Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Important
Support for Machine Learning Studio (classic) will end on 31 August 2024. We recommend you transition to Azure Machine Learning by that date.
Beginning 1 December 2021, you will not be able to create new Machine Learning Studio (classic) resources. Through 31 August 2024, you can continue to use the existing Machine Learning Studio (classic) resources.
- See information on moving machine learning projects from ML Studio (classic) to Azure Machine Learning.
- Learn more about Azure Machine Learning.
ML Studio (classic) documentation is being retired and may not be updated in the future.
Converts text data to integer encoded features using the Vowpal Wabbit library
Category: Text Analytics
Note
Applies to: Machine Learning Studio (classic) only
Similar drag-and-drop modules are available in Azure Machine Learning designer.
Module overview
This article describes how to use the Feature Hashing module in Machine Learning Studio (classic), to transform a stream of English text into a set of features represented as integers. You can then pass this hashed feature set to a machine learning algorithm to train a text analysis model.
The feature hashing functionality provided in this module is based on the Vowpal Wabbit framework. For more information, see Train Vowpal Wabbit 7-4 Model or Train Vowpal Wabbit 7-10 Model.
More about feature hashing
Feature hashing works by converting unique tokens into integers. It operates on the exact strings that you provide as input and does not perform any linguistic analysis or preprocessing.
For example, take a set of simple sentences like these, followed by a sentiment score. Assume that you want to use this text to build a model.
| USERTEXT | SENTIMENT |
|---|---|
| I loved this book | 3 |
| I hated this book | 1 |
| This book was great | 3 |
| I love books | 2 |
Internally, the Feature Hashing module creates a dictionary of n-grams. For example, the list of bigrams for this dataset would be something like this:
| TERM (bigrams) | FREQUENCY |
|---|---|
| This book | 3 |
| I loved | 1 |
| I hated | 1 |
| I love | 1 |
You can control the size of the n-grams by using the N-grams property. If you choose bigrams, unigrams are also computed. Thus, the dictionary would also include single terms like these:
| Term (unigrams) | FREQUENCY |
|---|---|
| book | 3 |
| I | 3 |
| books | 1 |
| was | 1 |
After the dictionary has been built, the Feature Hashing module converts the dictionary terms into hash values, and computes whether a feature was used in each case. For each row of text data, the module outputs a set of columns, one column for each hashed feature.
For example, after hashing, the feature columns might look something like this:
| Rating | Hashing feature 1 | Hashing feature 2 | Hashing feature 3 |
|---|---|---|---|
| 4 | 1 | 1 | 0 |
| 5 | 0 | 0 | 0 |
- If the value in the column is 0, the row did not contains the hashed feature.
- If the value is 1, the row did contain the feature.
The advantage of using feature hashing is that you can represent text documents of variable-length as numeric feature vectors of equal-length, and achieve dimensionality reduction. In contrast, if you tried to use the text column for training as is, it would be treated as a categorical feature column, with many, many distinct values.
Having the outputs as numeric also makes it possible to use many different machine learning methods with the data, including classification, clustering, or information retrieval. Because lookup operations can use integer hashes rather than string comparisons, getting the feature weights is also much faster.
How to configure Feature Hashing
Add the Feature Hashing module to your experiment in Studio (classic).
Connect the dataset that contains the text you want to analyze.
Tip
Because feature hashing does not perform lexical operations such as stemming or truncation, you can sometimes get better results by doing text preprocessing before applying feature hashing. For suggestions, see the Best practices and Technical notes sections.
For Target columns, select those text columns that you want to convert to hashed features.
The columns must be the string data type, and must be marked as a Feature column.
If you choose multiple text columns to use as inputs, it can have a huge effect on feature dimensionality. For example, if a 10-bit hash is used for a single text column, the output contains 1024 columns. If a 10-bit hash is used for two text columns, the output contains 2048 columns.
Note
By default, Studio (classic) marks most text columns as features, so if you select all text columns, you might get too many columns, including many that are not actually free text. Use the Clear feature option in Edit Metadata to prevent other text columns from being hashed.
Use Hashing bitsize to specify the number of bits to use when creating the hash table.
The default bit size is 10. For many problems, this value is more than adequate, but whether suffices for your data depends on the size of the n-grams vocabulary in the training text. With a large vocabulary, more space might be needed to avoid collisions.
We recommend that you try using a different number of bits for this parameter, and evaluate the performance of the machine learning solution.
For N-grams, type a number that defines the maximum length of the n-grams to add to the training dictionary. An n-gram is a sequence of n words, treated as a unique unit.
N-grams = 1: Unigrams, or single words.
N-grams = 2: Bigrams, or two-word sequences, plus unigrams.
N-grams = 3: Trigrams, or three-word sequences, plus bigrams and unigrams.
Run the experiment.
Results
After processing is complete, the module outputs a transformed dataset in which the original text column has been converted to multiple columns, each representing a feature in the text. Depending on how big the dictionary is, the resulting dataset can be extremely large:
| Column name 1 | Column type 2 |
|---|---|
| USERTEXT | Original data column |
| SENTIMENT | Original data column |
| USERTEXT - Hashing feature 1 | Hashed feature column |
| USERTEXT - Hashing feature 2 | Hashed feature column |
| USERTEXT - Hashing feature n | Hashed feature column |
| USERTEXT - Hashing feature 1024 | Hashed feature column |
After you have created the transformed dataset, you can use it as the input to the Train Model module, together with a good classification model, such as Two-Class Support Vector Machine.
Best practices
Some best practices that you can use while modeling text data are demonstrated in the following diagram representing an experiment
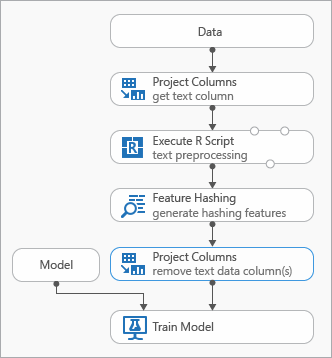
You might need to add an Execute R Script module before using Feature Hashing, in order to preprocess the input text. With R script, you also have the flexibility to use custom vocabularies or custom transformations.
You should add a Select Columns in Dataset module after the Feature Hashing module to remove the text columns from the output data set. You do not need the text columns after the hashing features have been generated.
Alternatively, you can use the Edit Metadata module to clear the feature attribute from the text column.
Also consider using these text preprocessing options, to simplify results and improve accuracy:
- word breaking
- stop word removal
- case normalization
- removal of punctuation and special characters
- stemming.
The optimal set of preprocessing methods to apply in any individual solution depends on domain, vocabulary, and business need. We recommend that you experiment with your data to see which custom text processing methods are most effective.
Examples
For examples of how feature hashing is used for text analytics, see the Azure AI Gallery:
News Categorization: Uses feature hashing to classify articles into a predefined list of categories.
Similar Companies: Uses the text of Wikipedia articles to categorize companies.
Text Classification: This five-part sample uses text from Twitter messages to perform sentiment analysis.
Technical notes
This section contains implementation details, tips, and answers to frequently asked questions.
Tip
In addition to using feature hashing, you might want to use other methods to extract features from text. For example:
- Use the Preprocess Text module to remove artifacts such as spelling errors, or to simplify text preparatory to hashing.
- Use Extract Key Phrases to use natural language processing to extract phrases.
- Use Named Entity Recognition to identify important entities.
Machine Learning Studio (classic) provides a Text Classification template that guides you through using the Feature Hashing module for feature extraction.
Implementation details
The Feature Hashing module uses a fast machine learning framework called Vowpal Wabbit that hashes feature words into in-memory indexes, using a popular open source hash function called murmurhash3. This hash function is a non-cryptographic hashing algorithm that maps text inputs to integers, and is popular because it performs well in a random distribution of keys. Unlike cryptographic hash functions, it can be easily reversed by an adversary, so that it is unsuitable for cryptographic purposes.
The purpose of hashing is to convert variable-length text documents into equal-length numeric feature vectors, to support dimensionality reduction and make the lookup of feature weights faster.
Each hashing feature represents one or more n-gram text features (unigrams or individual words, bi-grams, tri-grams, etc.), depending on the number of bits (represented as k) and on the number of n-grams specified as parameters. It projects feature names to the machine architecture unsigned word using the murmurhash v3 (32-bit only) algorithm which then is AND-ed with (2^k)-1. That is, the hashed value is projected down to the first k lower-order bits, and the remaining bits are zeroed out. If the specified number of bits is 14, the hash table can hold 214-1 (or 16,383) entries.
For many problems, the default hash table (bitsize = 10) is more than adequate; however, depending on the size of the n-grams vocabulary in the training text, more space might be needed to avoid collisions. We recommend that you try using a different number of bits for the Hashing bitsize parameter, and evaluate the performance of the machine learning solution.
Expected inputs
| Name | Type | Description |
|---|---|---|
| Dataset | Data Table | Input dataset |
Module parameters
| Name | Range | Type | Default | Description |
|---|---|---|---|---|
| Target columns | Any | ColumnSelection | StringFeature | Choose the columns to which hashing will be applied. |
| Hashing bitsize | [1;31] | Integer | 10 | Type the number of bits to use when hashing the selected columns |
| N-grams | [0;10] | Integer | 2 | Specify the number of N-grams generated during hashing. By default, both unigrams and bigrams are extracted |
Outputs
| Name | Type | Description |
|---|---|---|
| Transformed dataset | Data Table | Output dataset with hashed columns |
Exceptions
| Exception | Description |
|---|---|
| Error 0001 | Exception occurs if one or more specified columns of data set couldn't be found. |
| Error 0003 | Exception occurs if one or more of inputs are null or empty. |
| Error 0004 | Exception occurs if parameter is less than or equal to specific value. |
| Error 0017 | Exception occurs if one or more specified columns have type unsupported by current module. |
For a list of errors specific to Studio (classic) modules, see Machine Learning Error codes.
For a list of API exceptions, see Machine Learning REST API Error Codes.