Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
The sampling algorithm in Power BI improves visuals that sample high-density data. For example, you might create a line chart from your retail stores' sales results, each store having more than 10,000 sales receipts each year. A line chart of such sales information samples data from the data for each store and creates a multi-series line chart that represents the underlying data. Select a meaningful representation of that data to illustrate how sales vary over time. This practice is common in visualizing high-density data. The details of high-density data sampling are described in this article.
Note
The High-density sampling algorithm described in this article is available in both Power BI Desktop and the Power BI service.
How high-density line sampling works
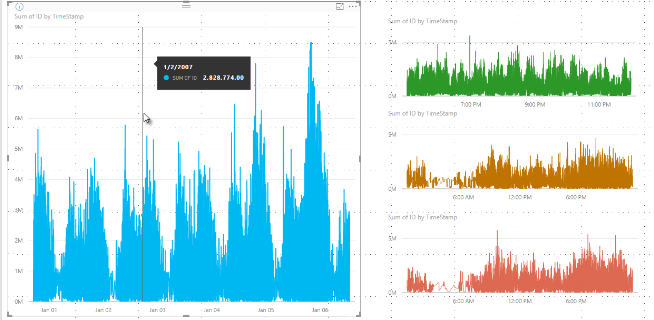
Previously, Power BI selected a collection of sample data points in the full range of underlying data in a deterministic fashion. For example, with high-density data on a visual spanning one calendar year, the visual displays 350 sample data points. The algorithm selects each data point to ensure the full range of data is represented in the visual. To help understand how this happens, imagine plotting a stock price over a one-year period and selecting 365 data points to create a line chart visual. That's one data point for each day.
In that situation, many values exist for a stock price within each day. Of course, there's a daily high and low, but those values could occur at any time during the day when the stock market is open. For high-density line sampling, if the underlying data sample is taken at 10:30 AM and 12:00 PM each day, you get a representative snapshot of the underlying data, such as the price at 10:30 AM and 12:00 PM. However, the snapshot might not capture the actual high and low of the stock price for that representative data point that day. In that situation and others, the sampling is representative of the underlying data, but it doesn't always capture important points, which in this case would be daily stock price highs and lows.
By definition, high-density data is sampled to create visualizations reasonably quickly that are responsive to interactivity. Too many data points on a visual can slow it down and can detract from the visibility of trends. How the data is sampled drives the creation of the sampling algorithm to provide the best visualization experience. In Power BI Desktop, the algorithm provides the best combination of responsiveness, representation, and clear preservation of important points in each time slice.
How the line sampling algorithm works
The algorithm for high-density line sampling is available for line chart and area chart visuals with a continuous x-axis.
For a high-density visual, Power BI intelligently slices your data into high-resolution chunks and then picks important points to represent each chunk. That process of slicing high-resolution data is tuned to ensure that the resulting chart is visually indistinguishable from rendering all of the underlying data points but is faster and more interactive.
Minimum and maximum values for high-density line visuals
For any visualization, the following limitations apply:
- 3,500 is the maximum number of data points displayed on most visuals, regardless of the number of underlying data points or series. For exceptions, see the following list. For example, if you have 10 series with 350 data points each, the visual reaches its maximum overall data points limit. If you have one series, it might have up to 3,500 data points if the algorithm deems that the best sampling for the underlying data.
- There's a maximum of 60 series for any visual. If you have more than 60 series, break up the data and create multiple visuals with 60 or fewer series each. It's good practice to use a slicer to show only segments of the data but only for certain series. For example, if you're displaying all subcategories in the legend, you could use a slicer to filter by the overall category on the same report page.
The maximum number of data limits is higher for the following visual types, which are exceptions to the 3,500 data point limit:
- 150,000 data points maximum for R visuals.
- 30,000 data points for Azure Map visuals.
- 10,000 data points for some scatter chart configurations (scatter charts default to 3,500).
- 3,500 for all other visuals using high-density sampling. Some other visuals might visualize more data, but they don't use sampling.
These parameters ensure that visuals in Power BI Desktop render quickly, stay responsive to user interaction, and don't cause undue computational overhead on the computer rendering the visual.
Evaluate representative data points for high-density line visuals
When the number of underlying data points exceeds the maximum data points that the visual can represent, a process called binning begins. Binning chunks the underlying data into groups called bins and then iteratively refines those bins.
The algorithm creates as many bins as possible to create the greatest granularity for the visual. Within each bin, the algorithm finds the minimum and maximum data value to ensure that important and significant values, such as outliers, are captured and displayed in the visual. Based on the results of the binning and subsequent evaluation of the data by Power BI, the minimum resolution for the x-axis for the visual is determined to ensure maximum granularity for the visual.
As mentioned previously, the minimum granularity for each series is 350 points, and the maximum is 3,500 for most visuals. The exceptions are listed in the previous section.
Each bin is represented by two data points, which become the bin's representative data points in the visual. The data points are the high and low value for that bin. By selecting the high and low values, the binning process ensures any important high value or significant low value is captured and rendered in the visual.
If that process sounds like a lot of analysis to ensure the occasional outlier is captured and properly displayed in the visual, you're correct. That's the exact reason for the algorithm and binning process.
Tooltips and high-density line sampling
The binning process captures and displays the minimum and maximum value in a given bin. This process might affect how tooltips display data when you hover over the data points. To explain how and why this process affects tooltips, let's revisit our example about stock prices.
You're creating a visual based on stock price and you're comparing two different stocks, both of which use High-density sampling. The underlying data for each series has many data points. For example, you capture the stock price each second of the day. The high-density line sampling algorithm performs binning for each series independently of the other.
Now, the first stock jumps up in price at 12:02, then quickly comes back down 10 seconds later. That's an important data point. When binning occurs for that stock, the high value at 12:02 is a representative data point for that bin.
However, for the second stock, 12:02 isn't a high or a low in the bin that includes that time. Maybe the high and low for the bin that includes 12:02 occur three minutes later. In that situation, when the line chart is created and you hover over 12:02, you see a value in the tooltip for the first stock. This value exists because the first stock jumps at 12:02 and the algorithm selects that value as the bin's high data point. However, you don't see any value in the tooltip at 12:02 for the second stock. The second stock didn't have a high or a low for the bin that included 12:02. Therefore, there's no data to show for the second stock at 12:02, and thus, no tooltip data is displayed.
This situation happens frequently with tooltips. The high and low values for a specific bin probably don't match perfectly with the evenly scaled x-axis value points, so the tooltip doesn't display the value.
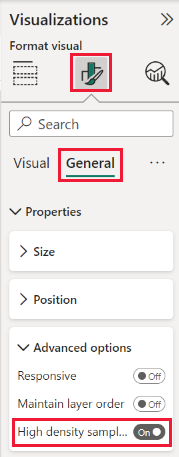
Turn on high-density line sampling
By default, the algorithm is On. To change this setting, go to the Formatting pane, in the General card, and along the bottom, you see the High-density sampling slider. Select the slider to switch On or Off.
Considerations and limitations
The algorithm for high-density line sampling is an important improvement to Power BI, but there are a few considerations you need to know when working with high-density values and data.
- Because of increased granularity and the binning process, Tooltips might only show a value if the representative data aligns with your cursor. For more information, see the Tooltips and high-density line sampling section in this article.
- When the size of an overall data source is too large, the algorithm eliminates series (legend elements) to accommodate the data import maximum constraint.
- In this situation, the algorithm orders legend series alphabetically. It starts down the list of legend elements in alphabetical order until the data import maximum is reached, and it doesn't import more series.
- When an underlying data set has more than 60 series, the maximum number of series, the algorithm orders the series alphabetically, and it eliminates series beyond the 60th alphabetically ordered series.
- If the values in the data aren't numeric or date/time types, Power BI doesn't use the algorithm and reverts to the previous, non-high-density sampling algorithm.
- The Show items with no data setting isn't supported by the algorithm.
- The algorithm isn't supported when using a live connection to a model hosted in SQL Server Analysis Services version 2016 or earlier. It's supported in models hosted in Power BI or Azure Analysis Services.