Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Learners and transformations in NimbusML can be used in sklearn pipelines together with scikit learn elements. In this example, we develop a scikit learn pipeline with NimbusML featurizer and then replace all scikit learn elements with NimbusML ones.
We use the Wikipedia Detox dataset to develop a binary classifier to identify if a comment on the webpage is a personal attack. The original input data includes a corpus of 95 million article talks, while in this example, we use a small sample (100 rows) for training and testing.
2 models/pipelines are created:
- A sklearn pipeline with NimbusML NGramFeaturizer, sklearn Truncated SVD and sklearn LogisticRegression
- A NimbusML pipeline with NimbusML NGramFeaturizer, NimbusML WordEmbedding and NimbusML FastLinearBinaryClassifier trained with NimbusML FileDataStream.
A sample of the dataset is presented in the following table:
| Sentiment | SentimentText |
|---|---|
| 1 | ==RUDE== Dude, you are rude upload that carl picture back, or else. |
| 1 | == OK! == IM GOING TO VANDALIZE WILD ONES WIKI THEN!!! |
| 1 | Stop trolling, zapatancas, calling me a liar merely demonstartes that you arer Zapatancas... |
For simplicity, we just use the "comment" column as the input data and the "Label" column as the label.
Model 1: Sklearn Pipeline with NimbusML Element
In this example, we create a sklearn pipeline with NimbusML NGramFeaturizer, sklearn Truncated SVD and sklearn LogisticRegression. Similarly to the TfidfVectorizer(), our NGramFeaturizer creates the the same bag of counts of sequences and weights it using TF-IDF method. The NimbusML featurizer works as well in a sklearn pipeline. We can just swap out the first TfidfVectorizer() with our NGramFeaturizer() in the sklearn pipeline.
import numpy as np
import time
import sklearn
import os
from IPython.display import display
import matplotlib.pyplot as plt
import pandas as pd
from nimbusml.datasets import get_dataset
from nimbusml.feature_extraction.text.extractor import Ngram
from nimbusml.feature_extraction.text import NGramFeaturizer
from sklearn.feature_extraction.text import TfidfVectorizer as sklearn_TfidfVectorizer
from sklearn.decomposition import TruncatedSVD as sklearn_TruncatedSVD
from sklearn.pipeline import Pipeline as sklearn_ppl
from sklearn.metrics import roc_auc_score, roc_curve
from sklearn.metrics import auc as sk_auc
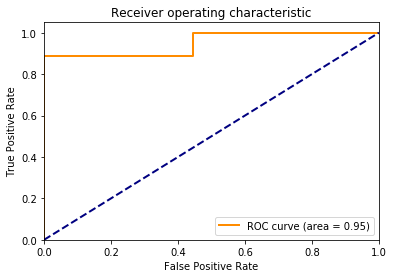
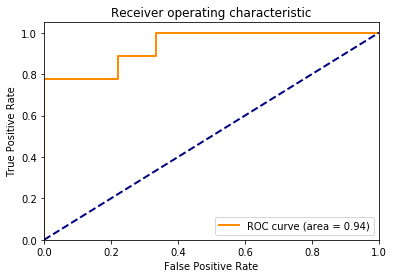
def plot_roc_score(label_test, score):
x, y, _ = roc_curve(label_test, score)
roc_auc = sk_auc(x, y)
plt.figure()
lw = 2
plt.plot(x, y, color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Receiver operating characteristic')
plt.legend(loc="lower right")
plt.show()
# Get input data file path from the package
Train_file = get_dataset('wiki_detox_train').as_filepath()
Test_file = get_dataset('wiki_detox_test').as_filepath()
print(os.path.basename(Train_file))
print(os.path.basename(Test_file))
train-250.wikipedia.sample.tsv
test.wikipedia.sample.tsv
# Loading data
# dataTrain = pd.read_csv(Train_file, encoding="ISO-8859-1", sep = "\t") # Error under py2.7 but not 3.6
dataTrain = pd.read_csv(Train_file, sep = "\t")
dataTest = pd.read_csv(Test_file, sep = "\t")
dataTrain.head()
| Sentiment | SentimentText | |
|---|---|---|
| 0 | 1 | ==RUDE== Dude, you are rude upload that carl... |
| 1 | 1 | == OK! == IM GOING TO VANDALIZE WILD ONES W... |
| 2 | 1 | Stop trolling, zapatancas, calling me a lia... |
| 3 | 1 | ==You're cool== You seem like a really cool... |
| 4 | 1 | ::::: Why are you threatening me? I'm not bei... |
# Creating pipeline
t0 = time.time()
featurizer = NGramFeaturizer(word_feature_extractor=Ngram())
svd = sklearn_TruncatedSVD(random_state = 1, n_components = 400)
lr = sklearn.linear_model.LogisticRegression()
sk_ppl = sklearn_ppl([("featurizer",featurizer),
("svd",svd),
("lr",lr)])
# Training
sk_ppl.fit(dataTrain[["SentimentText"]], dataTrain["Sentiment"]) #UPDATE ONCE SERIES IS SUPPORTED FOR X!
train_time_sec = time.time() - t0
print("Training time: " + str(round(train_time_sec,2)) + "s")
Training time: 5.8s
c:\users\v-tshuan\env\env\python37_general\lib\site-packages\sklearn\linear_model\logistic.py:432: FutureWarning: Default solver will be changed to 'lbfgs' in 0.22. Specify a solver to silence this warning.
FutureWarning)
# Testing
t0 = time.time()
Y_pred = sk_ppl.predict(dataTest["SentimentText"].to_frame()) #UPDATE ONCE SERIES IS SUPPORTED FOR X!
Y_prob = sk_ppl.predict_proba(dataTest["SentimentText"].to_frame())#UPDATE ONCE SERIES IS SUPPORTED FOR X!
test_time_sec = time.time() - t0
print("Testing time: " + str(round(test_time_sec,2)) + "s")
Testing time: 2.42s
# Plot roc
plot_roc_score(dataTest["Sentiment"], Y_prob[:,1]);
Model 2: Pure NimbusML with Schema
In this example, we will create a pure NimbusML pipeline with only NimbusML elements, i.e. NimbusML NGramFeaturizer, NimbusML WordEmbedding and NimbusML FastLinearBinaryClassifier. We will process the data using NimbusML DataFileStream instead of pandas dataframe.
import time
from nimbusml.linear_model import FastLinearBinaryClassifier
from nimbusml.feature_extraction.text import WordEmbedding
from nimbusml import Pipeline, FileDataStream
The WordEmbedding() is based on a pretrained DNN model to generate word embeddings for given corps. In this example, we use the 'GloVe50D' as the embedding model. Available options are: 'GloVe50D', 'GloVe100D', 'GloVe200D', 'GloVe300D', 'GloVeTwitter25D', 'GloVeTwitter50D', 'GloVeTwitter100D', 'GloVeTwitter200D', 'FastTextWikipedia300D', and 'Sswe'. The output is 100 dimensional and compared with the "vanilla" ngram models, the features are much more meaningful. Users can also play with other options, such as the Sentiment-specific word embedding (SSWE), which incorporates sentiment information into the features. It's proved to be useful in various sentiment analysis tasks.
The WordEmbedding() takes as input a sequence of words:
["This", "is", "a", "sentence"].
Therefore, we need to convert the raw input "This is a sentence" into the format that SsweEmbedding requires. And that can be done using the NGramFeaturizer() and setting output_tokens = True. Let's see a short example.
featurizer = NGramFeaturizer(columns=['SentimentText'], output_tokens_column_name='SentimentText_TransformedText')
glove = WordEmbedding(columns='SentimentText_TransformedText', model_kind='SentimentSpecificWordEmbedding') # indicating we are using the output token column
ppl = Pipeline([featurizer,glove])
ppl.fit_transform(dataTrain[["SentimentText"]])[0:3] #UPDATE WHEN SUPPORT SERIES!
| SentimentText.Char.<␂>|<␠>|<␠> | SentimentText.Char.<␠>|<␠>|= | SentimentText.Char.<␠>|=|= | SentimentText.Char.=|=|r | SentimentText.Char.=|r|u | SentimentText.Char.r|u|d | SentimentText.Char.u|d|e | SentimentText.Char.d|e|= | SentimentText.Char.e|=|= | SentimentText.Char.=|=|<␠> | ... | SentimentText_TransformedText.140 | SentimentText_TransformedText.141 | SentimentText_TransformedText.142 | SentimentText_TransformedText.143 | SentimentText_TransformedText.144 | SentimentText_TransformedText.145 | SentimentText_TransformedText.146 | SentimentText_TransformedText.147 | SentimentText_TransformedText.148 | SentimentText_TransformedText.149 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.112509 | 0.112509 | 0.112509 | 0.112509 | 0.112509 | 0.225018 | 0.337526 | 0.112509 | 0.112509 | 0.112509 | ... | -0.463254 | -0.081983 | 1.956025 | 0.483862 | 1.145274 | 0.730155 | 1.072578 | 1.693832 | -0.134111 | 3.389347 |
| 1 | 0.123091 | 0.123091 | 0.246183 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.246183 | ... | -0.529051 | -0.036032 | 0.686052 | 0.628498 | 0.456804 | 0.624132 | 2.142290 | 1.189043 | -0.230683 | 2.423379 |
| 2 | 0.036936 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | ... | 1.069717 | 1.617938 | 3.589748 | 2.685204 | 2.276195 | 1.861450 | 2.721365 | 2.395365 | 0.310610 | 4.255451 |
3 rows × 8781 columns
The first part of the output is the output from the NGramFeaturizer(), i.e. the weighted word/sequence count with names "comment.[word]". The name of this output column is renamed to "comment_TransformedText", which is the input column name plus "_TransformedText".
This column used as input to Sentiment Specific Word Embedding, and it has a array of the words, e.g. ["This", "is", "a", "sentence"]. The output from the Sentiment Specific Word Embedding is named comment_TransformedText.* and has 100 dimensions.
Let's create a full pipeline for the classification problem.
# Generating data file stream
data_stream_train = FileDataStream.read_csv(Train_file, sep='\t',collapse=False)
data_stream_test = FileDataStream.read_csv(Test_file, sep='\t',collapse=False)
# Creating pipeline
pipeline = Pipeline([
NGramFeaturizer(word_feature_extractor=Ngram(), output_tokens_column_name='SentimentText_TransformedText', columns=['SentimentText']),
WordEmbedding(columns = "SentimentText_TransformedText"),
FastLinearBinaryClassifier(feature = ["SentimentText_TransformedText"], label = 'Sentiment')
])
# Training
pipeline.fit(data_stream_train)
Automatically adding a MinMax normalization transform, use 'norm=Warn' or 'norm=No' to turn this behavior off.
Using 4 threads to train.
Automatically choosing a check frequency of 4.
Auto-tuning parameters: maxIterations = 6300.
Auto-tuning parameters: L2 = 2.669429E-05.
Auto-tuning parameters: L1Threshold (L1/L2) = 0.25.
Using best model from iteration 1924.
Not training a calibrator because it is not needed.
Elapsed time: 00:00:01.0685847
<nimbusml.pipeline.Pipeline at 0x1e79c9576d8>
# Testing
metrics, scores = pipeline.test(data_stream_test,'Sentiment', output_scores = True)
metrics
| AUC | Accuracy | Positive precision | Positive recall | Negative precision | Negative recall | Log-loss | Log-loss reduction | Test-set entropy (prior Log-Loss/instance) | F1 Score | AUPRC | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.950617 | 0.833333 | 0.8 | 0.888889 | 0.875 | 0.777778 | 0.425584 | 0.574416 | 1 | 0.842105 | 0.964387 |
# Plot roc
plot_roc_score(dataTest["Sentiment"], scores["Probability"]);