Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Before you can use the process mining capability in Power Automate effectively, you need to understand:
Here's a short video on how to upload data for use with the process mining capability:
Data requirements
Event logs and activity logs are tables stored in your system of record that document when an event or activity occurs. For example, activities you perform in your customer relationship management (CRM) app are saved as an event log in your CRM app. For process mining to analyze the event log, the following fields are necessary:
Case ID
Case ID should represent an instance of your process and is often the object that the process acts on. It can be a "patient ID" for an inpatient check-in process, an "order ID" for an order submission process, or a "request ID" for an approval process. This ID must be present for all activities in the log.
Activity Name
Activities are the steps of your process, and activity names describe each step. In a typical approval process, the activity names might be "submit request," "request approved," "request rejected," and "revise request."
Start Timestamp and End Timestamp
Timestamps indicate the exact time that an event or activity took place. Event logs have only one timestamp. This indicates the time that an event or activity occurred in the system. Activity logs have two timestamps: a start timestamp and an end timestamp. These indicate the start and end of each event or activity.
You can also extend your analysis by ingesting optional attribute types:
Resource
A human or technical resource executing a specific event.
Event Level Attribute
Additional analytical attribute, which has different value per event, for example, Department performing the activity.
Case Level Attribute (first event)
Case Level Attribute is an additional attribute, that from the analytical point of view is considered to have a single value per case (for example, Amount of Invoice in USD). However, the event log to be ingested doesn't necessarily have to comply with consistency by having the same value for the specific attribute for all events in the event log. It might not be possible to ensure that, for example, when incremental data refresh is used. Power Automate Process Mining ingests the data as is, storing all values provided in the event log, but uses a so called case level attribute interpretation mechanism to work with the attributes on case level.
In other words, whenever the attribute is used for specific function, which requires event level values (for example, event level filtering), the product uses the event level values. Whenever a case level value is needed (for example, case level filter, root cause analysis), it uses the interpreted value, which is taken from the chronologically first event in the case.
Case Level Attribute (last event)
The same as Case Level Attribute (first event) but when interpreted on case level, the value is taken from the chronologically last event in the case.
Financial per Event
Fixed cost/revenue/numeric value that changes per activity performed, for example, courier service costs. Financial value is calculated as a sum (mean, minimum, maximum) of the financial values per each event.
Financial Per Case (first event)
Financial per Case attribute is an additional numeric attribute, that from the analytical point of view is considered to have a single value per case (for example, Amount of Invoice in USD). However, the event log to be ingested doesn't necessarily have to comply with consistency by having the same value for the specific attribute for all events in the event log. It might not be possible to ensure that, for example, when incremental data refresh is used. Power Automate Process Mining ingests the data as is, storing all values provided in the event log. However, it uses a so called case level attribute interpretation mechanism to work with the attributes on case level.
In other words, whenever the attribute is used for specific function, which requires event level values (for example, event level filtering), the product uses the event level values. Whenever a case level value is needed (for example, case level filter, root cause analysis), it uses the interpreted value, which is taken from the chronologically first event in the case.
Financial Per Case (last event)
The same as Financial Per Case (first event) but when interpreted on case level, the value is taken from the chronologically last event in the case.
Where to get log data from your application
The process mining capability needs event log data to perform process mining. While many tables that exist in your application’s database contain the current state of the data, they might not contain a historical record of the events that happened, which is the required event log format. Fortunately, in many larger applications, this historical record, or log is often stored in a specific table. For example, many Dynamics applications keep this record in the Activities table. Other applications, like SAP or Salesforce, have similar concepts, but the name might be different.
In these tables that log historical records, the data structure can be complex. You might need to join the log table with other tables in the application database to get specific IDs or names. Also, not all events that you're interested in are logged. You might need to determine what events should be kept or filtered out. If you need help, you should contact the IT team that manages this application to understand more.
Connect to a data source
The benefit of connecting to a database directly is keeping the process report up to date with the latest data from the data source.
Power Query supports a large variety of connectors that provide a way for the process mining capability to connect and import data from the corresponding data source. Common connectors include Text/CSV, Microsoft Dataverse, and SQL Server database. If you're using an application like SAP or Salesforce, you might be able to connect to those data sources directly via their connectors. For information on supported connectors and how to use them, go to Connectors in Power Query.
Try out the process mining capability with the Text/CSV connector
One easy way to try out the process mining capability regardless of where your data source is located is with the Text/CSV connector. You might need to work with your database admin to export a small sample of the event log as a CSV file. Once you have the CSV file, you can import it into the process mining capability using the following steps in the data source selection screen.
Note
You must have OneDrive for Business to use the Text/CSV connector. If you don't have OneDrive for Business, consider using Blank table instead of Text/CSV, as in the followng step 3. You won't be able to import as many records in Blank table.
On the process mining home page, create a process by selecting Start here.
Enter a process name and select Create.
On the Choose data source screen, select All categories > Text/CSV.
Select Browse OneDrive. You might need to authenticate.

Upload your event log by selecting the Upload icon in the upper right and then selecting Files.
Upload your event log, select your file from the list, and then select Open to use that file.
Use the Dataflow connector
The Dataflow connector isn't supported in Microsoft Power Platform. The existing Dataflow can't be used as a data source for Power Automate Process Mining.
Use the Dataverse connector
The Dataverse connector isn't supported in Microsoft Power Platform. You need to connect to it using the OData connector, which requires a few more steps.
Make sure you have access to the Dataverse environment.
You need the environment URL of the Dataverse environment you're trying to connect to. Normally it looks like this:
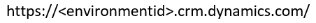
To learn how to find your URL, go to Finding your Dataverse environment URL.
On the Power Query - Choose data sources screen, select OData.
In the URL textbox, type api/data/v9.2 at the end of the URL so it looks like this:
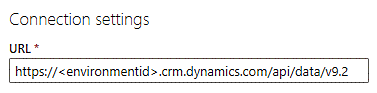
Under Connection credentials, select Organizational account in the Authentication kind field.
Select Sign in and enter your credentials.
Select Next.
Expand the OData folder. You should see all the Dataverse tables in that environment. As an example, the Activities table is called activitypointers.
Select the checkbox next to the table you want to import, and then select Next.