Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Summary
| Item | Description |
|---|---|
| Release State | General Availability |
| Products | Excel Power BI (Semantic models) Power BI (Dataflows) Fabric (Dataflow Gen2) Power Apps (Dataflows) Analysis Services |
| Authentication Types Supported | Basic Database Windows |
| Function Reference Documentation | SapHana.Database |
Note
Some capabilities might be present in one product but not others due to deployment schedules and host-specific capabilities.
Prerequisites
You need an SAP account to sign in to the website and download the drivers. If you're unsure, contact the SAP administrator in your organization.
To use SAP HANA in Power BI Desktop or Excel, you must have the SAP HANA ODBC driver installed on the local client computer for the SAP HANA data connection to work properly. You can download the SAP HANA Client tools from SAP Development Tools, which contains the necessary ODBC driver. Or you can get it from the SAP Software Download Center. In the Software portal, search for the SAP HANA CLIENT for Windows computers. Since the SAP Software Download Center changes its structure frequently, more specific guidance for navigating that site isn't available. For instructions about installing the SAP HANA ODBC driver, go to Installing SAP HANA ODBC Driver on Windows 64 Bits.
To use SAP HANA in Excel, you must have either the 32-bit or 64-bit SAP HANA ODBC driver (depending on whether you're using the 32-bit or 64-bit version of Excel) installed on the local client computer.
This feature is only available in Excel for Windows if you have Office 2019 or a Microsoft 365 subscription. If you're a Microsoft 365 subscriber, make sure you have the latest version of Office.
HANA 1.0 SPS 12rev122.09, 2.0 SPS 3rev30, and BW/4HANA 2.0 is supported.
Capabilities Supported
- Import
- Direct Query (Power BI semantic models)
- Advanced
- SQL Statement
Connect to an SAP HANA database from Power Query Desktop
To connect to an SAP HANA database from Power Query Desktop:
Select Get Data > SAP HANA database in Power BI Desktop or From Database > From SAP HANA Database in the Data ribbon in Excel.
Enter the name and port of the SAP HANA server you want to connect to. The example in the following figure uses
SAPHANATestServeron port30015.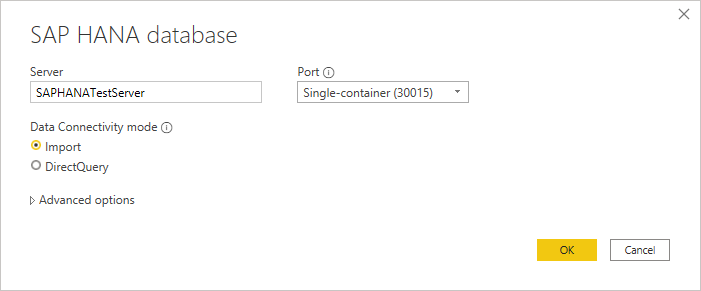
By default, the port number is set to support a single container database. If your SAP HANA database can contain more than one multitenant database container, select Multi-container system database (30013). If you want to connect to a tenant database or a database with a nondefault instance number, select Custom from the Port drop-down menu.
If you're connecting to an SAP HANA database from Power BI Desktop, you're also given the option of selecting either Import or DirectQuery. The example in this article uses Import, which is the default (and the only mode for Excel). For more information about connecting to the database using DirectQuery in Power BI Desktop, go to Connect to SAP HANA data sources by using DirectQuery in Power BI.
You can also enter a SQL statement or enable column binding from Advanced options. More information, Connect using advanced options
Once you enter all of your options, select OK.
If you're accessing a database for the first time, you're asked to enter your credentials for authentication. In this example, the SAP HANA server requires database user credentials, so select Database and enter your user name and password. If necessary, enter your server certificate information.
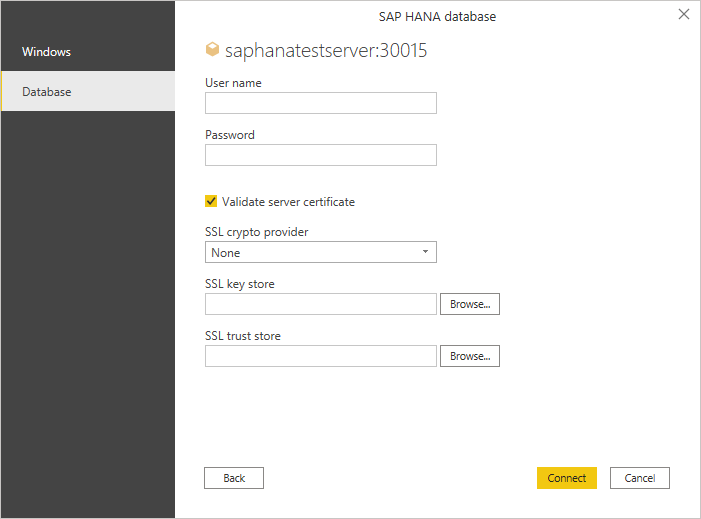
Also, you might need to validate the server certificate. For more information about using validate server certificate selections, go to Using SAP HANA encryption. In Power BI Desktop and Excel, the validate server certificate selection is enabled by default. If you already set up these selections in ODBC Data Source Administrator, clear the Validate server certificate check box. To learn more about using ODBC Data Source Administrator to set up these selections, go to Configure SSL for ODBC client access to SAP HANA.
For more information about authentication, go to Authentication with a data source.
Once you fill in all required information, select Connect.
From the Navigator dialog, you can either transform the data in the Power Query editor by selecting Transform Data, or load the data by selecting Load.
Connect to an SAP HANA database from Power Query Online
To connect to SAP HANA data from Power Query Online:
From the Data sources page, select SAP HANA database.
Enter the name and port of the SAP HANA server you want to connect to. The example in the following figure uses
SAPHANATestServeron port30015.Optionally, enter a SQL statement from Advanced options. For more information, go to Connect using advanced options.
Select the name of the on-premises data gateway to use for accessing the database.
Note
You must use an on-premises data gateway with this connector, whether your data is local or online.
Choose the authentication kind you want to use to access your data. You also need to enter a username and password.
Note
Currently, Power Query Online only supports Basic authentication.
Select Use Encrypted Connection if you're using any encrypted connection, then choose the SSL crypto provider. If you're not using an encrypted connection, clear Use Encrypted Connection. More information: Enable encryption for SAP HANA
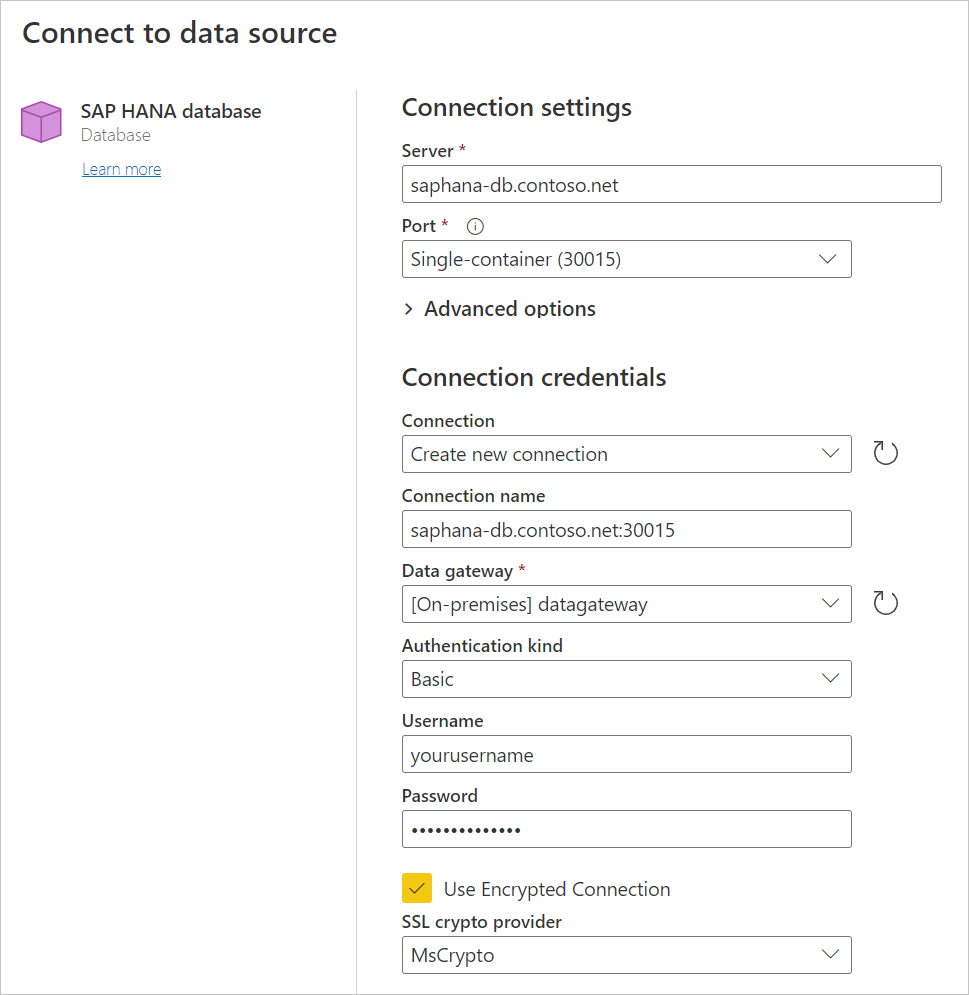
Select Next to continue.
From the Navigator dialog, you can either transform the data in the Power Query editor by selecting Transform Data, or load the data by selecting Load.
Connect using advanced options
Power Query provides a set of advanced options that you can add to your query if needed.
The following table describes all the advanced options you can set in Power Query.
| Advanced option | Description |
|---|---|
| SQL Statement | For more information, go to Import data from a database using native database query. |
| Enable column binding | Binds variables to the columns of a SAP HANA result set when fetching data. Might potentially improve performance at the cost of slightly higher memory utilization. This option is only available in Power Query Desktop. For more information, go to Enable column binding. |
| ConnectionTimeout | A duration that controls how long to wait before abandoning an attempt to make a connection to the server. The default value is 15 seconds. |
| CommandTimeout | A duration that controls how long the server-side query is allowed to run before it's canceled. The default value is 10 minutes. |
Supported features for SAP HANA
The following list shows the supported features for SAP HANA. Not all features listed here are supported in all implementations of the SAP HANA database connector.
Both the Power BI Desktop and Excel connector for an SAP HANA database use the SAP ODBC driver to provide the best user experience.
In Power BI Desktop, SAP HANA supports both DirectQuery and Import options.
Power BI Desktop supports HANA information models, such as Analytic and Calculation Views, and has optimized navigation.
With SAP HANA, you can also use SQL commands in the native database query SQL statement to connect to Row and Column Tables in HANA Catalog tables, which aren't included in the Analytic/Calculation Views provided by the Navigator experience. You can also use the ODBC connector to query these tables.
Power BI Desktop includes Optimized Navigation for HANA Models.
Power BI Desktop supports SAP HANA Variables and Input parameters.
Power BI Desktop supports HDI-container-based Calculation Views.
The SapHana.Database function now supports connection and command timeouts. More information: Connect using advanced options
To access your HDI-container-based Calculation Views in Power BI, ensure that the HANA database users you use with Power BI have permission to access the HDI runtime container that stores the views you want to access. To grant this access, create a Role that allows access to your HDI container. Then assign the role to the HANA database user you use with Power BI. (This user must also have permission to read from the system tables in the _SYS_BI schema, as usual.) Consult the official SAP documentation for detailed instructions on how to create and assign database roles. This SAP blog post might be a good place to start.
There are currently some limitations for HANA variables attached to HDI-based Calculation Views. These limitations are because of errors on the HANA side. First, it isn't possible to apply a HANA variable to a shared column of an HDI-container-based Calculation View. To fix this limitation, upgrade to HANA 2 version 37.02 and onwards or to HANA 2 version 42 and onwards. Second, multi-entry default values for variables and parameters currently don't show up in the Power BI UI. An error in SAP HANA causes this limitation, but SAP hasn't announced a fix yet.
Enable column binding
Data fetched from the data source is returned to the application in variables that the application allocates for this purpose. Before this action can be taken, the application must associate, or bind, these variables to the columns of the result set; conceptually, this process is the same as binding application variables to statement parameters. When the application binds a variable to a result set column, it describes that variable - address, data type, and so on - to the driver. The driver stores this information in the structure it maintains for that statement and uses the information to return the value from the column when the row is fetched.
Currently, when you use Power Query Desktop to connect to an SAP HANA database, you can select the Enable column binding advanced option to enable column binding.
You can also enable column binding in existing queries or in queries used in Power Query Online by manually adding the EnableColumnBinding option to the connection in the Power Query formula bar or advanced editor. For example:
SapHana.Database("myserver:30015", [Implementation = "2.0", EnableColumnBinding = true]),
There are limitations associated with manually adding the EnableColumnBinding option:
- Enable column binding works in both Import and DirectQuery mode. However, retrofitting an existing DirectQuery query to use this advanced option isn't possible. Instead, a new query must be created for this feature to work correctly.
- In SAP HANA Server version 2.0 or later, column binding is all or nothing. If some columns can't be bound, none are bound, and the user receives an exception, for example,
DataSource.Error: Column MEASURE_UNIQUE_NAME of type VARCHAR cannot be bound (20002 > 16384). - SAP HANA version 1.0 servers don't always report correct column lengths. In this context,
EnableColumnBindingallows for partial column binding. For some queries, this partial binding could mean that no columns are bound. When no columns are bound, no performance benefits are gained.
Native query support in the SAP HANA database connector
The Power Query SAP HANA database connector supports native queries. For information about how to use native queries in Power Query, go to Import data from a database using native database query.
Query folding on native queries
The Power Query SAP HANA database connector now supports query folding on native queries. More information: Query folding on native queries
Note
In the Power Query SAP HANA database connector, native queries don't support duplicate column names when EnableFolding is set to true.
Parameters in native queries
The Power Query SAP HANA database connector now supports parameters in native queries. You can specify parameters in native queries by using the Value.NativeQuery syntax.
Unlike other connectors, the SAP HANA database connector supports EnableFolding = True and specifying parameters at the same time.
To use parameters in a query, you place question marks (?) in your code as placeholders. To specify the parameter, you use the SqlType text value and a value for that SqlType in Value. Value can be any M value, but must be assigned to the value of the specified SqlType.
There are multiple ways of specifying parameters:
Providing just the values as a list:
{ "Seattle", 1, #datetime(2022, 5, 27, 17, 43, 7) }Providing the values and the type as a list:
{ [ SqlType = "CHAR", Value = "M" ], [ SqlType = "BINARY", Value = Binary.FromText("AKvN", BinaryEncoding.Base64) ], [ SqlType = "DATE", Value = #date(2022, 5, 27) ] }Mix and match the two:
{ "Seattle", 1, [ SqlType = "SECONDDATE", Value = #datetime(2022, 5, 27, 17, 43, 7) ] }
SqlType follows the standard type names defined by SAP HANA. For example, the following list contains the most common types used:
- BIGINT
- BINARY
- BOOLEAN
- CHAR
- DATE
- DECIMAL
- DOUBLE
- INTEGER
- NVARCHAR
- SECONDDATE
- SHORTTEXT
- SMALLDECIMAL
- SMALLINT
- TIME
- TIMESTAMP
- VARBINARY
- VARCHAR
The following example demonstrates how to provide a list of parameter values.
[!code-powerquery-m[Main](list-of-values.m?highlight=9,12,13)]
The following example demonstrates how to provide a list of records (or mix values and records):
[!code-powerquery-m[Main](list-of-records.m?highlight=10-14,22-26,28)]
Support for dynamic attributes
The way in which the SAP HANA database connector treats calculated columns is improved. The SAP HANA database connector is a "cube" connector, and there are some sets of operations (add items, collapse columns, and so on) that happen in "cube" space. This cube space is exhibited in the Power Query Desktop and Power Query Online user interface by the "cube" icon that replaces the more common "table" icon.
Before, when you added a table column (or another transformation that internally adds a column), the query would "drop out of cube space," and all operations would be done at a table level. At some point, this drop out could cause the query to stop folding. Performing cube operations after adding a column was no longer possible.
With this change, the added columns are treated as dynamic attributes within the cube. Having the query remain in cube space for this operation has the advantage of letting you continue using cube operations even after adding columns.
Note
This new functionality is only available when you connect to Calculation Views in SAP HANA Server version 2.0 or higher.
The following sample query takes advantage of this new capability. In the past, you would get a "the value is not a cube" exception when applying Cube.CollapseAndRemoveColumns.
let
Source = SapHana.Database(“someserver:someport”, [Implementation="2.0"]),
Contents = Source{[Name="Contents"]}[Data],
SHINE_CORE_SCHEMA.sap.hana.democontent.epm.models = Contents{[Name="SHINE_CORE_SCHEMA.sap.hana.democontent.epm.models"]}[Data],
PURCHASE_ORDERS1 = SHINE_CORE_SCHEMA.sap.hana.democontent.epm.models{[Name="PURCHASE_ORDERS"]}[Data],
#"Added Items" = Cube.Transform(PURCHASE_ORDERS1,
{
{Cube.AddAndExpandDimensionColumn, "[PURCHASE_ORDERS]", {"[HISTORY_CREATEDAT].[HISTORY_CREATEDAT].Attribute", "[Product_TypeCode].[Product_TypeCode].Attribute", "[Supplier_Country].[Supplier_Country].Attribute"}, {"HISTORY_CREATEDAT", "Product_TypeCode", "Supplier_Country"}},
{Cube.AddMeasureColumn, "Product_Price", "[Measures].[Product_Price]"}
}),
#"Inserted Year" = Table.AddColumn(#"Added Items", "Year", each Date.Year([HISTORY_CREATEDAT]), Int64.Type),
#"Filtered Rows" = Table.SelectRows(#"Inserted Year", each ([Product_TypeCode] = "PR")),
#"Added Conditional Column" = Table.AddColumn(#"Filtered Rows", "Region", each if [Supplier_Country] = "US" then "North America" else if [Supplier_Country] = "CA" then "North America" else if [Supplier_Country] = "MX" then "North America" else "Rest of world"),
#"Filtered Rows1" = Table.SelectRows(#"Added Conditional Column", each ([Region] = "North America")),
#"Collapsed and Removed Columns" = Cube.CollapseAndRemoveColumns(#"Filtered Rows1", {"HISTORY_CREATEDAT", "Product_TypeCode"})
in
#"Collapsed and Removed Columns"
Limitations
The following limitations apply to the Power Query SAP HANA database connector.
Connect to SAP HANA database over proxy
The SAP HANA database connector doesn't support connecting to cloud database through proxy. To work around, use the ODBC connector instead and specify the proxy settings in DSN or connection string.
Related content
The following articles contain more information that you might find useful when connecting to an SAP HANA debase.