Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Machine Learning Studio (classic)
Machine Learning Studio (classic)  Azure Machine Learning
Azure Machine Learning
Important
Support for Machine Learning Studio (classic) will end on 31 August 2024. We recommend you transition to Azure Machine Learning by that date.
Beginning 1 December 2021, you will not be able to create new Machine Learning Studio (classic) resources. Through 31 August 2024, you can continue to use the existing Machine Learning Studio (classic) resources.
- See information on moving machine learning projects from ML Studio (classic) to Azure Machine Learning.
- Learn more about Azure Machine Learning
ML Studio (classic) documentation is being retired and may not be updated in the future.
In this tutorial, you take an extended look at the process of developing a predictive analytics solution. You develop a simple model in Machine Learning Studio (classic). You then deploy the model as a Machine Learning web service. This deployed model can make predictions using new data. This tutorial is part three of a three-part tutorial series.
Suppose you need to predict an individual's credit risk based on the information they gave on a credit application.
Credit risk assessment is a complex problem, but this tutorial will simplify it a bit. You'll use it as an example of how you can create a predictive analytics solution using Machine Learning Studio (classic). You'll use Machine Learning Studio (classic) and a Machine Learning web service for this solution.
In this three-part tutorial, you start with publicly available credit risk data. You then develop and train a predictive model. Finally you deploy the model as a web service.
In part one of the tutorial, you created a Machine Learning Studio (classic) workspace, uploaded data, and created an experiment.
In part two of the tutorial, you trained and evaluated models.
In this part of the tutorial you:
- Prepare for deployment
- Deploy the web service
- Test the web service
- Manage the web service
- Access the web service
Prerequisites
Complete part two of the tutorial.
Prepare for deployment
To give others a chance to use the predictive model you've developed in this tutorial, you can deploy it as a web service on Azure.
Up to this point you've been experimenting with training our model. But the deployed service is no longer going to do training - it's going to generate new predictions by scoring the user's input based on our model. So we're going to do some preparation to convert this experiment from a training experiment to a predictive experiment.
Preparation for deployment is a three-step process:
- Remove one of the models
- Convert the training experiment you've created into a predictive experiment
- Deploy the predictive experiment as a web service
Remove one of the models
First, you need to trim this experiment down a little. you currently have two different models in the experiment, but you only want to use one model when you deploy this as a web service.
Let's say you've decided that the boosted tree model performed better than the SVM model. So the first thing to do is remove the Two-Class Support Vector Machine module and the modules that were used for training it. You may want to make a copy of the experiment first by clicking Save As at the bottom of the experiment canvas.
you need to delete the following modules:
- Two-Class Support Vector Machine
- Train Model and Score Model modules that were connected to it
- Normalize Data (both of them)
- Evaluate Model (because we're finished evaluating the models)
Select each module and press the Delete key, or right-click the module and select Delete.
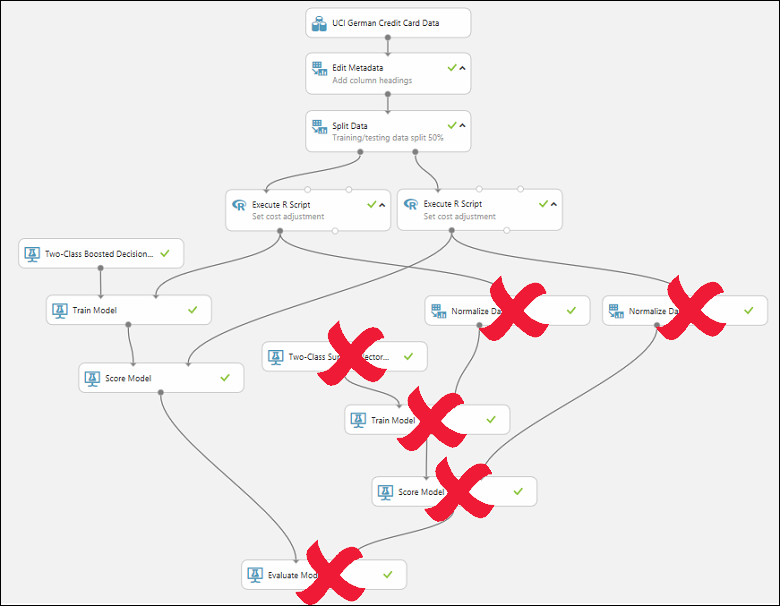
Our model should now look something like this:
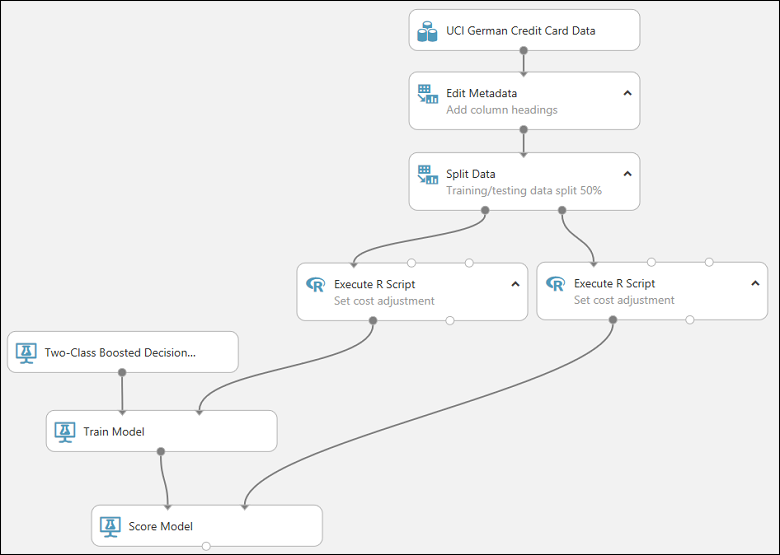
Now we're ready to deploy this model using the Two-Class Boosted Decision Tree.
Convert the training experiment to a predictive experiment
To get this model ready for deployment, you need to convert this training experiment to a predictive experiment. This involves three steps:
- Save the model you've trained and then replace our training modules
- Trim the experiment to remove modules that were only needed for training
- Define where the web service will accept input and where it generates the output
you could do this manually, but fortunately all three steps can be accomplished by clicking Set Up Web Service at the bottom of the experiment canvas (and selecting the Predictive Web Service option).
Tip
If you want more details on what happens when you convert a training experiment to a predictive experiment, see How to prepare your model for deployment in Machine Learning Studio (classic).
When you click Set Up Web Service, several things happen:
- The trained model is converted to a single Trained Model module and stored in the module palette to the left of the experiment canvas (you can find it under Trained Models)
- Modules that were used for training are removed; specifically:
- Two-Class Boosted Decision Tree
- Train Model
- Split Data
- the second Execute R Script module that was used for test data
- The saved trained model is added back into the experiment
- Web service input and Web service output modules are added (these identify where the user's data will enter the model, and what data is returned, when the web service is accessed)
Note
You can see that the experiment is saved in two parts under tabs that have been added at the top of the experiment canvas. The original training experiment is under the tab Training experiment, and the newly created predictive experiment is under Predictive experiment. The predictive experiment is the one you'll deploy as a web service.
you need to take one additional step with this particular experiment. you added two Execute R Script modules to provide a weighting function to the data. That was just a trick you needed for training and testing, so you can take out those modules in the final model. Machine Learning Studio (classic) removed one Execute R Script module when it removed the Split module. Now you can remove the other and connect Metadata Editor directly to Score Model.
Our experiment should now look like this:
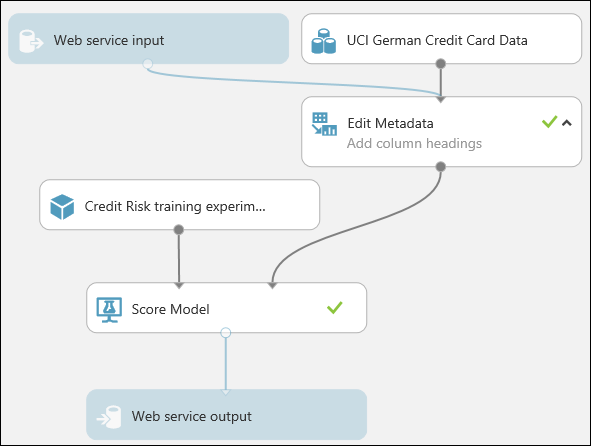
Note
You may be wondering why you left the UCI German Credit Card Data dataset in the predictive experiment. The service is going to score the user's data, not the original dataset, so why leave the original dataset in the model?
It's true that the service doesn't need the original credit card data. But it does need the schema for that data, which includes information such as how many columns there are and which columns are numeric. This schema information is necessary to interpret the user's data. you leave these components connected so that the scoring module has the dataset schema when the service is running. The data isn't used, just the schema.
One important thing to note is that if your original dataset contained the label, then the expected schema from the web input will also expect a column with the label! A way around this is to remove the label, and any other data that was in the training dataset, but will not be in the web inputs, before connecting the web input and training dataset into a common module.
Run the experiment one last time (click Run.) If you want to verify that the model is still working, click the output of the Score Model module and select View Results. You can see that the original data is displayed, along with the credit risk value ("Scored Labels") and the scoring probability value ("Scored Probabilities".)
Deploy the web service
You can deploy the experiment as either a Classic web service, or as a New web service that's based on Azure Resource Manager.
Deploy as a Classic web service
To deploy a Classic web service derived from our experiment, click Deploy Web Service below the canvas and select Deploy Web Service [Classic]. Machine Learning Studio (classic) deploys the experiment as a web service and takes you to the dashboard for that web service. From this page, you can return to the experiment (View snapshot or View latest) and run a simple test of the web service (see Test the web service below). There is also information here for creating applications that can access the web service (more on that in the next step of this tutorial).
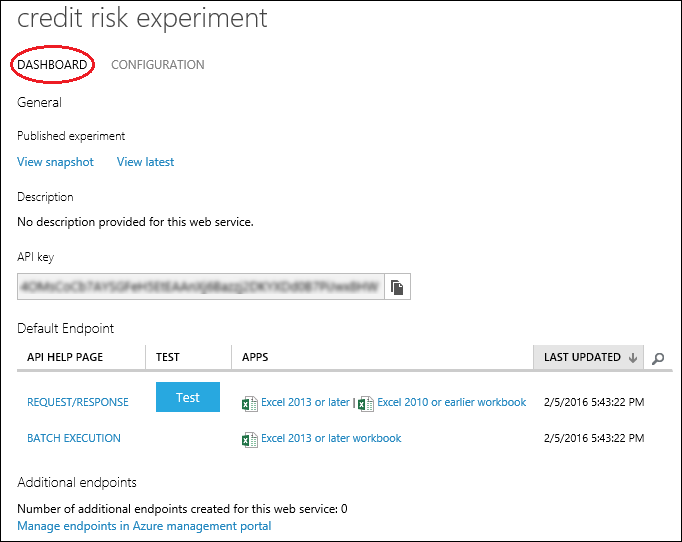
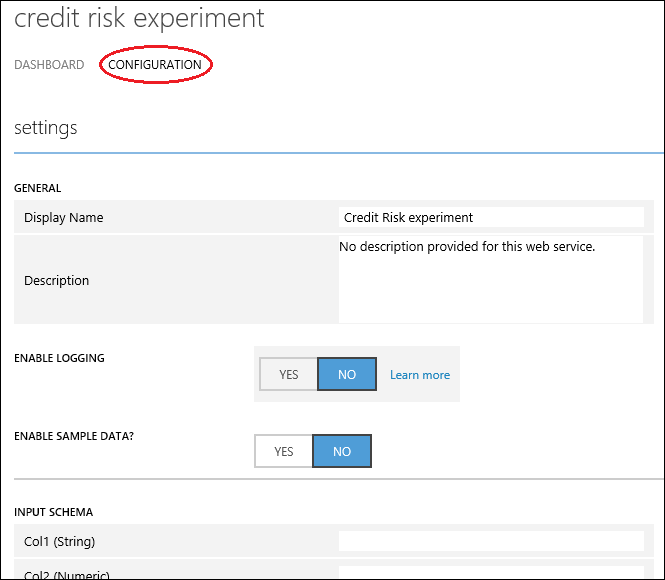
You can configure the service by clicking the CONFIGURATION tab. Here you can modify the service name (it's given the experiment name by default) and give it a description. You can also give more friendly labels for the input and output data.
Deploy as a New web service
Note
To deploy a New web service you must have sufficient permissions in the subscription to which you are deploying the web service. For more information, see Manage a web service using the Machine Learning Web Services portal.
To deploy a New web service derived from our experiment:
Click Deploy Web Service below the canvas and select Deploy Web Service [New]. Machine Learning Studio (classic) transfers you to the Machine Learning web services Deploy Experiment page.
Enter a name for the web service.
For Price Plan, you can select an existing pricing plan, or select "Create new" and give the new plan a name and select the monthly plan option. The plan tiers default to the plans for your default region and your web service is deployed to that region.
Click Deploy.
After a few minutes, the Quickstart page for your web service opens.
You can configure the service by clicking the Configure tab. Here you can modify the service title and give it a description.
To test the web service, click the Test tab (see Test the web service below). For information on creating applications that can access the web service, click the Consume tab (the next step in this tutorial will go into more detail).
Tip
You can update the web service after you've deployed it. For example, if you want to change your model, then you can edit the training experiment, tweak the model parameters, and click Deploy Web Service, selecting Deploy Web Service [Classic] or Deploy Web Service [New]. When you deploy the experiment again, it replaces the web service, now using your updated model.
Test the web service
When the web service is accessed, the user's data enters through the Web service input module where it's passed to the Score Model module and scored. The way you've set up the predictive experiment, the model expects data in the same format as the original credit risk dataset. The results are returned to the user from the web service through the Web service output module.
Tip
The way you have the predictive experiment configured, the entire results from the Score Model module are returned. This includes all the input data plus the credit risk value and the scoring probability. But you can return something different if you want - for example, you could return just the credit risk value. To do this, insert a Select Columns module between Score Model and the Web service output to eliminate columns you don't want the web service to return.
You can test a Classic web service either in Machine Learning Studio (classic) or in the Azure Machine Learning Web Services portal. You can test a New web service only in the Machine Learning Web Services portal.
Tip
When testing in the Machine Learning Web Services portal, you can have the portal create sample data that you can use to test the Request-Response service. On the Configure page, select "Yes" for Sample Data Enabled?. When you open the Request-Response tab on the Test page, the portal fills in sample data taken from the original credit risk dataset.
Test a Classic web service
You can test a Classic web service in Machine Learning Studio (classic) or in the Machine Learning Web Services portal.
Test in Machine Learning Studio (classic)
On the DASHBOARD page for the web service, click the Test button under Default Endpoint. A dialog pops up and asks you for the input data for the service. These are the same columns that appeared in the original credit risk dataset.
Enter a set of data and then click OK.
Test in the Machine Learning Web Services portal
On the DASHBOARD page for the web service, click the Test preview link under Default Endpoint. The test page in the Machine Learning Web Services portal for the web service endpoint opens and asks you for the input data for the service. These are the same columns that appeared in the original credit risk dataset.
Click Test Request-Response.
Test a New web service
You can test a New web service only in the Machine Learning Web Services portal.
In the Machine Learning Web Services portal, click Test at the top of the page. The Test page opens and you can input data for the service. The input fields displayed correspond to the columns that appeared in the original credit risk dataset.
Enter a set of data and then click Test Request-Response.
The results of the test are displayed on the right-hand side of the page in the output column.
Manage the web service
Once you've deployed your web service, whether Classic or New, you can manage it from the Machine Learning Web Services portal.
To monitor the performance of your web service:
- Sign in to the Machine Learning Web Services portal
- Click Web services
- Click your web service
- Click the Dashboard
Access the web service
In the previous step in this tutorial, you deployed a web service that uses your credit risk prediction model. Now users are able to send data to it and receive results.
The Web service is an Azure web service that can receive and return data using REST APIs in one of two ways:
- Request/Response - The user sends one or more rows of credit data to the service by using an HTTP protocol, and the service responds with one or more sets of results.
- Batch Execution - The user stores one or more rows of credit data in an Azure blob and then sends the blob location to the service. The service scores all the rows of data in the input blob, stores the results in another blob, and returns the URL of that container.
Note
Feature column names in Studio (classic) are case sensitive. Make sure your input data for invoking the web service has the same column names as in the training dataset.
For more information on accessing and consuming the web service, see Consume a Machine Learning Web service with a web app template.
Clean up resources
If you no longer need the resources you created using this article, delete them to avoid incurring any charges. Learn how in the article, Export and delete in-product user data.
Next steps
In this tutorial, you completed these steps:
- Prepare for deployment
- Deploy the web service
- Test the web service
- Manage the web service
- Access the web service
You can also develop a custom application to access the web service using starter code provided for you in R, C#, and Python programming languages.