Module 1: Create a pipeline with Data Factory
This module takes 10 minutes, ingesting raw data from the source store into the Bronze table of a data Lakehouse using the Copy activity in a pipeline.
The high-level steps in module 1 are as follows:
- Create a data pipeline.
- Use a Copy Activity in the pipeline to load sample data into a data Lakehouse.
Create a data pipeline
A Microsoft Fabric tenant account with an active subscription is required. Create a free account.
Make sure you have a Microsoft Fabric enabled Workspace: Create a workspace.
Sign into Power BI.
Select the default Power BI icon at the bottom left of the screen, and switch to the Data Factory experience.
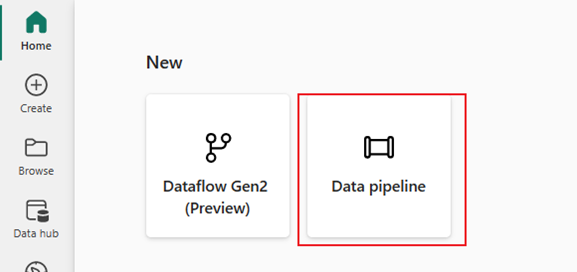
Select Data pipeline and provide a pipeline name. Then select Create.
Use a Copy activity in the pipeline to load sample data to a data Lakehouse
Step 1: Use the copy assistant to configure a copy activity.
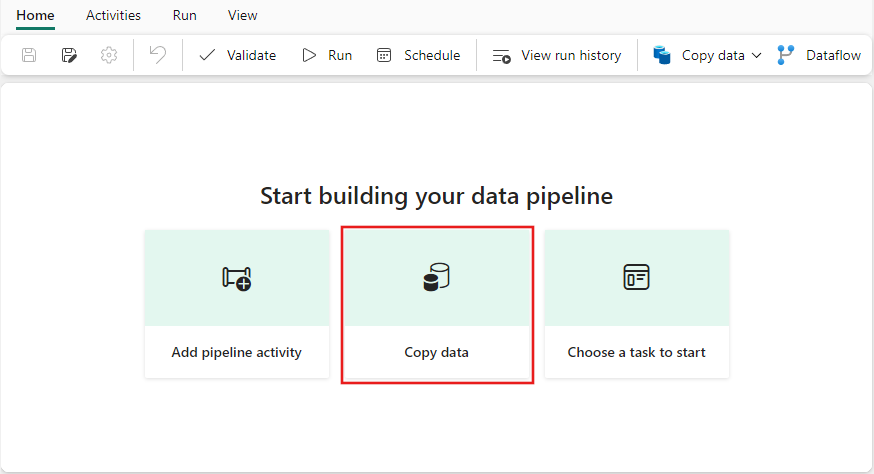
Select Copy data to open the copy assistant tool.
Step 2: Configure your settings in the copy assistant.
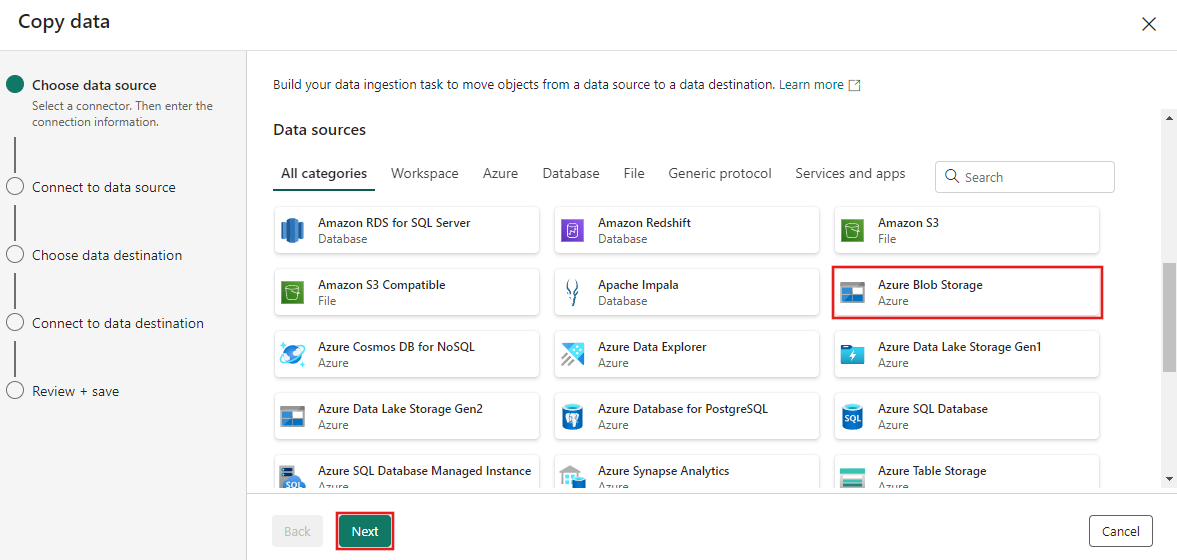
The Copy data dialog is displayed with the first step, Choose data source, highlighted. Scroll down if necessary to the Data sources section, and select the Azure Blob Storage data source type. Then select Next.
In the next step, select Create new connection and then provide the URL for the blob storage hosting the sample data provided for this tutorial, at
https://nyctaxisample.blob.core.windows.net/sample. The authentication kind is Anonymous. Select Next after providing the URL.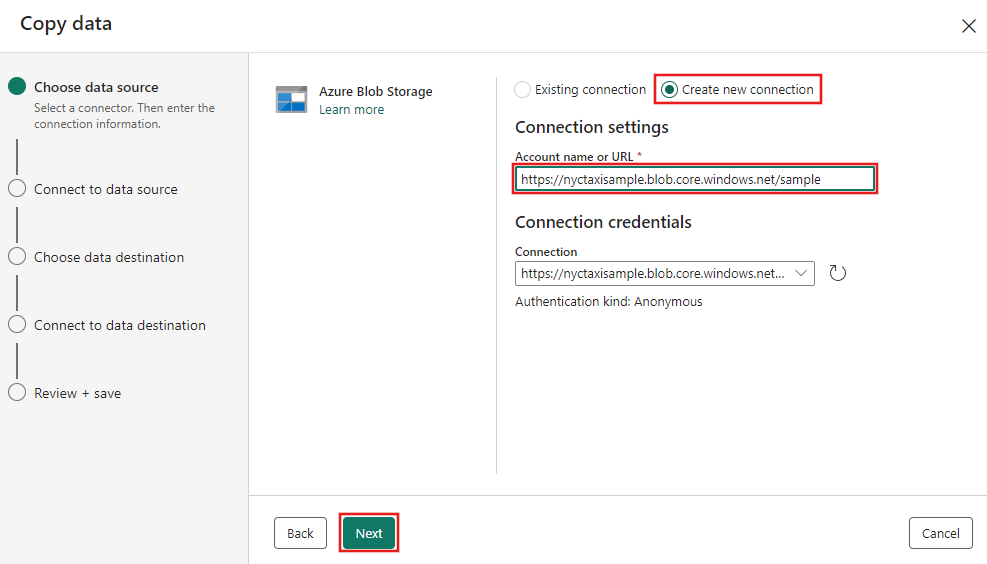
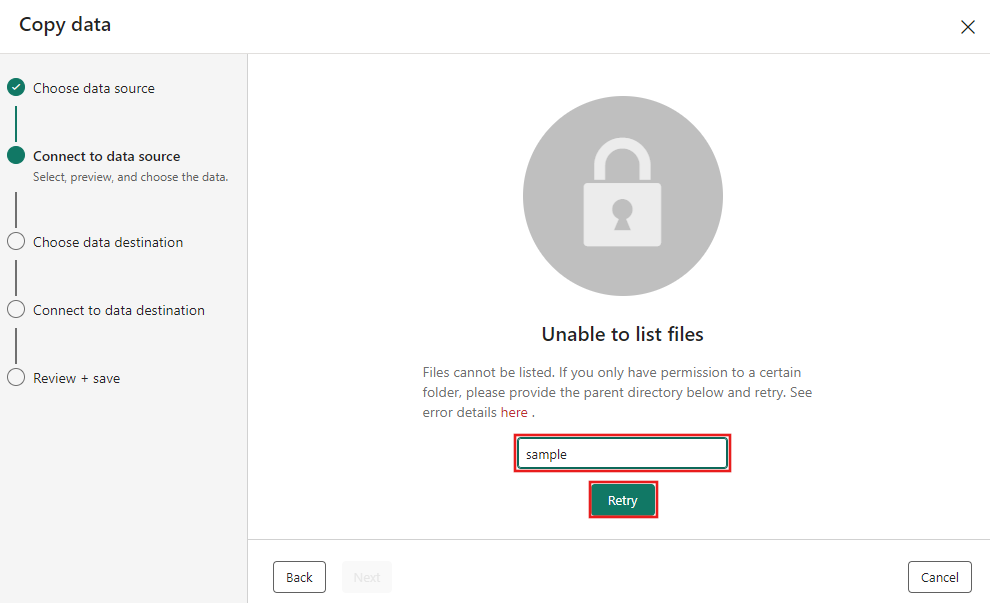
The Connect to data source step appears, and initially, you see an error Unable to list files, because permissions have only been granted to the sample folder in the blob storage. Provide the folder name, sample, and select Retry.
Note
The blob storage folder is case sensitive and should be in all lower case.
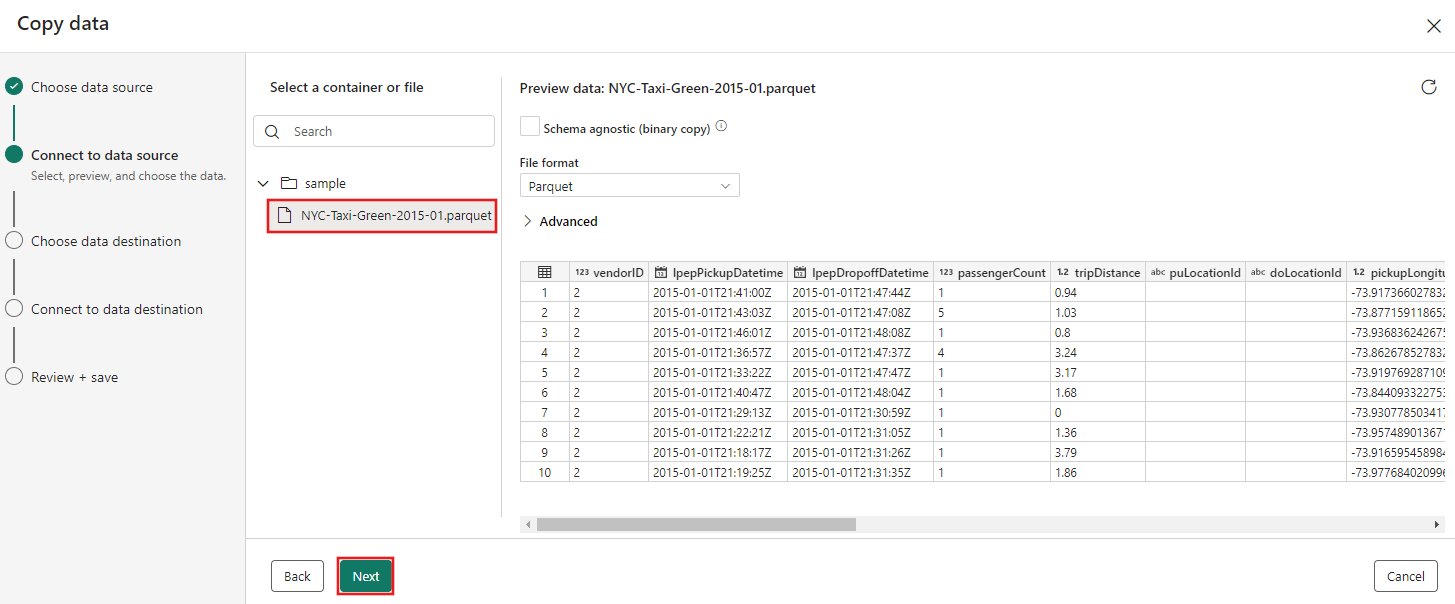
The blob storage browser appears next. Select the NYC-Taxi-Green-2015-01.parquet file, and wait for the data preview to appear. Then select Next.
For the Choose data destination step of the copy assistant, select Lakehouse and then Next.
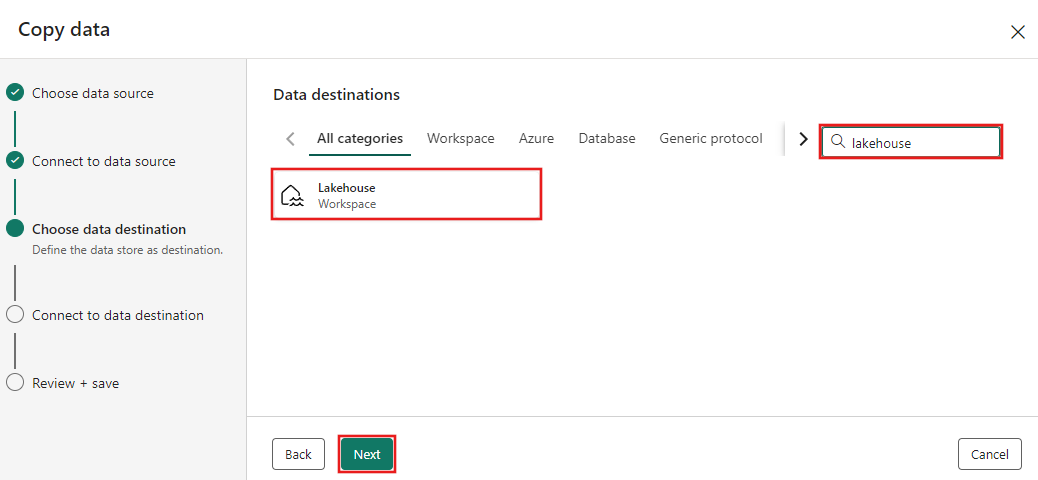
Select Create new Lakehouse on the data destination configuration page that appears, and enter a name for the new Lakehouse. Then select Next again.
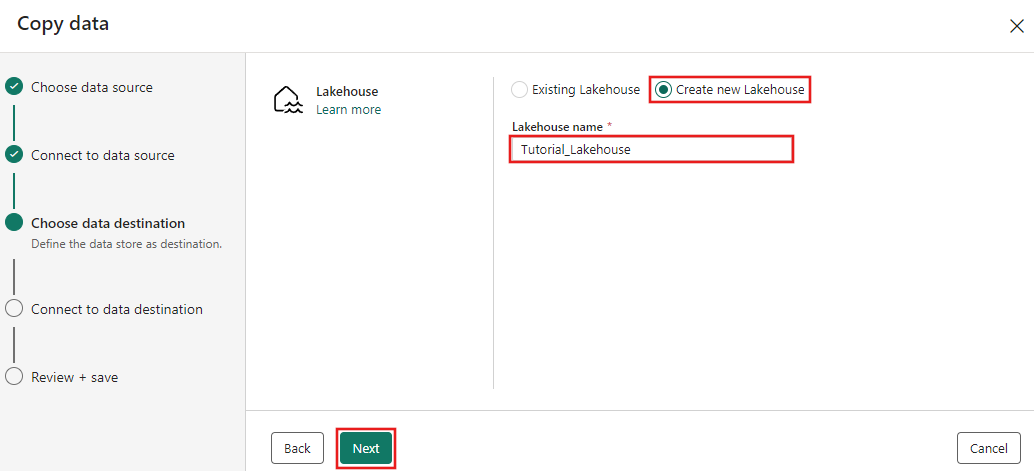
Now configure the details of your Lakehouse destination on the Select and map to folder path or table. page. Select Tables for the Root folder, provide a table name, and choose the Overwrite action. Don't check the Enable partition checkbox that appears after you select the Overwrite table action.
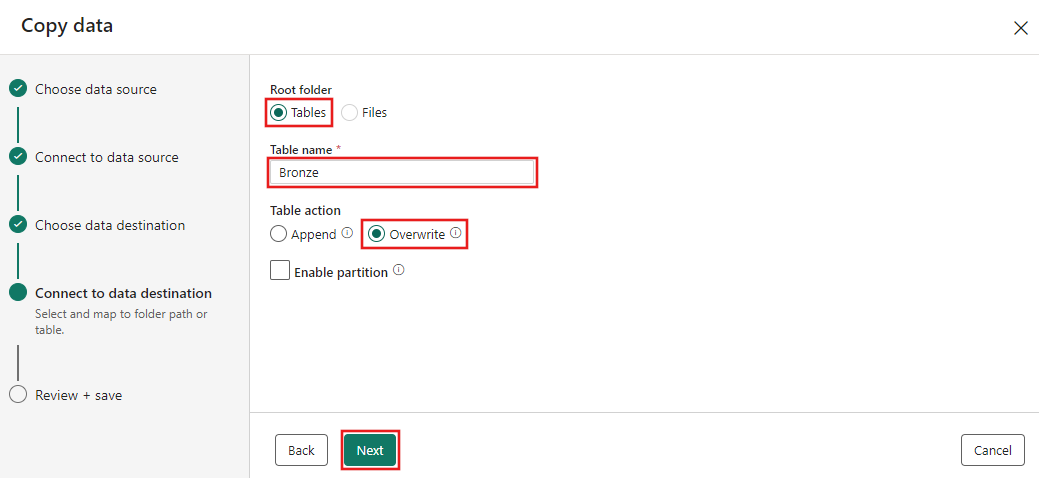
Finally, on the Review + save page of the copy data assistant, review the configuration. For this tutorial, uncheck the Start data transfer immediately checkbox, since we run the activity manually in the next step. Then select OK.
Step 3: Run and view the results of your Copy activity.
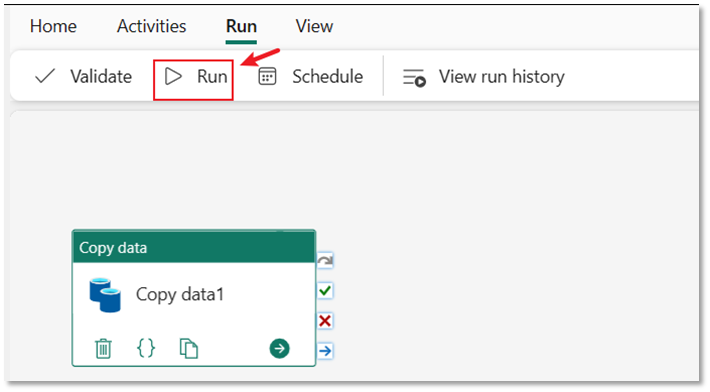
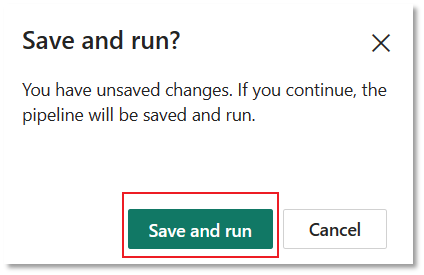
Select the Run tab in the pipeline editor. Then select the Run button, and then Save and run at the prompt, to run the Copy activity.
You can monitor the run and check the results on the Output tab below the pipeline canvas. Select the run details button (the "glasses" icon that appears when you hover over the running pipeline run) to view the run details.
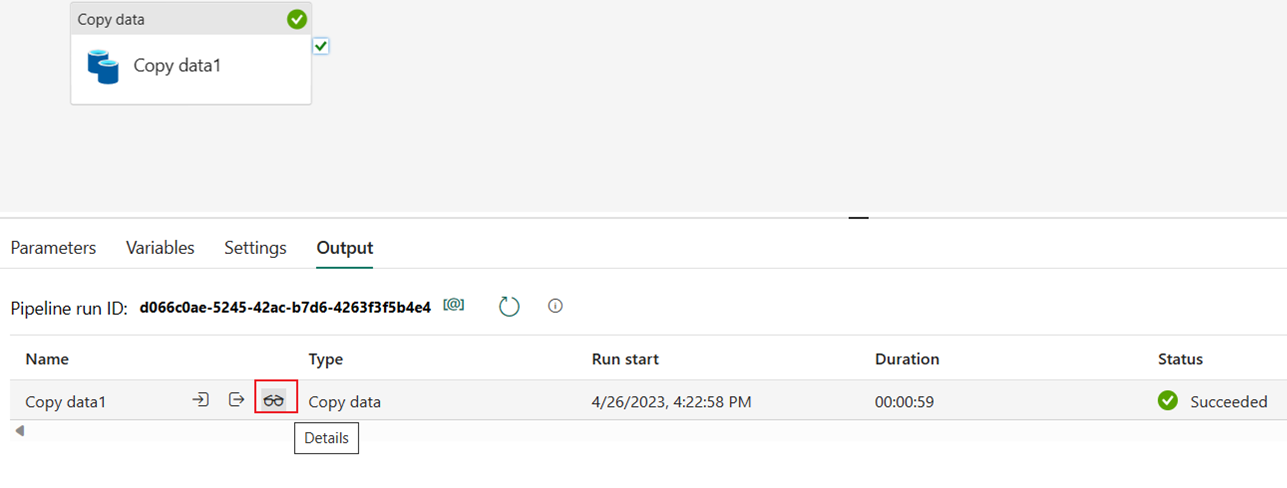
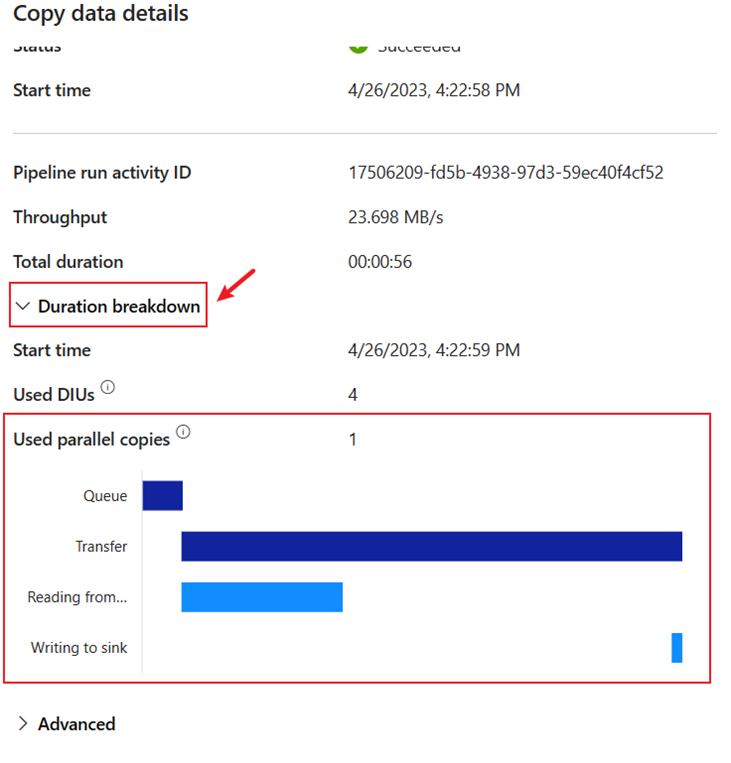
The run details show 1,508,501 rows read and written.
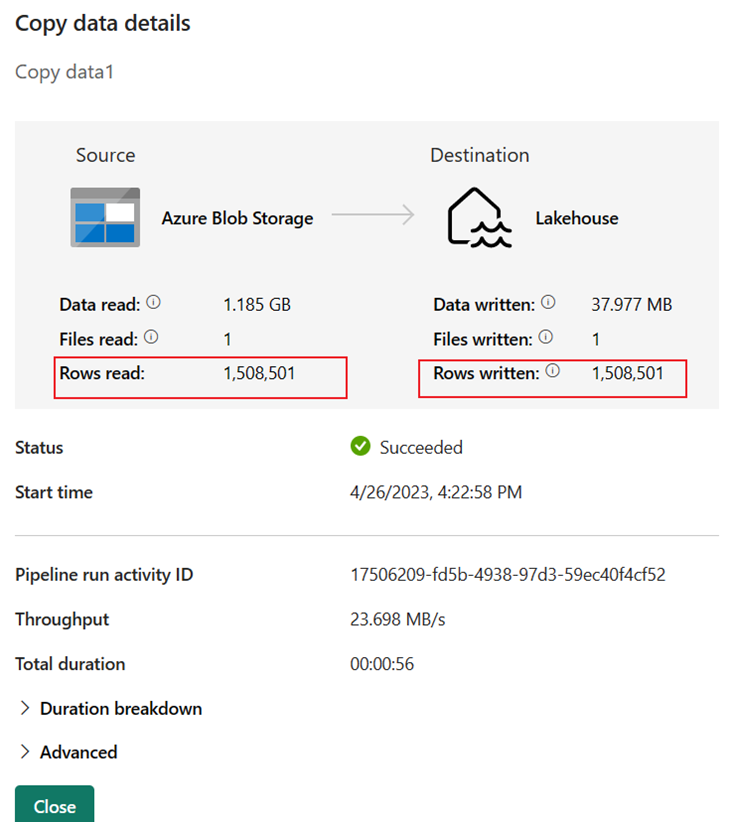
Expand the Duration breakdown section to see the duration of each stage of the Copy activity. After reviewing the copy details, select Close.
Related content
In this first module to our end-to-end tutorial for your first data integration using Data Factory in Microsoft Fabric, you learned how to:
- Create a data pipeline.
- Add a Copy activity to your pipeline.
- Use sample data and create a data Lakehouse to store the data to a new table.
- Run the pipeline and view its details and duration breakdown.
Continue to the next section now to create your dataflow.