Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
In this tutorial, you configure a Fabric mirrored database from an existing Azure Cosmos DB for NoSQL account.
Mirroring incrementally replicates Azure Cosmos DB data into Fabric OneLake in near real-time, without affecting the performance of transactional workloads or consuming Request Units (RUs). You can build Power BI reports directly on the data in OneLake, using DirectLake mode. You can run ad hoc queries in SQL or Spark, build data models using notebooks and use built-in Copilot and advanced AI capabilities in Fabric to analyze the data.
Prerequisites
- An existing Azure Cosmos DB for NoSQL account.
- If you don't have an Azure subscription, Try Azure Cosmos DB for NoSQL free.
- If you have an existing Azure subscription, create a new Azure Cosmos DB for NoSQL account.
- An existing Fabric capacity. If you don't have an existing capacity, start a Fabric trial. Mirroring might not be available in some Fabric regions. For more information, see supported regions.
Tip
It's recommended to use a test or development copy of your existing Azure Cosmos DB data that can be recovered quickly from a backup.
Configure your Azure Cosmos DB account
First, ensure that the source Azure Cosmos DB account is correctly configured to use with Fabric mirroring.
Navigate to your Azure Cosmos DB account in the Azure portal.
Ensure that continuous backup is enabled. If not enabled, follow the guide at migrate an existing Azure Cosmos DB account to continuous backup to enable continuous backup. This feature might not be available in some scenarios. For more information, see database and account limitations.
If your Azure Cosmos DB account uses virtual networks or private endpoints, you need to configure Network ACL Bypass to allow your Fabric workspace to access the account. For more information, see Configure private networks for Microsoft Fabric mirrored databases from Azure Cosmos DB. If your account is configured for public network access for all networks, you can skip to the next section.
Create a mirrored database
Now, create a mirrored database that is the target of the replicated data. For more information, see What to expect from mirroring.
Navigate to the Fabric portal home.
Open an existing workspace or create a new workspace.
In the navigation menu, select Create.
Select Create, locate the Data Warehouse section, and then select Mirrored Azure Cosmos DB.
Provide a name for the mirrored database and then select Create.
Connect to the source database
Next, connect the source database to the mirrored database.
In the New connection section, select Azure Cosmos DB for NoSQL.
Provide credentials for the Azure Cosmos DB for NoSQL account including these items:
Account credentials Value Azure Cosmos DB endpoint URL endpoint for the source account. Connection name Unique name for the connection. Authentication kind Select Account key or Organizational account. Account Key Read-write key for the source account. Organizational account Access token from Microsoft Entra ID. 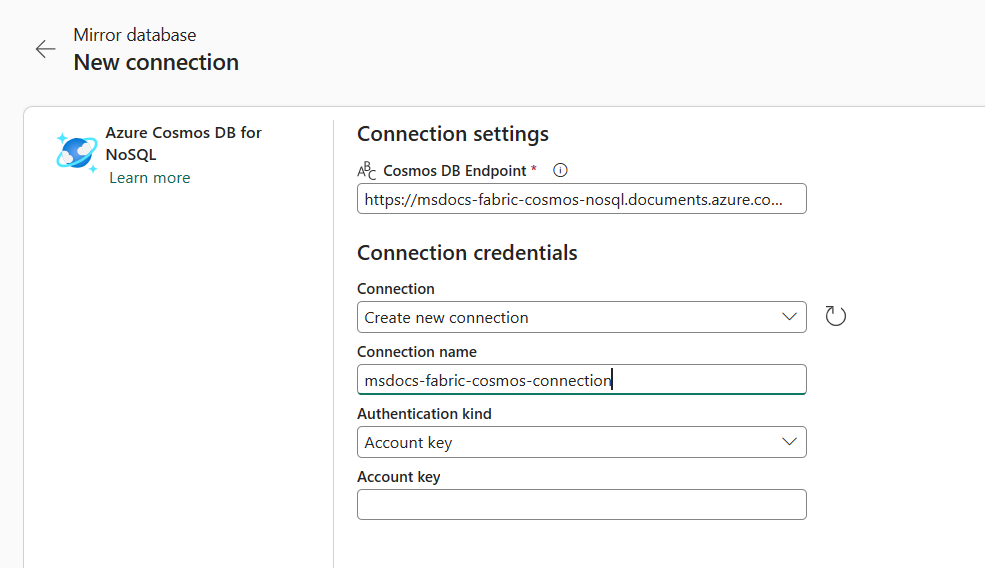
Note
For Microsoft Entra ID authentication, the following RBAC permissions are required:
Microsoft.DocumentDB/databaseAccounts/readMetadataMicrosoft.DocumentDB/databaseAccounts/readAnalytics
For more information, see data plane role-based access control documentation.
For an example of a script to auto-apply a custom role-based access control role, see
rbac-cosmos-mirror.shon azure-samples/azure-cli-samples.Select Connect. Then, select a database to mirror. Optionally, select specific containers to mirror.

Start mirroring process
Select Mirror database. Mirroring now begins.
Wait two to five minutes. Then, select Monitor replication to see the status of the replication action.
After a few minutes, the status should change to Running, which indicates that the containers are being synchronized.
Tip
If you can't find the containers and the corresponding replication status, wait a few seconds and then refresh the pane. In rare cases, you might receive transient error messages. You can safely ignore them and continue to refresh.
When mirroring finishes the initial copying of the containers, a date appears in the last refresh column. If data was successfully replicated, the total rows column would contain the number of items replicated.
Monitor Fabric Mirroring
Now that your data is up and running, there are various analytics scenarios available across all of Fabric.
Once Fabric Mirroring is configured, you're automatically navigated to the Replication Status pane.
Here, monitor the current state of replication. For more information and details on the replication states, see Monitor Fabric mirrored database replication.
Query the source database from Fabric
Use the Fabric portal to explore the data that already exists in your Azure Cosmos DB account, querying your source Cosmos DB database.
Navigate to the mirrored database in the Fabric portal.
Select View, then Source database. This action opens the Azure Cosmos DB data explorer with a read-only view of the source database.
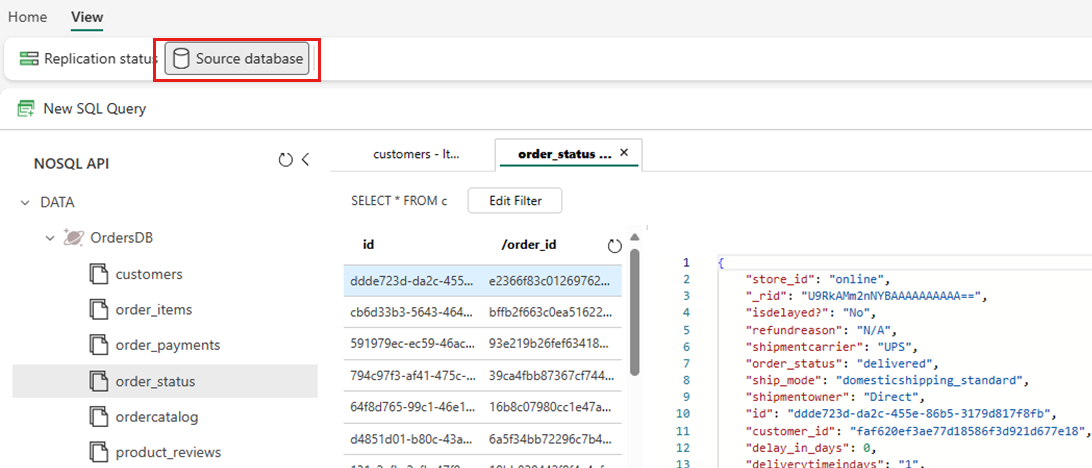
Select a container, then open the context menu and select New SQL query.
Run any query. For example, use
SELECT COUNT(1) FROM containerto count the number of items in the container.Note
All the reads on the source database are routed to Azure and consume Request Units (RUs) allocated on the account.

Analyze the target mirrored database
Now, use T-SQL to query your NoSQL data that is now stored in Fabric OneLake.
Navigate to the mirrored database in the Fabric portal.
Switch from Mirrored Azure Cosmos DB to SQL analytics endpoint.
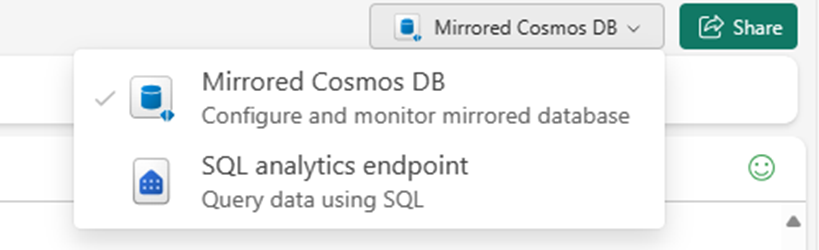
Each container in the source database should be represented in the SQL analytics endpoint as a warehouse table.
Select any table, open the context menu, then select New SQL Query, and finally select Select Top 100.
The query executes and returns 100 records in the selected table.
Open the context menu for the same table and select New SQL Query. Write an example query that uses aggregates like
SUM,COUNT,MIN, orMAX. Join multiple tables in the warehouse to execute the query across multiple containers.Note
For example, this query would execute across multiple containers:
SELECT d.[product_category_name], t.[order_status], c.[customer_country], s.[seller_state], p.[payment_type], sum(o.[price]) as price, sum(o.[freight_value]) freight_value FROM [dbo].[products] p INNER JOIN [dbo].[OrdersDB_order_payments] p on o.[order_id] = p.[order_id] INNER JOIN [dbo].[OrdersDB_order_status] t ON o.[order_id] = t.[order_id] INNER JOIN [dbo].[OrdersDB_customers] c on t.[customer_id] = c.[customer_id] INNER JOIN [dbo].[OrdersDB_productdirectory] d ON o.product_id = d.product_id INNER JOIN [dbo].[OrdersDB_sellers] s on o.seller_id = s.seller_id GROUP BY d.[product_category_name], t.[order_status], c.[customer_country], s.[seller_state], p.[payment_type]This example assumes the name of your table and columns. Use your own table and columns when writing your SQL query.
Select the query and then select Save as view. Give the view a unique name. You can access this view at any time from the Fabric portal.
Return back to the mirrored database in the Fabric portal.
Select New visual query. Use the query editor to build complex queries.
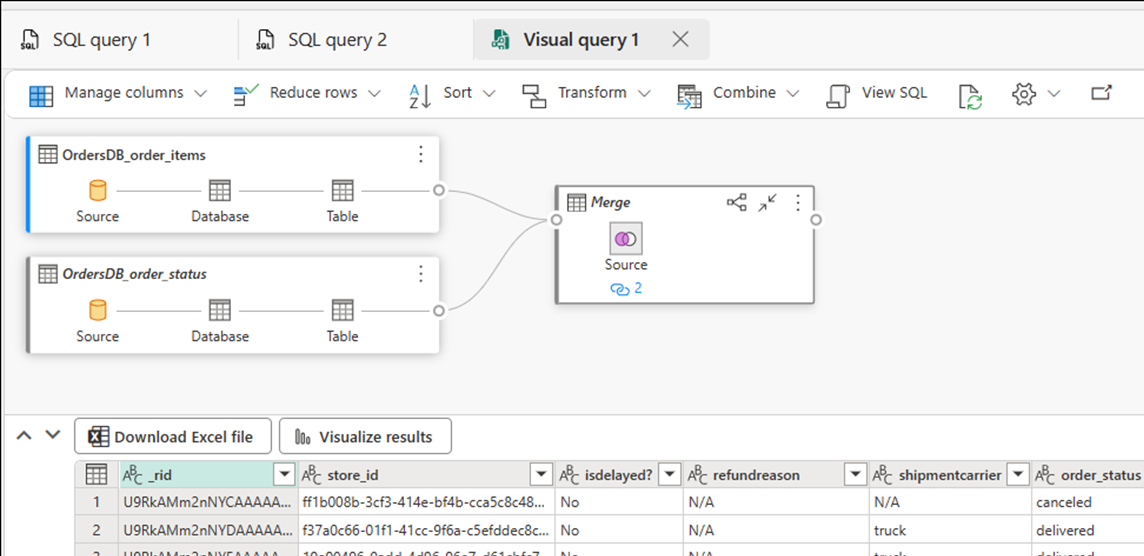


Build BI reports on the SQL queries or views
- Select the query or view and then select Explore this data (preview). This action explores the query in Power BI directly using Direct Lake on OneLake mirrored data.
- Edit the charts as needed and save the report.
Tip
You can also optionally use Copilot or other enhancements to build dashboards and reports without any further data movement.
More examples
Learn more about how to access and query mirrored Azure Cosmos DB data in Fabric:
- How to: Query nested data in Microsoft Fabric mirrored databases from Azure Cosmos DB
- How to: Access mirrored Azure Cosmos DB data in Lakehouse and notebooks from Microsoft Fabric
- How to: Join mirrored Azure Cosmos DB data with other mirrored databases in Microsoft Fabric