Get started driving adoption of Microsoft Syntex
Microsoft Syntex is a cloud-based service that applies artificial intelligence (AI) to automate content processing and knowledge extraction. It helps you to transform your content into structured data that can be easily searched, analyzed, and reused.
Microsoft Syntex offers a range of use cases to enhance content management within an enterprise. Here are some examples of how it can be applied:
Automatically generate routine documents — Employ content assembly to create modern templates for files that need to be generated on a regular basis, such as routine maintenance reports.
Generate documents in bulk — Utilize content assembly to generate large amounts of similar documents, for instance, contract renewals.
Handle incoming documents — Use Microsoft Syntex to manage and process incoming business documents like insurance forms, business verifications, and rental contracts.
Make information easier to find — Use Microsoft Syntex to enhance the discoverability and usability of business documents and employee information in document libraries, such as policies and procedures.
Find content details — Centralize, organize, and retrieve content using Microsoft Syntex to make specific details easier to discover, such as patent information.
Document compliance — Utilize Microsoft Syntex to help comply with retention and sensitivity requirements for your business documents, including event or conference files.
Identify business scenarios
To prepare for using Microsoft Syntex in your organization, you first need to understand the scenarios in which it will be useful. The "why" helps determine what features will be most beneficial and if document processing is required, which model type will be needed. To meet a business outcome, it might be useful to combine multiple Microsoft Syntex features. Use the example scenarios and use cases to prompt ideas about how you can use Microsoft Syntex in your organization.
Content is the lifeblood of the organization. Many business units in your organization are responsible for processing data and might be doing so today with a mix of manual or semi-automated processes that involve multiple steps. Using Microsoft Syntex features can help you improve your organization’s content management practices including:
Provide advanced search and filtering to improve search findability and retrieval.
Set conditional formatting to easily view and filter documents.
Generate a one-click Power BI report using extracted metadata.
Create rules within the document library or business workflows via Power Automate.
Ensure compliance via the application of retention and sensitivity labels.
Consider your content lifecyle
Thinking about the typical content lifecycle where content is created and re-created, through to content understanding and processing and content discovery and search, there are many features within Microsoft Syntex that can help your business.
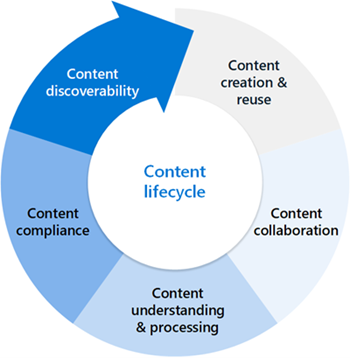
Content creation and reuse
Within the lifecycle of content, there might be use cases for automating content creation, particularly content that is transactional or standardized and content assembly can be useful for this. Content assembly can automatically generate standard repetitive business documents, such as contracts, statements of work, service agreements, letters of consent, sales pitches, and correspondence.
Once you identify repetitive document types, you’ll want to identify the data source that can be used as a source for the documents. Having a list or data source to populate the documents allows you to do this faster, more consistently, and with fewer errors by creating modern templates and using those templates to generate documents. To use this feature, an Azure subscription needs to be configured within the Microsoft Syntex set up.
Content collaboration
The annotations feature in Microsoft Syntex is used to add notes and comments to content in document libraries—either for yourself or for collaborating with others. The annotations feature can be used without modifying the original files, so the original records are preserved.
Annotation tools currently include pen and highlighter, where colors can be selected along with an eraser for removing ink strokes and previous annotations. Once you configure an Azure subscription in your tenant for Microsoft Syntex, this feature will be enabled for your users. You might want to consider providing details to end users about the feature, particularly to business groups that might heavily markup or annotate documents.
Content understanding and processing
Using Microsoft Syntex to automate the classification and data extraction from the content using document processing and the taxonomy tagging or image tagging features can save time and money while minimizing risk of typos or missed information.
Microsoft Syntex can perform different types of tasks across your content including classification, extraction, and keywords. The following table shows these tasks and related features.
| Task | Description | Microsoft Syntex feature |
|---|---|---|
| Classification | Identifies the type of content the file represents (for example, a report, an invoice, or a form) | Unstructured document processing |
| Extraction | Identifies information based on an entity from within a document | Structured document processing Freeform document processing Prebuilt document processing Optical character recognition |
| Keyword tagging | Suggests information based on a property of or decision about a document using keywords | Taxonomy tagging Image tagging |
Content compliance
The document processing models can also be used to add compliance by having them apply sensitivity labels and retention labels to content added to document libraries with models configured with them.
Once the content type and metadata are available in a document library, business users can perform many actions on the data including creating new views on the content, building reports, moving content based on certain information present using rules, and creating business process workflows for approvals, adding data to other systems, generating work orders and many other tasks that might have been done manually.
Content discoverability
Using document processing features in Microsoft Syntex can improve the search experience as each piece of metadata extracted from content now will be searchable. The content query feature lets you perform specific metadata-based queries on SharePoint document libraries. You can make faster, more precise queries based on specific metadata column values, rather than just searching for keywords.
In addition to classifying and extracting data from content added to a SharePoint library, your organization might have content currently locked in images that is challenging to locate. The optical character recognition (OCR) service in Microsoft Syntex lets you extract printed or handwritten text from images and documents. Examples of images include posters, drawings, and product labels. Examples of documents include articles, reports, forms, and invoices. The text is typically extracted as words, text lines, and paragraphs or text blocks, enabling access to digital version of the scanned text. The extracted information is indexed in search and can be made available for compliance features like data loss prevention (DLP).
Plan for getting started
When getting started with Microsoft Syntex, you’ll want to assess the current state and needs of the organization regarding content management, processing, and analysis. It might help to identify specific key content repositories used by groups in your organization and to discuss with those teams their current business processes and scenarios. Are there cases where they're currently managing content manually that can be automated? These might include cases where they're handling intake of standard forms or documents like HR documents or purchase orders for processing or if they're generating repeated content at scale such as offer letters or proposals. Or areas where they're doing their annotations via pen and paper or a third-party application where you can now do this within your existing SharePoint environment.
When thinking about which business scenarios to consider, ask yourself the following questions:
- Does it solve a real problem?
- Will it be widely used or have broad impact?
- Is it obtainable?
- Can you measure success?
The Microsoft Syntex commands in the Microsoft 365 Assessment tool can also help identify potential areas of your SharePoint environment that could benefit from Microsoft Syntex features.
If you’re not sure where to start, consider checking out the Microsoft Syntex site templates available in your tenant once you set up Microsoft Syntex and configure your Azure subscription. These templates are available on all team sites and are prebuilt, ready-to-deploy, and customizable. Use these templates to jumpstart a professional site to manage, process, and track the status of business documents in your organization using multiple Microsoft Syntex features. These sites can help you demo features to business teams and jumpstart envisioning and scenario development for your organization by illustrating how the features can add value for business areas like contract management and accounting.
Identify roles and responsibilities
When determining who in your organization will need to be involved in your Microsoft Syntex projects, it will help to map out the features required. The roles in the following table might be involved, depending on the features you select to use.
For example, if you're focused on document processing, then the SharePoint administrator role will be key in creating and managing content centers needed to manage models at scale. If you’re focused on features like OCR and compliance, then the Purview Compliance administrator will be needed. If taxonomy tagging will be pursued, it’s important to understand your corporate term store management or to determine if you’ll use a content center.
| Administrator | Requirement | Responsibilities |
|---|---|---|
| Azure Subscriptions administrator | Microsoft Entra role | Configure Azure subscription settings, review Microsoft cost management in Azure data |
| Purview Compliance administrator | Microsoft Entra role | Plan for compliance settings, such as sensitivity labels and retention policies and OCR settings |
| SharePoint administrator | Microsoft Entra role | Gather business use cases, determine if features will be enabled across all sites or for selected sites Manage content centers and permissions Establish best practices and review model analytics |
| Power Platform administrator | Microsoft Entra role | Configure Dataverse environment (if necessary) for freeform and structured models |
| SharePoint Term Store administrator | Configured by SharePoint admin in SharePoint admin center | Manage enterprise term sets, determine if end users can modify certain term sets |
| Microsoft Syntex business user (managing models, using content assembly) | Permissions managed at the site level or on content centers Content enter edit permissions SharePoint Manage Lists permissions where you want to publish models or use content assembly features |
Gather business use cases Create, train, and apply models |
Setup and configuration considerations
Planning for a deployment of Microsoft Syntex involves determining which features you’ll enable and planning for costs using the Microsoft Syntex cost calculator to assist in predicting costs for Microsoft Syntex, particularly with the advent of pay-as-you-go services. This tool gives you a better understanding of your organization’s usage patterns and estimated costs so you can make more informed decisions. It’s also helpful in conjunction with the Microsoft 365 Assessment tool, which analyzes your information architecture and highlights libraries with customer content types and extended columns that can benefit from Syntex-powered automation.
Readiness checklist

To get ready for implementing Microsoft Syntex, you need to:
Plan the end state
- Plan for harnessing the value of Microsoft Syntex features in areas like:
- Search
- Filtering and view formatting
- Compliance
- Automation
- Plan for harnessing the value of Microsoft Syntex features in areas like:
Identify
- Understand existing information architecture and content management feature use.
- Are any existing content types good candidates for models?
- What existing processes would be improved by metadata?
- How much content will you process?
Design
- Design your approach to information architecture, managed metadata, and content types.
- Design the process for definition, creation, and management.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for