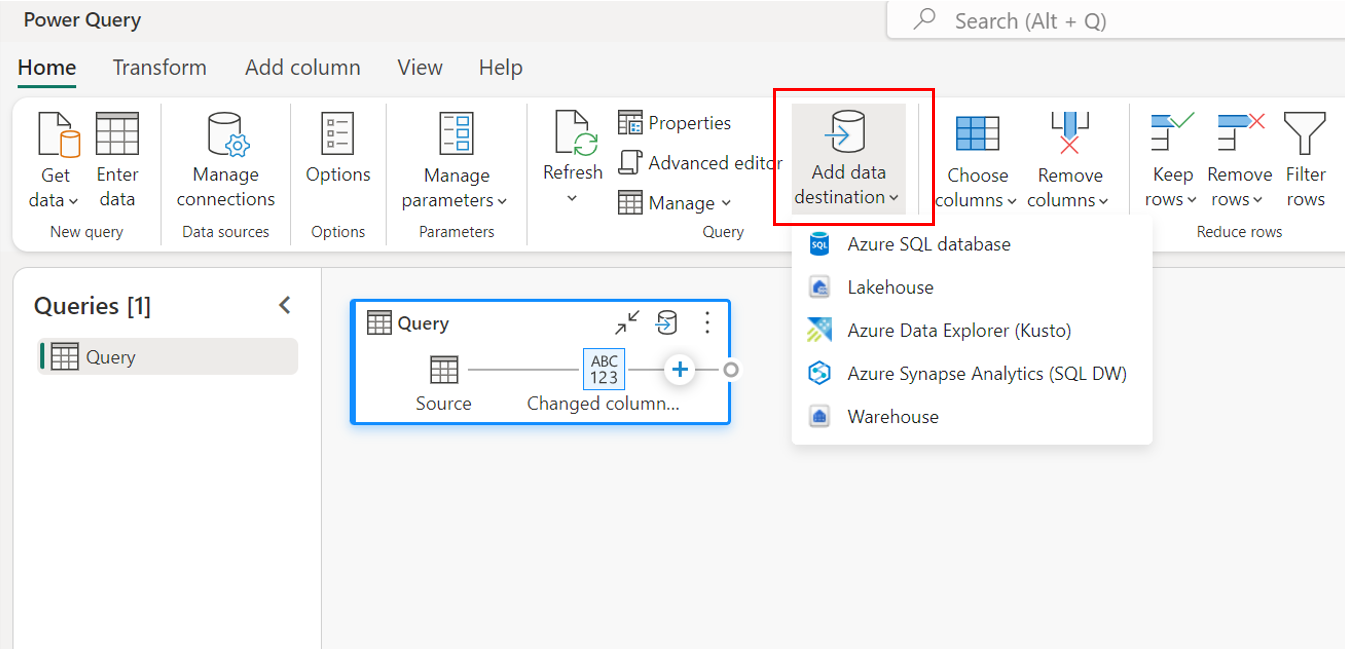
Through query settings.
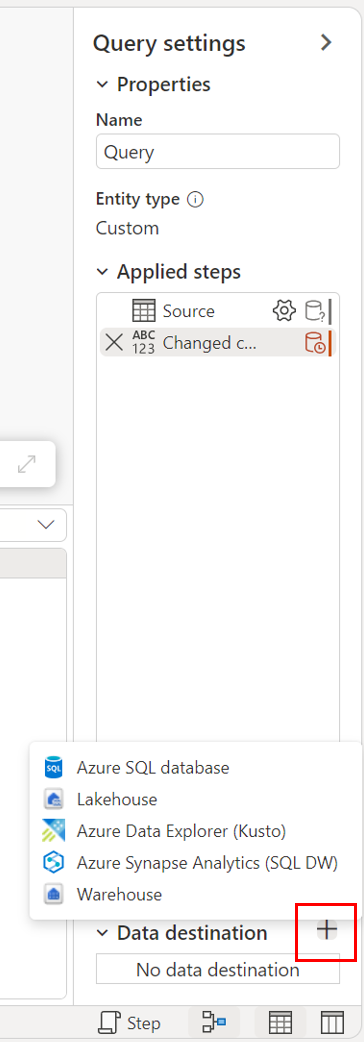
Through the diagram view.
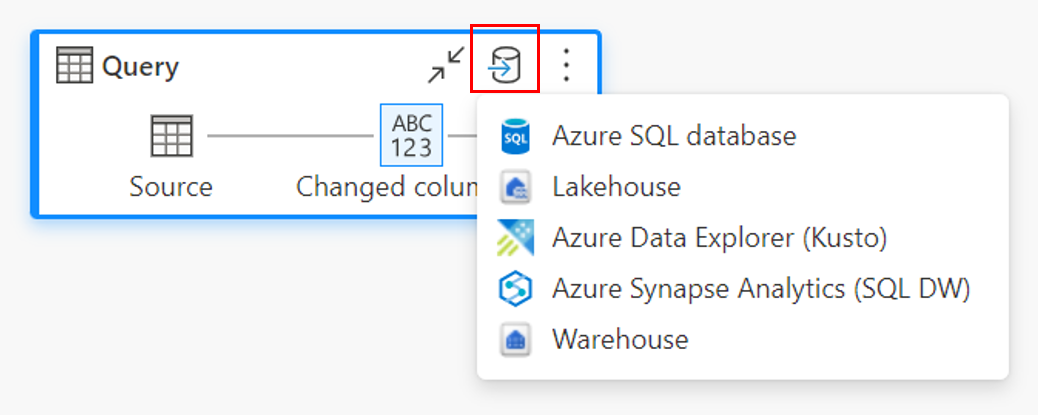
Connect to the data destination
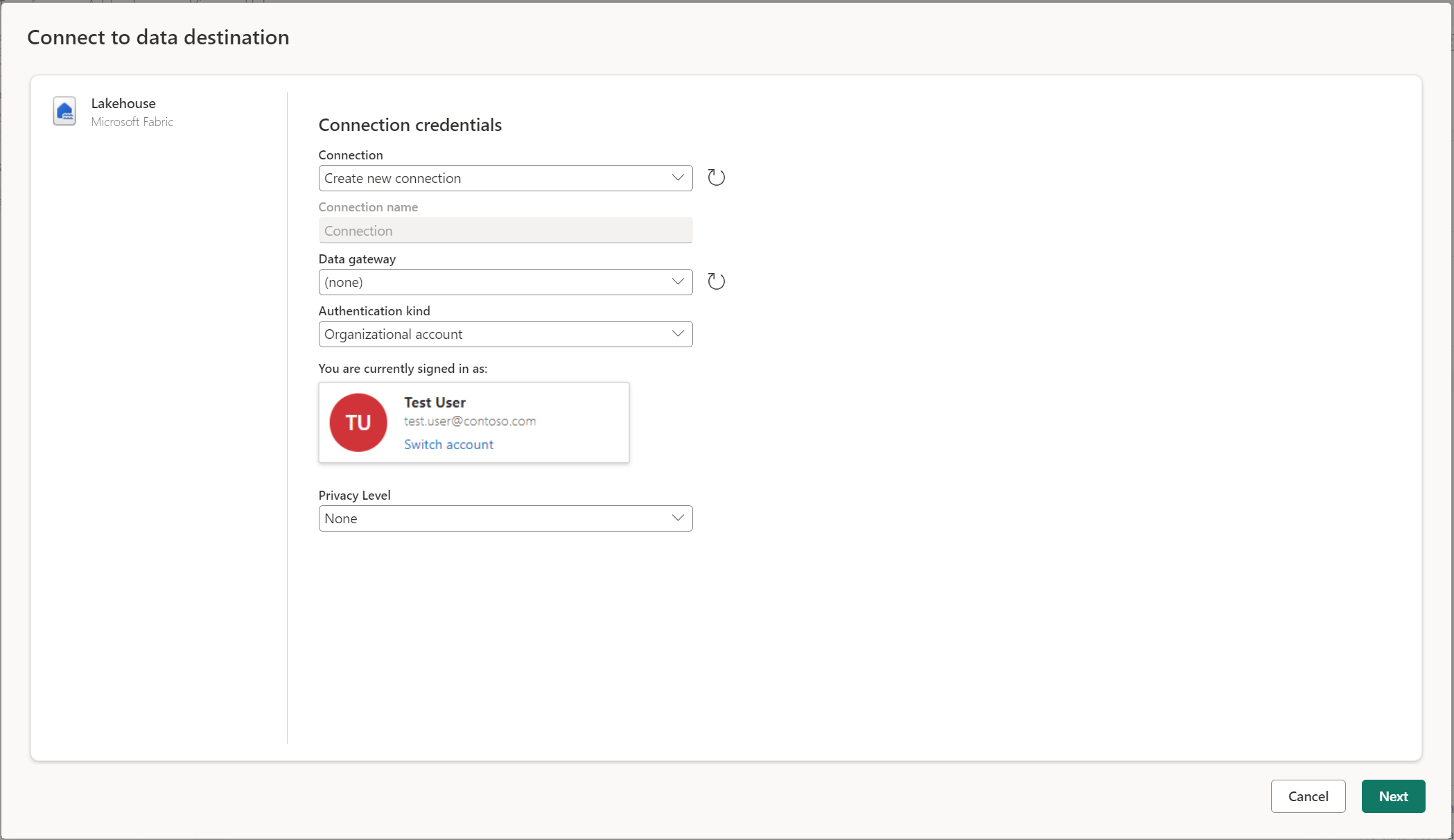
Connecting to the data destination is similar to connecting to a data source. Connections can be used for both reading and writing your data, given that you have the right permissions on the data source. You need to create a new connection or pick an existing connection, and then select Next.
Setup file based destinations
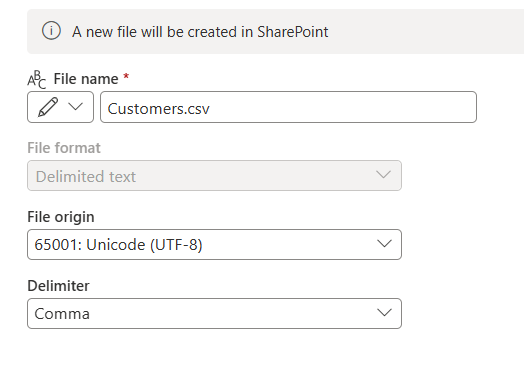
When you choose a file-based destination like SharePoint, you need to specify a few more settings. The following settings are required:
- File name: The name of the file that will be created in the destination. By default, the file name is the same as your query name.
- File format: The format of the file that will be created in the destination.
- File origin: The encoding that's used to create the file in the destination. By default, the file origin is set to UTF-8.
- File delimiter: The delimiter that will be used to create the file in the destination. By default, the file delimiter is set to Comma.
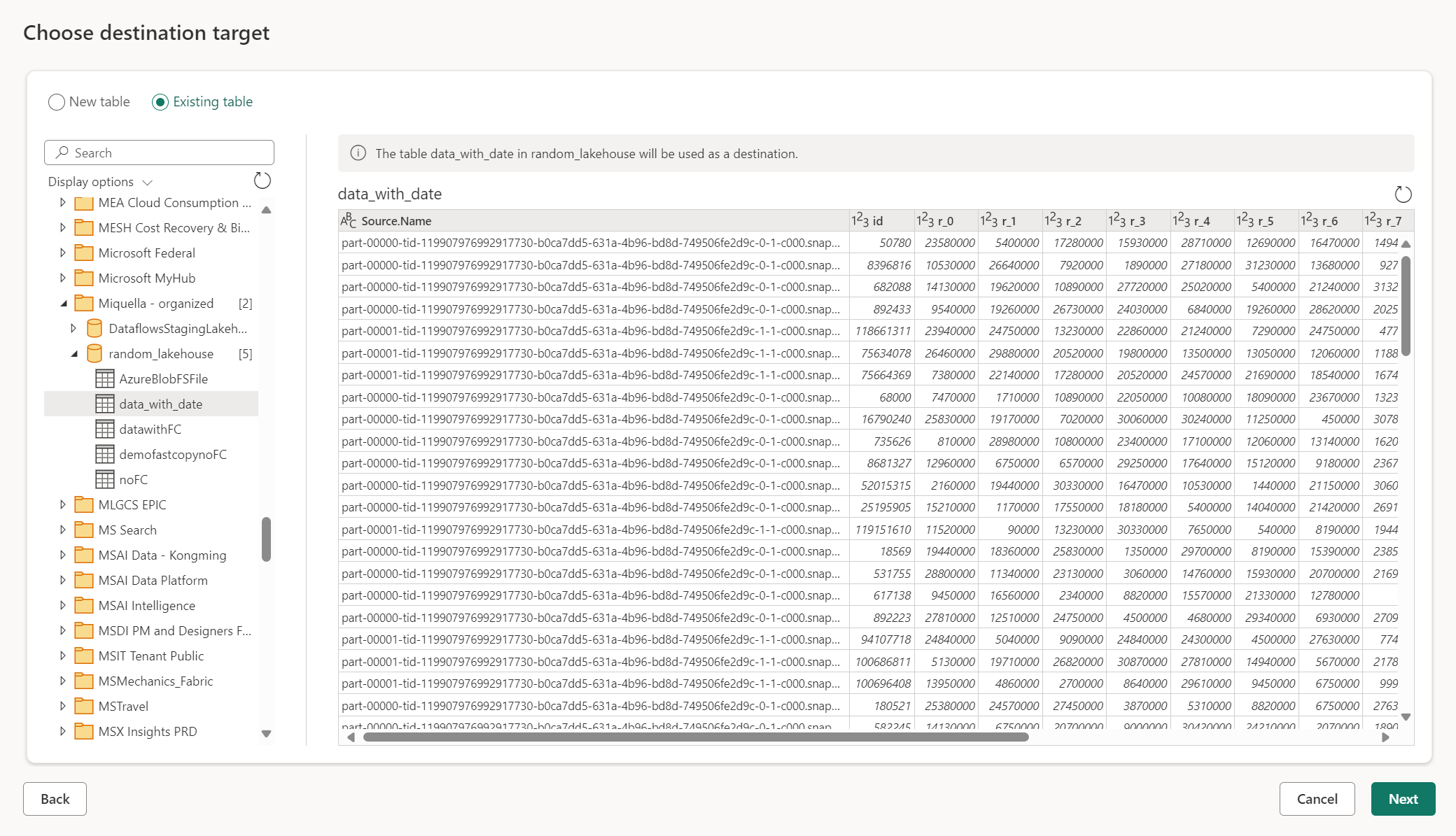
Create a new table or pick an existing table
When loading into your data destination, you can either create a new table or pick an existing table.
Create a new table
When you choose to create a new table, during the Dataflow Gen2 refresh a new table is created in your data destination. If the table gets deleted in the future by manually going into the destination, the dataflow recreates the table during the next dataflow refresh.
By default, your table name has the same name as your query name. If you have any invalid characters in your table name that the destination doesn't support, the table name is automatically adjusted. For example, many destinations don't support spaces or special characters.

Next, you must select the destination container. If you chose any of the Fabric data destinations, you could use the navigator to select the Fabric artifact you want to load your data into. For Azure destinations, you can either specify the database during connection creation, or select the database from the navigator experience.
Use an existing table
To choose an existing table, use the toggle at the top of the navigator. When choosing an existing table, you need to pick both the Fabric artifact/database and table using the navigator.
When you use an existing table, the table can't be recreated in any scenario. If you delete the table manually from the data destination, Dataflow Gen2 doesn't recreate the table on the next refresh.
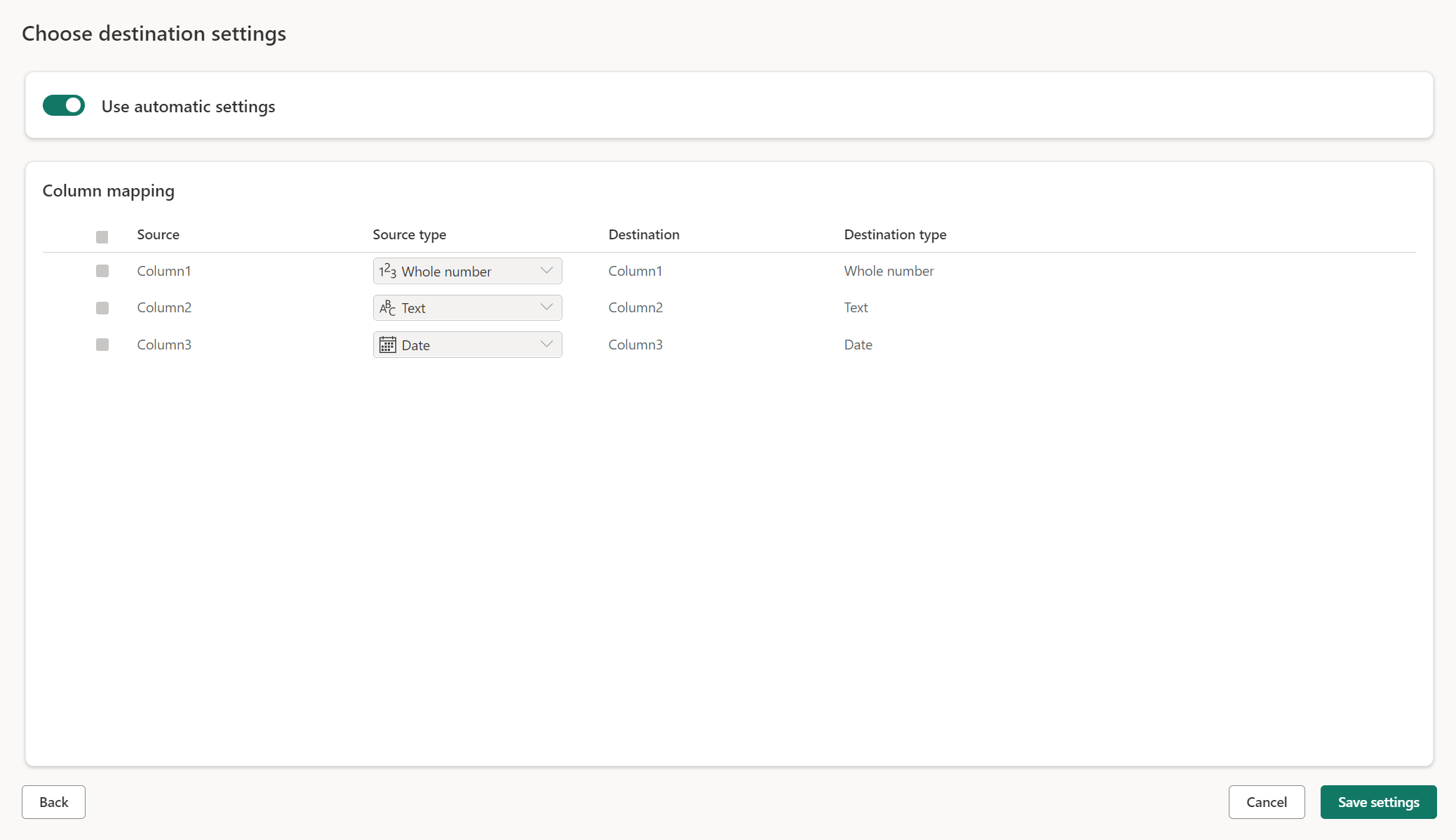
Managed settings for new tables
When you're loading into a new table, the automatic settings are on by default. If you use the automatic settings, Dataflow Gen2 manages the mapping for you. The automatic settings provide the following behavior:
Update method replace: Data is replaced at every dataflow refresh. Any data in the destination is removed. The data in the destination is replaced with the output data of the dataflow.
Managed mapping: Mapping is managed for you. When you need to make changes to your data/query to add another column or change a data type, mapping is automatically adjusted for this change when you republish your dataflow. You don't have to go into the data destination experience every time you make changes to your dataflow, allowing for easy schema changes when you republish the dataflow.
Drop and recreate table: To allow for these schema changes, on every dataflow refresh the table is dropped and recreated. Your dataflow refresh might cause the removal of relationships or measures that were added previously to your table.
Note
Currently, automatic settings are only supported for Lakehouse and Azure SQL database as data destination.
Manual settings
By untoggling Use automatic settings, you get full control over how to load your data into the data destination. You can make any changes to the column mapping by changing the source type or excluding any column that you don't need in your data destination.

Update methods
Most destinations support both append and replace as update methods. However, Fabric KQL databases and Azure Data Explorer don't support replace as an update method.
Replace: On every dataflow refresh, your data is dropped from the destination and replaced by the output data of the dataflow.
Append: On every dataflow refresh, the output data from the dataflow is appended to the existing data in the data destination table.
Schema options on publish
Schema options on publish only apply when the update method is replace. When you append data, changes to the schema aren't possible.
Dynamic schema: When choosing dynamic schema, you allow for schema changes in the data destination when you republish the dataflow. Because you aren't using managed mapping, you still need to update the column mapping in the dataflow destination wizard when you make any changes to your query. When a refresh detects a discrepancy between the destination schema and the expected schema, the table is dropped and then recreated to align with the expected schema. Your dataflow refresh might cause the removal of relationships or measures that were added previously to your table.
Fixed schema: When you choose fixed schema, schema changes aren't possible. When the dataflow gets refreshed, only the rows in the table are dropped and replaced with the output data from the dataflow. Any relationships or measures on the table stay intact. If you make any changes to your query in the dataflow, the dataflow publish fails if it detects that the query schema doesn't match the data destination schema. Use this setting when you don't plan to change the schema and have relationships or measure added to your destination table.
Note
When loading data into the warehouse, only fixed schema is supported.

Parameterization
Parameters are a core experience within Dataflow Gen2. Once a parameter is created or you use the "Always allow" setting, an input widget is made available to define the table or file name for your destination.
Note
Parameters in the data destination can also be applied directly through the M script created for the queries related to it. You can manually alter the script of your data destination queries to apply the parameters to meet your requirements. However, the user interface currently only supports parameterization for the table or file name field.
Supported data source types per destination
| Supported data types per storage location | DataflowStagingLakehouse | Azure DB (SQL) Output | Azure Data Explorer Output | Fabric Lakehouse (LH) Output | Fabric Warehouse (WH) Output | Fabric SQL Database (SQL) Output |
|---|---|---|---|---|---|---|
| Action | No | No | No | No | No | No |
| Any | No | No | No | No | No | No |
| Binary | No | No | No | No | No | No |
| Currency | Yes | Yes | Yes | Yes | No | Yes |
| DateTimeZone | Yes | Yes | Yes | No | No | Yes |
| Duration | No | No | Yes | No | No | No |
| Function | No | No | No | No | No | No |
| None | No | No | No | No | No | No |
| Null | No | No | No | No | No | No |
| Time | Yes | Yes | No | No | No | Yes |
| Type | No | No | No | No | No | No |
| Structured (List, Record, Table) | No | No | No | No | No | No |
When working with data types such as currency or percentage, we typically convert them to their decimal equivalents for most destinations. However, when reconnecting to these destinations and following the existing table path, you might encounter difficulties mapping, for example, currency to a decimal column. In such cases, try changing the data type in the editor to decimal, as this will facilitate easier mapping to the existing table and column.
Advanced topics
Using staging before loading to a destination
To enhance performance of query processing, staging can be used within Dataflows Gen2 to use Fabric compute to execute your queries.
When staging is enabled on your queries (the default behavior), your data is loaded into the staging location, which is an internal Lakehouse only accessible by dataflows itself.
Using staging locations can enhance performance in some cases in which folding the query to the SQL analytics endpoint is faster than in memory processing.
When you're loading data into the Lakehouse or other non-warehouse destinations, we by default disable the staging feature to improve performance. When you load data into the data destination, the data is directly written to the data destination without using staging. If you want to use staging for your query, you can enable it again.
To enable staging, right-click on the query and enable staging by selecting the Enable staging button. Your query then turns blue.

Loading data into the Warehouse
When you load data into the Warehouse, staging is required before the write operation to the data destination. This requirement improves performance. Currently, only loading into the same workspace as the dataflow is supported. Ensure staging is enabled for all queries that load into the warehouse.
When staging is disabled, and you choose Warehouse as the output destination, you get a warning to enable staging first before you can configure the data destination.

If you already have a warehouse as a destination and try to disable staging, a warning is displayed. You can either remove the warehouse as the destination or dismiss the staging action.

Vacuuming your Lakehouse data destination
When using Lakehouse as a destination for Dataflow Gen2 in Microsoft Fabric, it's crucial to perform regular maintenance to ensure optimal performance and efficient storage management. One essential maintenance task is vacuuming your data destination. This process helps to remove old files that are no longer referenced by the Delta table log, thereby optimizing storage costs and maintaining the integrity of your data.
Why vacuuming is important
- Storage Optimization: Over time, Delta tables accumulate old files that are no longer needed. Vacuuming helps to clean up these files, freeing up storage space and reducing costs.
- Performance Improvement: Removing unnecessary files can enhance query performance by reducing the number of files that need to be scanned during read operations.
- Data Integrity: Ensuring that only relevant files are retained helps maintain the integrity of your data, preventing potential issues with uncommitted files that could lead to reader failures or table corruption.
How to vacuum your data destination
To vacuum your Delta tables in Lakehouse, follow these steps:
- Navigate to your Lakehouse: From your Microsoft Fabric account, go to the desired Lakehouse.
- Access table maintenance: In the Lakehouse explorer, right-click on the table you want to maintain or use the ellipsis to access the contextual menu.
- Select maintenance options: Choose the Maintenance menu entry and select the Vacuum option.
- Run the vacuum command: Set the retention threshold (default is seven days) and execute the vacuum command by selecting Run now.
Best practices
- Retention period: Set a retention interval of at least seven days to ensure that old snapshots and uncommitted files aren't prematurely removed, which could disrupt concurrent table readers and writers.
- Regular maintenance: Schedule regular vacuuming as part of your data maintenance routine to keep your Delta tables optimized and ready for analytics.
By incorporating vacuuming into your data maintenance strategy, you can ensure that your Lakehouse destination remains efficient, cost-effective, and reliable for your dataflow operations.
For more detailed information on table maintenance in Lakehouse, refer to the Delta table maintenance documentation.
Nullable
In some cases when you have a nullable column, it gets detected by Power Query as non-nullable and when writing to the data destination, the column type is non-nullable. During refresh, the following error occurs:
E104100 Couldn't refresh entity because of an issue with the mashup document MashupException.Error: DataFormat.Error: Error in replacing table's content with new data in a version: #{0}., InnerException: We can't insert null data into a non-nullable column., Underlying error: We can't insert null data into a non-nullable column. Details: Reason = DataFormat.Error;Message = We can't insert null data into a non-nullable column.; Message.Format = we can't insert null data into a non-nullable column.
To force nullable columns, you can try the following steps:
Delete the table from the data destination.
Remove the data destination from the dataflow.
Go into the dataflow and update the data types by using the following Power Query code:
Table.TransformColumnTypes( #"PREVIOUS STEP", { {"COLLUMNNAME1", type nullable text}, {"COLLUMNNAME2", type nullable Int64.Type} } )Add the data destination.
Data types conversion and upscaling
In some cases the data type within the dataflow differs from what is supported in the data destination below are some default conversions we have put in place to ensure you are still able to get your data in the data destination:
| Destination | Dataflow Datatype | Destination Datatype |
|---|---|---|
| Fabric Warehouse | Int8.Type | Int16.Type |