Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
[This article is prerelease documentation and is subject to change.]
Orchestrate multimodal AI insights (preview) enables on-demand generation and integration of AI enrichments from healthcare AI models and APIs. To learn more about the capability and understand how to deploy and configure it, see:
- Overview of orchestrate multimodal AI insights (preview)
- Deploy and configure orchestrate multimodal AI insights (preview)
Understand the orchestration mechanism
The enrichment execution notebooks for Text Analytics for health, MedImageInsight, and MedImageParse facilitate ease of use for the available healthcare models. Each model execution notebook:
Defines the enrichment view and enrichment definition based on the model configuration and input mappings. The input data for each model is specified, which is why the healthcare data transformations are a prerequisite. You can use SQL views to specify which data, like tables or images, should be used as the data source.
Specifies the model processor and transformer. The model processor is used to call the model API. The transformer is used to produce the standardized output and save the output in the bronze lakehouse in the Ingest folder. The processor and transformer are specific to the model being used.
After you run the enrichment execution, the integration pipeline ingests the model outputs into the lakehouse.
Run the model execution
Note
The notebooks are preconfigured to run with Spark runtime version 1.2 (Spark 3.4, Delta 2.4) by default. Ensure you maintain this setting at the environment level. For more information, see Reset Spark runtime version in the Fabric workspace.
Select which model you want to use, and then deploy it from its reference link:
- Text Analytics for Health: Clinical data and clinical data transformations.
- MedImageInsight: Embedding model is imaging data and DICOM data transformations.
- MedImageParse: Prompted segmentation model is imaging data and DICOM data transformations.
Make sure you have the proper data type for your chosen model and run the appropriate data transformations as specified. You can use the sample data deployed with healthcare data solutions with any of these models.
For more information about these models, see Azure AI Foundry. When you deploy the model, add the endpoint and key to your key vault.
Text Analytics for health enrichment execution
Install the healthcare data solutions sample data. Copy the sample data folder 51KSyntheticPatients from
Files\SampleData\Clinical\FHIR-NDJSON\FHIR-HDStoFiles\Ingest\Clinical\FHIR-NDJSON\FHIR-HDS.Run the healthcare#_msft_clinical_data_foundation_ingestion pipeline.
After the pipeline executes successfully, validate that the DocumentReference and DocumentReferenceContent tables in the silver lakehouse populate with data.
FHIR resource enrichments (optional): Text Analytics for health enrichments are stored in the text and object enrichment tables. If you wish to generate FHIR resources, you must specify the FHIR resource configuration:
In the healthcare#_msft_ai_enrichments_ta4h_execution notebook, edit the fifth cell to change the
FHIR_RESOURCE_CONFIGparameter and set up the FHIR resources to extract during notebook execution. By default, the FHIR resources Observation and Condition are included. For the list of supported resources, review the FHIR Domain Resource column.Go to the bronze ingestion notebook healthcare#_msft_ai_enrichments_bronze_ingestion and update the inline parameter to enable FHIR resource extraction. Set the
extract_fhir_resources_from_object_enrichmentsparameter value totrue.
Select the healthcare#_msft_ai_enrichments_ta4h_execution notebook.
Go to cell 10 to define the Text Analytics for health API settings in the notebook and unlock the cell for editing.

Update
TA4H_API_KEY_SECRET_NAME.Update
TA4H_API_ENDPOINT.Select Run all. All notebook cells must execute without errors.
Verify that NDJSON files are generated in the following bronze lakehouse folders:
Files\Ingest\AIEnrichments\Text\Fabric.HDSFiles\Ingest\AIEnrichments\Object\Fabric.HDS

MedImageInsight enrichment execution
Deploy and configure DICOM data transformation capability.
Move the 340ImagingStudies folder from
Files\SampleData\Imaging\DICOM\DICOM-HDStoFiles\Ingest\Imaging\DICOM\DICOM-HDS.Run the msft_imaging_with_clinical_foundation_ingestion pipeline.
After the pipeline executes successfully, validate that the ImagingMetastore table populates with data.
Run the MedImageInsight notebook:
Select the msft_ai_enrichments_medimage_insight_execution notebook.
Go to the MedImageInsights API configuration cell in the notebook and make sure you're in Develop mode to unlock the cell.
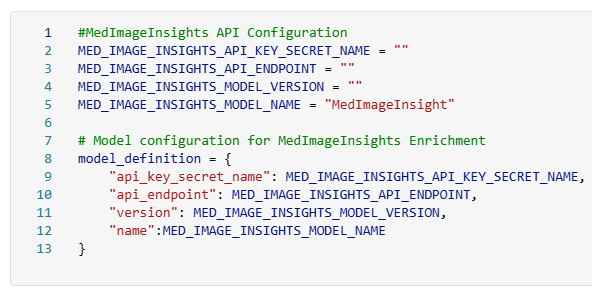
Update the
MED_IMAGE_INSIGHTS_API_KEY_SECRET_NAMEconstant.Update the
MED_IMAGE_INSIGHTS_API_ENDPOINTconstant.Set the
MED_IMAGE_INSIGHTS_MODEL_VERSIONconstant.Select Run all. All notebook cells must execute without errors.
Verify that NDJSON files are generated in the bronze lakehouse folder
Files\Ingest\AIEnrichments\Embedding\Fabric.HDS.

MedImageParse enrichment execution
Deploy and configure DICOM data transformation capability.
Move the 340ImagingStudies folder from
Files\SampleData\Imaging\DICOM\DICOM-HDStoFiles\Ingest\Imaging\DICOM\DICOM-HDS.Run the msft_imaging_with_clinical_foundation_ingestion pipeline.
After the pipeline executes successfully, validate that the ImagingMetastore table populates with data.
Run the MedImageParse notebook:
Select the msft_ai_enrichments_medimage_parse_execution notebook.
Go to cell nine in the notebook for the API configuration. Make sure you're in Develop mode to unlock the cell.
Update the
MED_IMAGE_PARSE_API_KEY_SECRET_NAMEconstant.Update the
MED_IMAGE_PARSE_API_ENDPOINTconstant.Set the
MED_IMAGE_PARSE_MODEL_VERSIONconstant.Set the
MED_IMAGE_PARSE_SYSTEM_INSTRUCTIONSstring. This string contains multiple sentences separated by the special character&.For example, "tumor core & enhancing tumor & nonenhancing tumor". In this case, there are three sentences. So, the output consists of three images with segmentation masks. To begin with, you can set the instructions as "neoplastic cells in breast pathology & inflammatory cells".
Select Run all. All notebook cells must execute without errors.
Verify that NDJSON files are generated in the bronze lakehouse folder
Files\Ingest\AIEnrichments\Segmentation_2D\Fabric.HDS.
Run the integration pipeline
Make sure one or more model enrichment execution notebooks successfully ran from the previous steps. The bronze lakehouse Ingest folder should have data before you proceed.
In your workspace, open the healthcare#_msft_ai_enrichments_ingestion pipeline, and select Run.

Validate data in the bronze lakehouse
Open the bronze lakehouse.
Load the AIEnrichments table:
If you don't see any data in the table after running the integration pipeline, know that it could take up to five minutes for the data to appear. Try refreshing the table after five minutes.
You should see a list of rows. The
typescolumn in the table is based on the use case you ran previously.Use case Types Text Analytics for health Produces text and object enrichments MedImageInsight Produces embedding enrichments MedImageParse Produces segmentation_2D enrichments
Depending on which model execution notebook you chose, confirm that each row has all the columns populated:
- The
datacolumn should contain the full data content of the streamed JSON file (or the full line in an NDJSON file). - The
file_pathshould contain a path to the file in the landing zone (Process folder). - The
typecolumn is based on the model you ran. - The
patient_idcolumn should have data in all records.
- The
Validate data in the silver lakehouse
Open the silver lakehouse and refresh the tables list.
You should find these new tables:
- TextEnrichments
- ObjectEnrichments
- EmbeddingEnrichments
- Segmentation_2DEnrichments
- Segmentation_3DEnrichments
Depending on which model execution notebook you ran previously, the data goes into one or more of those five tables.
Check each table schema:
All tables share a common set of columns in addition to their own columns.
Common columns (should exist in every table):
- unique_id
- model_name
- model_version
- patient_id
- enrichment_generation_id
- enrichment_definition_id
- metadata
- enrichment_context_id
- confidence_score
- msftModifiedDateTime
- msftCreatedDateTime
TextEnrichments columns:
- value
- domain
- reasoning
- evidence
- terminology
ObjectEnrichment columns:
- value
- type
- reasoning
- evidence
EmbeddingEnrichments columns:
- vector
Segmentation_2DEnrichments columns:
- height
- width
- background
- segmentation_metadata
- value
- file_ref_segmentation_mask
- segmentation_type
Segmentation_3DEnrichments columns:
- height
- width
- depth
- background
- segmentation_metadata
- value
- file_ref_segmentation_mask
- segmentation_type
Check data in each table:
Validate data integrity:
- In EmbeddingEnrichments, all rows should have a vector column populated. Empty array is a valid result.
- In Text/Object Enrichments, the value and domain columns should have data.
- In Segmentation_2DEnrichments, the mask value should exist as an array of numbers. The segmentation type should also be populated.
- All records in any table should have a
patient_id.
Data can be sparse. For example, not all models produce a confidence score or metadata.
Validate the metadata store
Open the msft_ai_enrichments_metadatastore lakehouse.
Confirm that the following tables have records:
- EnrichmentView: Contains a view for each table that exists in the silver lakehouse and a view for each time you run the use case notebooks.
- EnrichmentContext: Contains records only after the successful run of the pipeline.
- Enrichment: Every time you run the use case notebooks, an enrichment definition is created in this table.
- EnrichmentGenerationInfo
- EnrichmentMaterializedView