Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
If the dataflow you're developing is getting bigger and more complex, here are some things you can do to improve on your original design.
Break it into multiple dataflows
Don't do everything in one dataflow. Not only does a single, complex dataflow make the data transformation process longer, it also makes it harder to understand and reuse the dataflow. Breaking your dataflow into multiple dataflows can be done by separating tables in different dataflows, or even one table into multiple dataflows. You can use the concept of a computed table or linked table to build part of the transformation in one dataflow, and reuse it in other dataflows.
Split data transformation dataflows from staging/extraction dataflows
Having some dataflows just for extracting data (that is, staging dataflows) and others just for transforming data is helpful not only for creating a multilayered architecture, it's also helpful for reducing the complexity of dataflows. Some steps just extract data from the data source, such as get data, navigation, and data type changes. By separating the staging dataflows and transformation dataflows, you make your dataflows simpler to develop.
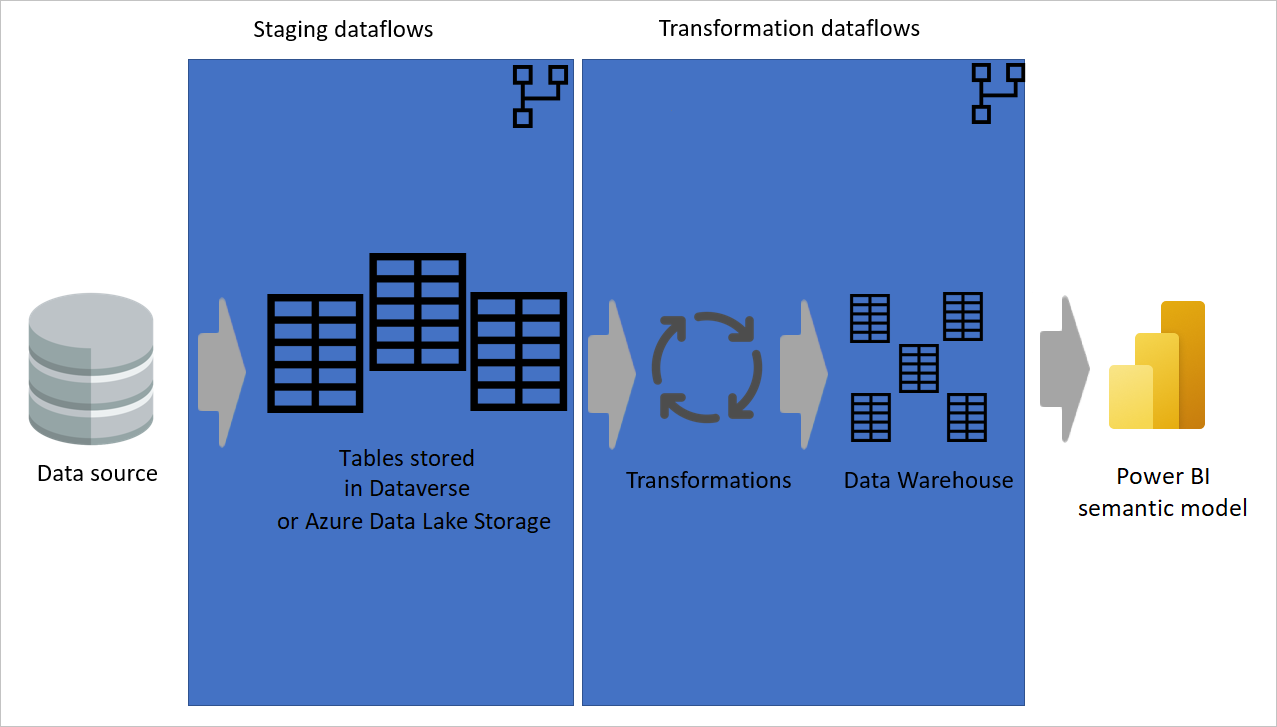
Image showing data being extracted from a data source to staging dataflows, where the tables are either stored in Dataverse or Azure Data Lake storage. Then the data is moved to transformation dataflows where the data is transformed and converted to the data warehouse structure. Then the data is moved to the semantic model.
Use custom functions
Custom functions are helpful in scenarios where a certain number of steps have to be done for a number of queries from different sources. Custom functions can be developed through the graphical interface in Power Query Editor or by using an M script. Functions can be reused in a dataflow in as many tables as needed.
Having a custom function helps by having only a single version of the source code, so you don't have to duplicate the code. As a result, maintaining the Power Query transformation logic and the whole dataflow is much easier. For more information, go to the following blog post: Custom Functions Made Easy in Power BI Desktop.
Note
Sometimes you might receive a notification that tells you a premium capacity is required to refresh a dataflow with a custom function. You can ignore this message and reopen the dataflow editor. This usually solves your problem unless your function refers to a "load enabled" query.
Place queries into folders
Using folders for queries helps to group related queries together. When developing the dataflow, spend a little more time to arrange queries in folders that make sense. Using this approach, you can find queries more easily in the future and maintaining the code is much easier.
Use computed tables
Computed tables not only make your dataflow more understandable, they also provide better performance. When you use a computed table, the other tables referenced from it are getting data from an "already-processed-and-stored" table. The transformation is much simpler and faster.
Take advantage of the enhanced compute engine
For dataflows developed in Power BI admin portal, ensure that you make use of the enhanced compute engine by performing joins and filter transformations first in a computed table before doing other types of transformations.
Break many steps into multiple queries
It's hard to keep track of a large number of steps in one table. Instead, you should break a large number of steps into multiple tables. You can use Enable Load for other queries and disable them if they're intermediate queries, and only load the final table through the dataflow. When you have multiple queries with smaller steps in each, it's easier to use the dependency diagram and track each query for further investigation, rather than digging into hundreds of steps in one query.
Add properties for queries and steps
Documentation is the key to having easy-to-maintain code. In Power Query, you can add properties to the tables and also to steps. The text that you add in the properties shows up as a tooltip when you hover over that query or step. This documentation helps you maintain your model in the future. With a glance at a table or step, you can understand what's happening there, rather than rethinking and remembering what you've done in that step.
Ensure that capacity is in the same region
Dataflows don't currently support multiple countries or regions. The Premium capacity must be in the same region as your Power BI tenant.
Separate on-premises sources from cloud sources
We recommend that you create a separate dataflow for each type of source, such as on-premises, cloud, SQL Server, Spark, and Dynamics 365. Separating dataflows by source type facilitates quick troubleshooting and avoids internal limits when you refresh your dataflows.
Separate dataflows based on the scheduled refresh required for tables
If you have a sales transaction table that gets updated in the source system every hour and you have a product-mapping table that gets updated every week, break these two tables into two dataflows with different data refresh schedules.
Avoid scheduling refresh for linked tables in the same workspace
If you're regularly being locked out of your dataflows that contain linked tables, it might be caused by a corresponding, dependent dataflow in the same workspace that's locked during dataflow refresh. Such locking provides transactional accuracy and ensures that both dataflows are successfully refreshed, but it can block you from editing.
If you set up a separate schedule for the linked dataflow, dataflows can be refreshed unnecessarily and block you from editing the dataflow. There are two recommendations to avoid this problem:
- Don't set a refresh schedule for a linked dataflow in the same workspace as the source dataflow.
- If you want to configure a refresh schedule separately and want to avoid the locking behavior, move the dataflow to a separate workspace.