Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Note
This feature is available for browser and .NET editions only.
Deferred correction is a workflow in which the author works with frontend recognition (Dragon Medical Server returns recognition results in real time) and another user, typically a transcriptionist, corrects the results at a later point in time.
For the Browser edition, deferred correction is provided through specific SpeechKit URLs for each release channel. For more information and a list of URLs, see Release channels.
Workflow
A typical workflow:
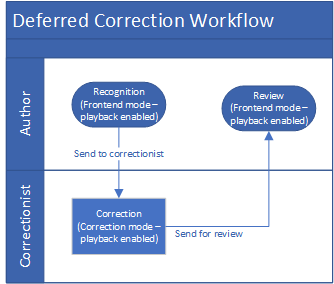
The author uses frontend mode to dictate the report.
The author can make corrections to the recognition results using their voice or keyboard.
If the author wants a transcriptionist to make the corrections, the integrator can save the document for later correction.
The transcriptionist opens the document in correction mode, plays back the audio and edits the recognition results.
The author opens the document in frontend mode, reviews the corrected text and can edit it using their voice or keyboard.
Important information
- The integration must set and change the document mode, based on user type.
- The integration must save the text of the document when it's closed and reload it when the document is opened.
- The integration must send documents between users. SpeechKit doesn't provide a mechanism to do this, or provide worklists for users. SpeechKit provides the recognition and playback interface.
- The integration must prevent multiple users from opening the same document simultaneously. SpeechKit returns an error if the current document is locked by another user. Changes to the document should only be made if the user successfully opens the document.
- Multiple authors recording into a document isn't supported; your integration must ensure this can't occur.
Supporting user profile adaptation
Recognition results in the system are used to adapt authors' speech recognition profiles to improve recognition accuracy over time. An author's profile is adapted only from their own updates to a document:
- The author's initial dictations.
- The author's own corrections in frontend mode.
- Transcriptionist corrections that the author has reviewed by opening and saving the document after the transcriptionist corrected it.
Edits made by transcriptionists aren't used to adapt the author's profile unless the author opens and saves the document after the transcriptionist corrects it.
In some cases, uncorrected text can lead to reduced recognition accuracy over time. Uncorrected text refers to text that the system recognized incorrectly and that wasn't corrected. To mitigate this, include a final sign-off in the deferred correction workflow and track the document state.
In some cases, uncorrected text can lead to reduced recognition accuracy over time. Uncorrected text refers to text that the system recognized incorrectly and that wasn't corrected. To mitigate this, include a final sign-off in the deferred correction workflow.
Including a final sign-off
To make sure the system learns from corrected text, include a final review/sign off stage in your implementation. It's important that the author reopens the document to sign it off after the transcriptionist has made corrections. Your integration should save the document once the author signs it off.
Be aware that the system might send documents for adaptation that haven't been signed off. When this happens, transcriptionists' corrections aren't included in adaptation. After the author signs off the final, corrected text, the document will be sent for adaptation again. In this scenario, both corrected and uncorrected text influence the author's user profile.
Tracking the document state
To minimize the amount of uncorrected text used for adaptation, track the document state. Until the author's final sign-off, your integration should keep the document state as "Uncorrected". When the author signs off the document, the integration should change the document state to "Corrected". For more information on document states, see: Support document workflow functionality (.NET). Be aware that uncorrected text can still be included in adaptation when the author and transcriptionist don't correct all misrecognized text before the author signs off the document.
System requirements
Supported browsers (Microsoft Windows only)
Google Chrome
Microsoft Edge
Foot pedals
For correctionists in deferred correction workflows, some foot pedals are supported. Open the personalization & help window > Options page to configure the action for the play, rewind and fast forward pedals and enable/disable the press-and-hold behavior. For more information on supported models, see the release notes delivered with your version of Dragon Medical SpeechKit.
For correctionists in deferred correction workflows, some foot pedals are supported. Google Chrome is required. Open the personalization & help window > Options page to configure the action for the play, rewind and fast forward pedals and enable/disable the press-and-hold behavior. For more information on supported models, see the release notes delivered with your version of SpeechKit.
On-premises systems
If you're deploying Dragon Medical Server on-premises at your site (and not hosted by Nuance), you need to update your Dragon Medical Server Cluster settings to enable deferred correction. For more information, see the Dragon Medical Server Administration Guide delivered with your on-premises package.
The Dragon Medical SpeechKit browser SDK only supports deferred correction in Nuance-hosted systems. This feature isn't available for on-premises systems.
Document modes
Frontend mode
| Implementation type | App state | Speechbar appearance |
|---|---|---|
| Frontend mode with playback disabled | Recording |  |
| Frontend mode with playback enabled | Recording |  |
| Frontend mode with playback enabled | Playing back audio |  |
- Frontend mode with playback disabled is the default mode. Use this if your integration doesn't require playback.
- In frontend mode with playback enabled, the author can play back the audio recorded for frontend recognition.
- Playback starts from the text cursor position in the document. The text cursor position isn't updated during playback. When the audio is paused, the text cursor moves to the word in the text where the audio was paused.
- Users can adjust the playback speed using the hamburger menu on the speech bar.
- When the author uses speech recognition to dictate over recognized text, the original audio is deleted and replaced with the new audio.
Speech bar appearance when recording audio:
When the author uses speech recognition to dictate over recognized text, the original audio is deleted and replaced with the new audio.
Be aware of the following functionality restrictions in this mode:
The audio cursor position and length aren't displayed.
Rewinding and fast-forwarding aren't supported. Rewind and fast forward buttons on the hardware device move the focus between fields in the document.
- The author can't play back the audio.
- When the author deletes text using the keyboard, the corresponding audio isn't deleted. Deleting text using the keyboard isn't recommended as a transcriptionist will hear the audio when playing back and might re-add the deleted text to the document.
Correction mode
Speech bar appearance when playing back audio:

When playback is paused:

Correction mode is for correcting recognized text; this mode adds playback, rewind, fast forward and audio position seeking functionality for the recorded audio.
Correction mode enables transcriptionists to correct the text. It can also be used when a user wants to listen to the audio without recording anything (recording isn't possible in this mode).
On the speech bar, the audio cursor position is displayed on the left of the slider and the audio length is displayed on the right side of the slider. Playback starts from the audio position slider, regardless of where the text cursor is positioned in the document. The playback speed can be adjusted via the hamburger menu.
The audio cursor position and length are displayed as minutes:seconds when the duration is less than one hour and hours:minutes:seconds when duration is longer than one hour.
Rewinding and fast-forwarding are supported.
Audio can be played back at a minimum of 0.5x speed and a maximum of 2x speed.
Transcriptionists can play back audio from one section of the recognized text while typing in another section of the text.
Be aware of the following functionality restrictions in this mode:
Edits made by transcriptionists don't change the audio.
The last audio position a transcriptionist worked on in a document is remembered when it is reloaded, even if it is a different transcriptionist who then opens the document.
Each transcriptionist needs a Dragon Medical SpeechKit license.
Recording isn't supported.
Playing back audio
Audio is played back in the order of the recognized text.
Auto-texts and voice commands can be used in frontend mode but won't be played back.
Recognized text isn't highlighted during playback.
- When an author plays back audio after making a change to the document manually or via speech recognition, there's a small delay before the audio starts playing.
- If an author types over recognized text and then selects it and dictates over it, both the original audio and the new audio will play back.
Configuring a hotkey for audio and text cursor synchronization
Transcriptionists can configure a hotkey to synchronize the text cursor with the audio position. Open the personalization and help window > Settings > Audio and Text Cursor Synchronization.
Hotkey requirements
- Supported keys: English alphabet (a - z), numbers (0 - 9) and modifiers (CTRL, ALT, SHIFT).
- Keyboard combination format: Modifiers + key.
- CTRL or ALT is required; SHIFT is optional.
Invalid hotkeys
The following keyboard combinations aren't allowed:
ALT + F
ALT + E
CTRL + A
CTRL + C
CTRL + F
CTRL + P
CTRL + O
CTRL + S
CTRL + V
CTRL + X
CTRL + Y
CTRL + Z
CTRL + =
CTRL + -
CTRL + Insert
CTRL + arrow left
CTRL + arrow right
CTRL + Delete
CTRL + Backspace
SHIFT + End
SHIFT + Home
SHIFT + Insert
SHIFT + Delete
CTRL + SHIFT + arrow left
CTRL + SHIFT + arrow right
Warning
If a user specifies a hotkey combination that conflicts with browser functionality, they might experience problems with the app.
Document tokens
Your integration must generate and store document tokens. A document token is a cryptographically generated token used to validate authorization to access the document. It differs from a document ID in that the token should never be disclosed; for example, via the GUI, logging, etc. Make sure it is securely stored. Once a document is created with a token, you must supply the same token when the document is reopened.
Be aware that:
- Once a document token has been assigned to a document, the token can't be modified.
If an existing document does not have a document token assigned, providing a token when opening the document assigns the token to the document.
For backward compatibility, documents that were created (using an earlier version of Dragon Medical SpeechKit) without document tokens can still be reopened. In this scenario, a new token must be supplied when reopening the document.
Once a document token has been assigned to a document, the token can't be modified.
Document tokens should be generated on the server side, whenever possible.
Document tokens should be stored immediately upon being generated; this avoids losing the token and being unable to reopen documents.
Security requirements for document tokens
Document tokens must be cryptographically generated to ensure sufficient entropy and uniqueness. Make sure your integration fulfills the following security requirements for document tokens:
Document tokens must be generated by a CSPRNG (Cryptographically Secure Pseudo-Random Number Generator). The following APIs are recommended:
BCryptGenRandom function (bcrypt.h). See: </windows/win32/api/bcrypt/nf-bcrypt-bcryptgenrandom>
OpenSSL rand. See: https://www.openssl.org/docs/man3.0/man1/openssl-rand.html
For an example of how to use the
BCryptGenRandomfunction in theS_DM_SpeechKit_WPF_Deferred_Correctionsample project, see theDocumentTokenGeneratorclass.Crypto.getRandomValues(). See: https://developer.mozilla.org/docs/Web/API/Crypto/getRandomValues
Document tokens must be at least 32 bytes in length.
Document tokens must be Base64 encoded strings.