Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Column Types
NimbusML wraps a library written in C#, which is a strongly typed language. Columns of the input data sources are ascribed a type, which is used by transforms and trainers to decide if they can operate on that column. Some transforms may only allow text data types, while others only numeric. Trainers almost exclusively require the features and labels to be of a numeric type.
Type is one of the following:
TX : text
BL : boolean
R4, R8 : single and double precision floating-point
I1, I2, I4, I8 : signed integer types with the indicated number of bytes
U1, U2, U4, U8, U256 : unsigned integer types with the indicated number of bytes
U4[100-199] : A key type based on U4 representing legal values from 100 to 199, inclusive
V<R4,3,2> A VectorDataViewType with item type R4 and dimensionality information [3,2]
For more details, please refer to UnmanagedType Enumeration.
VectorDataViewType Columns
A VectorDataViewType column contains a vector of values of a homogenous type, and is associated with a
column_name.
The following table shows how NimbusML processes a dataset:
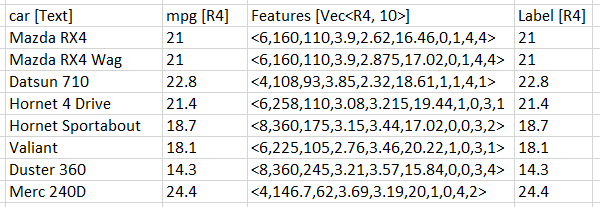
The third column is a VectorDataViewType column named Features with 10 slots. A VectorDataViewType column can
be referenced within a transform (or estimator) by its column_name, such as using Feature. But
the slots themselves may also have names which are generated dynamically by the transform during
the fit() method. As the return type of all of the transforms is a pandas.DataFrame, a
VectorDataViewType column will be converted. The column_name of the vector is lost, but the slot names
are preserved (and available for viewing). In the above example, the Features column may be
converted to 10 columns with names Features.0, Features.1,…,Features.9 as the output of a
transform. However, within a nimbusml.Pipeline , there is no conversion to a
dataframe and therefore the column_name can still be used to refer to the VectorDataViewType column.
Note: Transforms frequently output VectorDataViewType columns. Within an nimbusml.Pipeline, data transfer between transforms is done very efficiently without any conversion to a dataframe. Since the column_name of the vector is also preserved, it is possible to refer to it by downstream transforms by name. However, when transforms are used inside a sklearn.pipeline.Pipeline(), the output of every transform is converted to a pandas.DataFrame first where the names of slots are preserved, but the column_name of the vector is dropped.
KeyType Columns
KeyType columns are categorical columns, which use unsigned integers to represent distinct values of the column. Some properties of KeyType columns are:
Values are stored in unsigned integers
Missing key value is stored at 0
Non-missing key values start from 1
KeyTypes are typically generated from transforms, like the ToKey transform. However, they
may also be specified by the user via a Schema. If they are user-specified, then a valid
range must be specified.
For example if a column is specified as
U1[4000-4002]
and the data observed from the Data Sources contains these values
4000
4003
4002
4001
then the invalid value 4003 will be interpreted as a missing value
4000
<?>
4002
4001