Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
In this guide, you will:
Upload data to OneLake with the OneLake file explorer.
Use a Fabric notebook to read data on OneLake and write back as a Delta table.
Analyze and transform data with Spark using a Fabric notebook.
Query one copy of data on OneLake with SQL.
Prerequisites
Before you begin, you must:
Download and install OneLake file explorer.
Create a workspace with a Lakehouse item.
Download the WideWorldImportersDW dataset. You can use Azure Storage Explorer to connect to
https://fabrictutorialdata.blob.core.windows.net/sampledata/WideWorldImportersDW/csv/full/dimension_cityand download the set of csv files. Or you can use your own csv data and update the details as required.
Upload data
In this section, you upload test data into your lakehouse using OneLake file explorer.
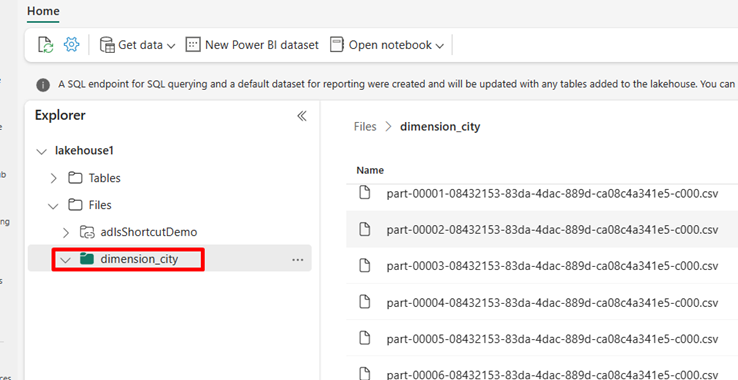
In OneLake file explorer, navigate to your lakehouse and create a subdirectory named
dimension_cityunder the/Filesdirectory.
Copy your sample csv files to the OneLake directory
/Files/dimension_cityusing OneLake file explorer.
Navigate to your lakehouse in the Power BI or Fabric service and view your files.

Create a Delta table
In this section, you convert the unmanaged CSV files into a managed table using Delta format.
Note
Always create, load, or create a shortcut to Delta-Parquet data directly under the Tables section of the lakehouse. Don't nest your tables in subfolders under the Tables section. The lakehouse doesn't recognize subfolders as tables and labels them as Unidentified.
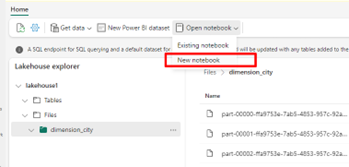
In your lakehouse, select Open notebook, then New notebook to create a notebook.
Using the Fabric notebook, convert the CSV files to Delta format. The following code snippet reads data from user created directory
/Files/dimension_cityand converts it to a Delta tabledim_city.Copy the code snippet into the notebook cell editor. Replace the placeholders with your own workspace details, then select Run cell or Run all.
import os from pyspark.sql.types import * for filename in os.listdir("/lakehouse/default/Files/dimension_city"): df=spark.read.format('csv').options(header="true",inferSchema="true").load("abfss://<YOUR_WORKSPACE_NAME>@onelake.dfs.fabric.microsoft.com/<YOUR_LAKEHOUSE_NAME>.Lakehouse/Files/dimension_city/"+filename,on_bad_lines="skip") df.write.mode("overwrite").format("delta").save("Tables/dim_city")Tip
You can retrieve the full ABFS path to your directory by right-clicking on the directory name and selecting Copy ABFS path.
To see your new table, refresh your view of the
/Tablesdirectory. Select more options (...) next to the Tables directory, then select Refresh.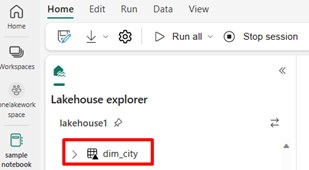
Query and modify data
In this section, you use a Fabric notebook to interact with the data in your table.
Query your table with SparkSQL in the same Fabric notebook.
%%sql SELECT * from <LAKEHOUSE_NAME>.dim_city LIMIT 10;Modify the Delta table by adding a new column named newColumn with data type integer. Set the value of 9 for all the records for this newly added column.
%%sql ALTER TABLE <LAKEHOUSE_NAME>.dim_city ADD COLUMN newColumn int; UPDATE <LAKEHOUSE_NAME>.dim_city SET newColumn = 9; SELECT City,newColumn FROM <LAKEHOUSE_NAME>.dim_city LIMIT 10;
You can also access any Delta table on OneLake via a SQL analytics endpoint. A SQL analytics endpoint references the same physical copy of Delta table on OneLake and offers the T-SQL experience.
Navigate to your lakehouse, then select Lakehouse > SQL analytics endpoint from the drop-down menu.
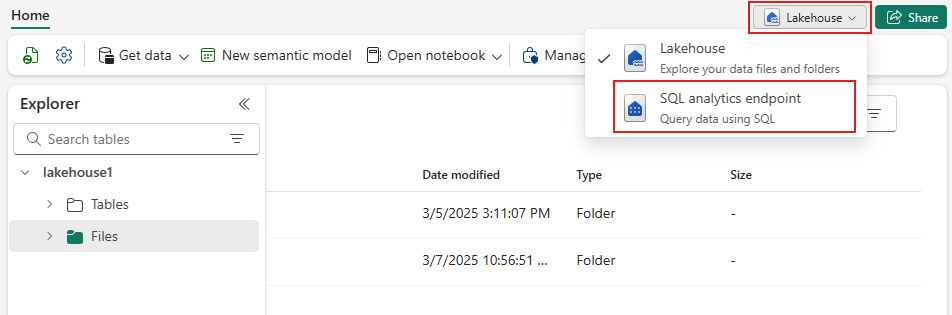
Select New SQL Query to query the table using T-SQL.
Copy and paste the following code into the query editor, then select Run.
SELECT TOP (100) * FROM [<LAKEHOUSE_NAME>].[dbo].[dim_city];